Anyone working in scholarly communication knows the tension at the heart of our current system. Research has become increasingly collaborative, computational, and global, and the outputs that make modern science actually work — data, code, protocols, methods — are multiplying in scope and importance. At the same time, the structures through which we communicate, evaluate, and fund research remain stubbornly anchored to the logic of print: the journal article as the dominant unit of recognition, peer review as the primary quality signal, and article processing charges (APCs) as the dominant mechanism for funding open access.

This misalignment isn’t new, and many organizations — DORA, CoARA, cOAlition S, and a number of research funders, to name but a few — have all been pressing on it for years. But I’d argue that solving this misalignment has become all the more urgent due to a number of factors. Artificial Intelligence is accelerating both the promise and the problems, transforming research workflows while creating an acute need for better trust signals, transparency, and machine-readable outputs that our current infrastructure was never designed to provide. Meanwhile, APCs have done important work in making open access mainstream, but they have also become a constraint on further transformation. By tying financial value to the published article, they reinforce exactly the incentive structures that assessment reformers are trying to dismantle.
So, what would it actually take to build a publishing model fit for the research ecosystem we have now, rather than the one we inherited? That’s the core question PLOS set out to explore eighteen months ago, with generous support from the Gordon and Betty Moore Foundation and the Robert Wood Johnson Foundation. Today, we are publishing the public report — Redefining Publishing: Practical pathways to open science — summarizing this work and our findings. We want to share what we learned, not as a PLOS story, but because we believe the implications reach well beyond any single organization.
Two Questions Worth Testing
The project was framed around two connected propositions. First, can publishing better recognize the full range of contributions that make up modern research — not just the article, but the data, code, methods, and materials that underpin it? Second, can publishing business models evolve to support the assessment and sharing of these various outputs as linked components of a continuous research cycle, and grow the number of authors able to participate?
Neither question is original, but we aimed to approach them in a different way, treating these as research and design problems rather than advocacy positions. To achieve this, our work included independent economic analysis, multistakeholder convenings across four thematic areas, and an extensive program of user-centered design research with about 650 researchers across career stages and disciplines. It meant listening to stakeholders across very different research contexts and geographies, and it meant being genuinely willing to be surprised by what we found. The full methodology and findings are in the public report, but I want to draw out what I think matters most for the community.
Openness is Necessary but Not Sufficient
The independent economic analysis, conducted independently by Technopolis Group, confirmed something many of us have suspected but not had clear, documented evidence for at a system level: the strongest economic and societal benefits of open science arise not from openness per se, but from openness that enables practical reuse at scale.
When research outputs — particularly data, code, software, and workflows — are designed and supported for reuse, measurable benefits follow: reduced duplication, shorter research timelines, lower coordination costs, and downstream innovation. But these benefits don’t arise automatically. They depend on shared infrastructure, interoperable systems, underpinned by open standards, clear documentation, aligned incentives, and sustained coordination across stakeholders. Openness without those conditions is a file in a repository that nobody can find, understand, or use.
This has direct implications for how we think about publishing reform. The case for moving beyond the article isn’t just about fairness to researchers whose contributions currently go unrecognized (though it is that too). It’s also an economic argument about where the real value of open science actually lies. The stakes are higher than they might appear. The alternative to well-resourced open infrastructure isn’t a neutral status quo — it’s an ecosystem where the practical value of open science gets captured by vertically integrated services that control access to it.
The Knowledge Stack
Our design work pointed toward what we’re calling a knowledge stack: a publishing model that connects articles and preprints with associated research outputs into a structured, open, machine-readable record that reflects the research process and credits everyone who contributed. (Noting that we’re not the first or only ones to have used the “knowledge stack” terminology!) Crucially, outputs remain where they are most useful, in existing repositories. The knowledge stack provides the structured relationships, attributions, and context that make distributed outputs visible as a coherent whole to help credit, understand, verify, and reuse.
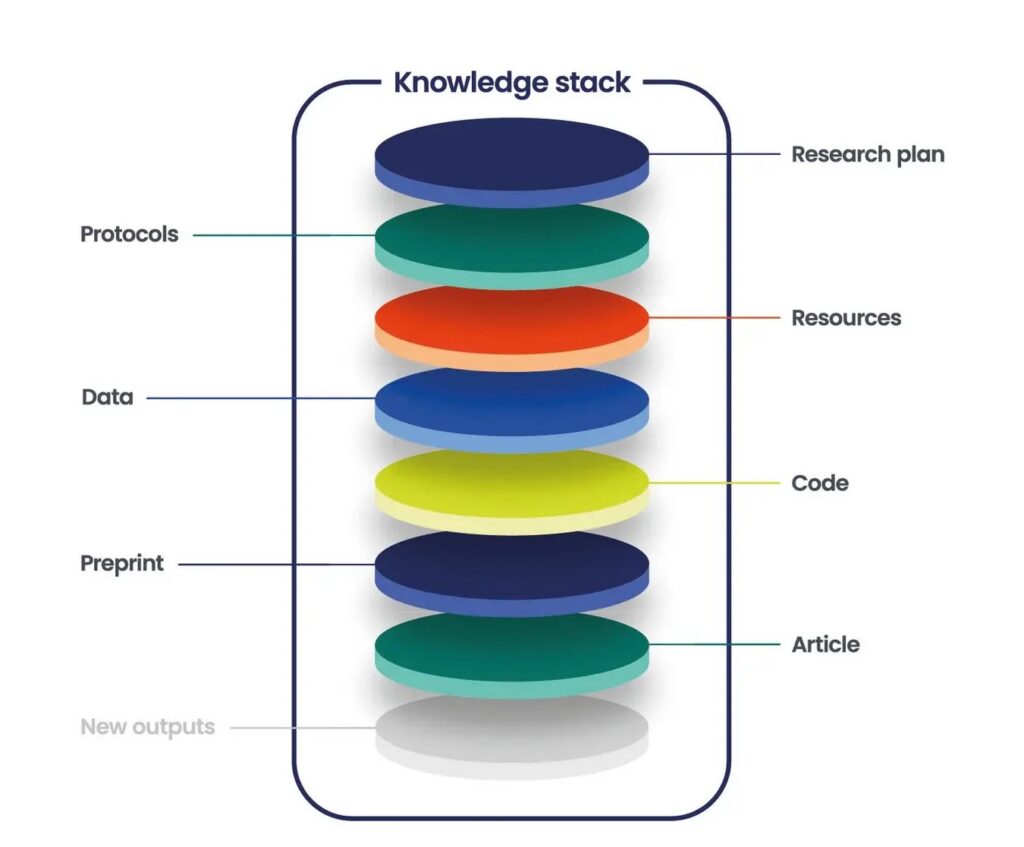
This isn’t a wholesale reimagining of scholarly publishing — in many ways, it’s a practical bridge to the future, and one that the research showed has genuine demand. Researchers want better linking and context to support reuse. Early-career researchers want recognition for contributions that currently go uncounted. Institutions and funders want a more honest and complete picture of research activity. The concept resonated not because it is radical, but because it addresses a real and widely felt gap. In an AI-mediated research environment, this becomes even more pointed. The question isn’t only whether data and code are available, it’s whether machines (and the humans who depend on them) can establish what something is, where it came from, who created or modified it, what it depends on, and what level of confidence should attach to it. The knowledge stack is designed to answer exactly those questions.
Our user research surfaced something particularly useful for anyone designing in this space: researchers engage far more readily with non-article outputs when they are presented in relation to a familiar article structure. Disconnected repository links are routinely ignored, even when the underlying data is well-documented. Context and narrative aren’t decoration — they’re the mechanism through which outputs become usable (at least, this is how they currently become usable — this is likely to evolve as outputs are increasingly read by machines).
Rethinking Quality: The Case for Checkability
One of the findings I find most practically valuable is what we came to call checkability. Full validation of data and code at scale is not feasible. We knew this going in, but the research helped us understand what might actually work instead. What researchers and assessors consistently rely on in practice is not expert verification but rather signals of transparency, completeness, and documentation — signals that tell you whether an output could be meaningfully examined if needed. An output doesn’t need to be validated to be trustworthy; it needs to be transparent enough that trust can be calibrated by the person who needs it.
Checkability reframes the publisher’s role in quality assurance for non-article outputs. Rather than attempting gatekeeping that isn’t credible at scale, publishers can add real value by improving metadata, signaling what checks have been performed, supporting consistent documentation standards, and making quality processes visible. The analogy offered by one participant — that plagiarism detection changed author behavior system-wide once publishers adopted it — suggests the potential leverage here. The analogy is telling: plagiarism detection didn’t just catch bad actors; it changed what authors did in the first place. Checkability could work the same way, and right now, that kind of upstream integrity signal is exactly what the system needs.
Regional Pathways Are Not Optional
Perhaps the finding with the broadest implications (and the one most easily overlooked) is that there is no single pathway to open science that works equally across all contexts. This isn’t a new observation, but our research gave it specificity. Funding structures, procurement routes, repository landscapes, policy maturity, affordability, digital sovereignty, and assessment systems vary significantly across regions. These aren’t implementation details to be sorted out later — they shape whether new models are workable at all. The voices from our Nairobi convening were particularly clear: approaches that require local research systems to adapt to a single predefined model, however well-intentioned, risk reinforcing exactly the inequalities open science is supposed to address.
For publishers, infrastructure providers, and funders designing new models, this means co-development with regional partners isn’t a nice-to-have. It’s a prerequisite for anything that aspires to work at a global scale.
So, What About Business Models?
Running through all of these findings is an unavoidable conclusion about publishing economics. Infrastructure improvements (better metadata, richer attribution, knowledge stacks) are enabling conditions for broader change, but they cannot substitute for reforms in how publishing is funded.
As long as financial value is concentrated on the published article, incentives will follow. Data and code will remain secondary; regional participation will remain constrained by the ability to pay; and the full research record will remain aspirational. Our stakeholders were broadly supportive of exploring models that move beyond per-publication charges, that are transparent and predictable, that reflect regional economic realities, and that align publishing support with a wider range of research outputs and services. There is an appetite for this across libraries, funders, and institutions, and what remains is the harder work of actually testing it.
Where We Go From Here?
For PLOS, the next phase translates these findings into a program of practical experimentation. We’ll focus initial publishing capability development on data and code (identified as the most mature and policy-relevant starting points), developing approaches to attribution, contextual linking, and checkability in practice. We’ll continue to invest in open, shared infrastructure rather than proprietary solutions, including our ongoing contribution to the Janeway platform. And we’ll keep working on business model alternatives, building on experiments we’ve been running since 2020.
But the more important point is the one this project kept coming back to: no single organization can solve these problems. The knowledge stack depends on interoperability across systems. Assessment reform depends on funders and institutions, not publishers alone. Regional equity depends on co-development, not the export of Northern models. Business model transformation depends on collective willingness to experiment and share what we learn.
What this project has reinforced, for me, is that meaningful progress is possible — but only if it is genuinely collaborative. We’ve tried to model that in how we conducted this research, and in publishing these findings openly. I hope others will build on them, challenge them, and add to them.

Discussion
9 Thoughts on "Beyond the Article, Beyond the APC: What We Learned from 18 Months of R&D"
Thanks for writing this article, Alison. It is very forward-looking and certainly a step in the right direction for the times we are in, with increasing research integrity challenges and the growing role of AI-mediated discovery, which requires reliable data and richer context.
I see this as a particularly important development because it helps address the fragmentation that currently exists across the scholarly record. Research outputs are often scattered across disconnected components such as preprints, journal articles, peer review reports, and, increasingly, open peer review. The Knowledge Stack appears to bring these elements together into a more complete and connected picture of the scholarly record, one that is better suited to supporting transparency, provenance, and research integrity.
I look forward to seeing PLOS implement and further develop this important initiative.
Thanks so much for this thoughtful response, Ashutosh – you’ve put your finger on exactly why the fragmentation problem feels so urgent right now. The combination of AI-mediated discovery and growing integrity challenges creates a real inflection point: the moment when “nice to have” richer, connected context becomes genuinely necessary infrastructure.
For a long time, the goal of a researcher was to write their paper and get it to a high impact journal (for validation, dissemination, establishing precedence, building reputation, etc.). It sounds like this post is pointing to the disaggregation of that model. Perhaps the unbundling of the “Things Journal Publishers Do” – https://scholarlykitchen.sspnet.org/2018/02/06/focusing-value-102-things-journal-publishers-2018-update/
Alison, do you think this is an emerging trend in author expectations or are you documenting the current expectations that just aren’t well understood, yet?
Great question, Jeff (and apologies for the slow reply but I was offline for much of last week!).
In response to your question, I’d actually say it’s both, but in different proportions depending on where you sit. Among early career researchers especially, we found genuine and current appetite for recognition of contributions that go well beyond the article – this isn’t aspirational for them, it’s a felt frustration with the present. At the same time, the broader expectation that the journal article remains the primary unit of career value is still very much intact, with the result that many researchers want broader recognition while rationally continuing to focus on the metric that actually moves their career forward. And yes, there are those who are simply focused on publishing in the highest impact journal they can get accepted into.
I think we’re documenting a real and present tension more than a clean emerging trend (and one that’s been building for years). Whether it tips into genuine disaggregation of the journal bundle depends less on author expectations than on whether funders and institutions move meaningfully on assessment.
Thanks for sharing this excellent research, Alison! I find the concept of “checkability” extremely compelling – feasible to implement for both publishers and reviewers, and yet a strong deterrent for misconduct. It’s one of the most practical and effective proposals I’ve heard! Looking forward to reading the full report.
I agree with Stephanie Lovegrove Hansen. Thanks for adding “checkability” into the lexicon as both a word and a concept. This is a great path. I worry (as you note) that a combination of publishing economics (this sounds expensive) and — more critically– author incentives will present a high hurdle. As long as tenure and grants are based on the article, we publishers might not have the power to change author behavior in a way to make this a reality. Negativity aside, it would be great if we can advance this.
Thanks Roy and Stephanie for picking up on this aspect (and apologies for the slow reply – I was offline for much of last week).
Really glad “checkability” landed as a useful concept – that’s exactly what we were hoping for, something actionable enough to actually change behavior rather than just describe an aspiration.
And Roy, the skepticism is entirely fair and healthy (though I’m not sure this needs to be expensive – that will depend on the design). The plagiarism detection analogy is instructive precisely because the leverage came from making a new norm visible and expected, not from comprehensive verification – and the cost was modest relative to the behavioral change it drove.
A question on the Knowledge Stack – does it include the assessment* of the constituent parts? Surely the future has to see mandated open (published, at least) review and assessment if we are truly to turn around trust not only in science but in those who publish it?
*I’m avoiding saying peer review given who much the future points to at the very least AI-supported assessment and review.
Great question, Nathaniel – and yes, I’d agree both that some level of “assessment” is essential, and that transparency is important. The knowledge stack is designed to make the full provenance and context of research outputs visible and structured, and that absolutely includes surfacing what assessment or review has taken place and by whom. We deliberately framed this around transparency and documentation rather than prescribing a single review model, precisely because – as you note – the landscape is shifting fast and “peer review” as a fixed concept is already dissolving at the edges. We’re not clear exactly what this looks like for non-article outputs – we’ll be looking at this more closely for data and code in this next phase of work.



