Editor’s note: Today’s post is by Laura Harvey and Adam Hyde. Laura is a consultant working with publishers and vendors, and Adam is the founder of Pure Science, Inc.
Over the last two weeks, purepub.ai pulled together 47 speakers across 15 sessions on AI in publishing workflows. The level of engagement was itself a data point: over 800 live attendees and hundreds of chat-thread discussions. This topic is top of mind for publishing operators, and it’s not just theoretical. Far from it.
In this post, we’re going to break down some of the main themes and trends which emerged across the event. Where better to start than a knowledge graph? This one represents concepts and topics from the sessions and gives a flavor of where the conversations clustered (also see this interactive version).
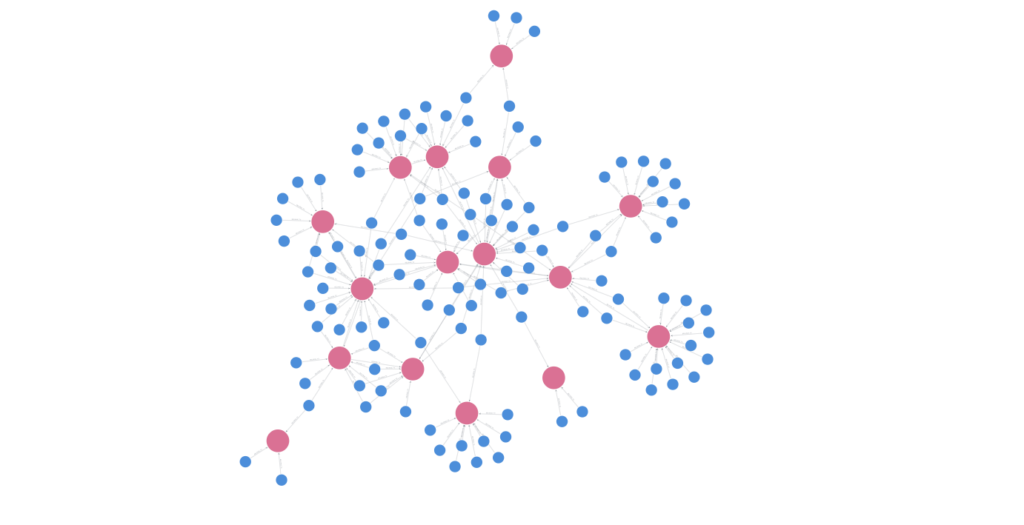
There are few surprises in the concepts which dominated: “Business-model-and-market-evolution,” “Machine-as-consumer,” “Front-door-editorial-triage,” and “Workflow-transformation” sat at the top. Themes with the most uniformly positive sentiment included “Workflow-transformation,” “format-evolution,” and, perhaps surprisingly, “Organizational-and-resource-readiness”.
Business model evolution — the dominant theme by far — drew a wider spread, from excitement to caution, which is what you would expect of a topic that is shorthand for “things are changing, and we don’t know how they will land or who will still be here.” The topic was largely driven by machines-as-content-consumers, although the submission volume crisis and the shift toward community-centric publishing also drove the conversation.
“All publishers will eventually have some kind of AI gateway. They will not be sending AI agents down their human website. It’s super inefficient, and it’s not a good point of control.” — Todd Toler, Group VP of Product & Market Strategy at Wiley
The Agentic AI Shift Has Happened
It is an established pattern that we first use new technology to do what we already do faster and cheaper, then to do it better, and only then to do it differently. As McLuhan put it, “We march backwards into the future.”
Taking the 60+ use cases mentioned across the conference as a microcosm of publishing workflows, the pattern appears to hold.
Most use cases identified were nuts-and-bolts automations and enhancements focused on single pain points and driving efficiency. Editorial led the way with AI-enhanced workflows for finding reviewers, screening for paper mills and technical checks, though format conversion and metadata enrichment were also well represented. These examples could be categorized as the “faster and cheaper” layer, and it is large and maturing.
At the next stage were smaller-scale experiments in the value-enhancement space, which we could see as “doing things better”, and even “doing things differently.” Researcher-facing tools were prominent here, ASCO’s Guidelines Assistant and Springer Nature’s Nature Research Assistant being two notable examples. Publishers experimenting with bespoke in-house technical check tools made up another visible cohort, with audio alt-text proofing and agent-driven peer review workflows emerging as stand-out examples.
The genuinely different ideas — just-in-time computational sandboxes and end-user curation filters — remain mostly at the discussion and prototype stage. This matches what the attendees themselves told us: 24 of the 32 polled attendees said their organizations are at an experimental stage on the AI adoption curve, with deployment and scale yet to come.
AI reviewers proved a useful bellwether for how fast a publishing conversation can move. The consensus from panelists was that frontier models, given the right harness, are broadly good enough for academic peer review right now. In a few short years, the question has migrated from “can AI peer review?” to “which parts of the peer review process should AI be doing?” The topic is an interesting case study in the cultural and logistical factors at play in technological transformation, and the question remains: how long will it take for AI to diffuse into peer review operations?
Human Value Moves to Taste, Judgement, and Responsibility
AI and peer review also delivered one of the most useful framings of how humans and AI might work together in the future.
“Humans and AI actually optimize for different things. Humans devote more comments to contribution, clarity, and elements that require taste and scientific judgment. AI reviewers tend to focus on technical verification, like validity, sufficiency, and transparency. Ultimately I think they have very complementary roles.” — Natalie Khalil, CEO & Co-Founder at Reviewer3
This angle sees peer review as decomposable into two distinct parts: specific technical checks falling to AI agents (statistical, methodological, and research integrity checks), and matters of taste and judgement remain firmly with humans (novelty, appropriateness, and validating the right research questions).
This theme was extended across discussions about community building, trust and governance. Accountability, taste, judgement, and relationships were all singled out as the preserve of humans within publishing workflows, raising an uncomfortable question: what does it mean for jobs?
There was a clear consensus on the need for human oversight and accountability when AI is doing the work, but real concerns emerged over the joy of said role. Jeff Lang of Figure2 put it best: “What human wants to be the AI babysitter?”
On the flip side, vibe coding deserves a special mention. Thirteen vibe-coded prototypes were featured across the program — approximately one-fifth of all use cases were presented to a fanfare of enthusiasm and audience participation. In addition to this excitement, the range of panelist backgrounds stood out: we heard from marketing, product, tech, operations, and editorial experts taking problem-solving into their own hands. Solutions ranged from news feed managers and manuscript transfer dashboards to a platform which could allow authors to audio-proof alt-text for images.
Sam Parker described vibe coding as “a narrative tool” — something in the hands of subject-matter experts to communicate what they actually want. Publishing organizations appear to be catching on: across both vibe coding sessions, 34 of the 64 polled recipients indicated support for vibe coding within their organizations.
Trust & Community Are Your Moats, Infrastructure is Your Leverage
Humans will continue to hold accountability, and with it trust in scholarly workflows. They will also hold relationships with readers and users. These shared predictions saw publisher brand and community emerge as a defensible moat.
We heard about publishers looking “off platform” for brand touchpoints with researchers, and about the rising premium on trusted curation in a world where content generation is commodified.
“We’re in a world of increased volume of content. The things that act as really good filters become more valuable in that world. Journals do that” — Ian Mulvany, Chief Technology Officer, BMJ Group
The conference also got into the specifics of what trust and governance might actually look like on the ground: author identification, open data, programmatic guardrails, provenance markers, and accountability frameworks.
Another factor emerged, one that would give publishers the most leverage over the machines entering their workflows: infrastructure. Infrastructure (and data) were the least shiny but perhaps most crucial emerging theme from the whole event. The agentic shift is happening, but there are barriers to effective adoption, and the most consequential is not the model.
“When we talk about an AI agent, it’s about 5% model and 95% workflow engineering” — Hong Zhou, VP of Product Management at KnowledgeWorks Global Ltd.
That engineering glue Hong references is everything around the model, your business context, and the technical engineering that allows agents to access your (siloed and sometimes API-less) systems and data. Others touched on the data aspect, highlighting how crucial structured, accessible data will be in leveraging AI.
“My thinking has shifted — it’s not really about getting chatbots in the hands of users; it’s about getting data in the hands of chatbots.” — Andrew Smeall, VP, Product Innovation at Sage
We heard from large publishers looking at ground-up AI-native platforms, and from smaller societies trying to pilot point-solution tools within existing publishing infrastructure. In the knowledge graph in Figure 2, infrastructure sits tightly coupled to three other concepts — core-ai-capabilities-and-architectures, machine-as-consumer, and organizational- and resource-readiness.
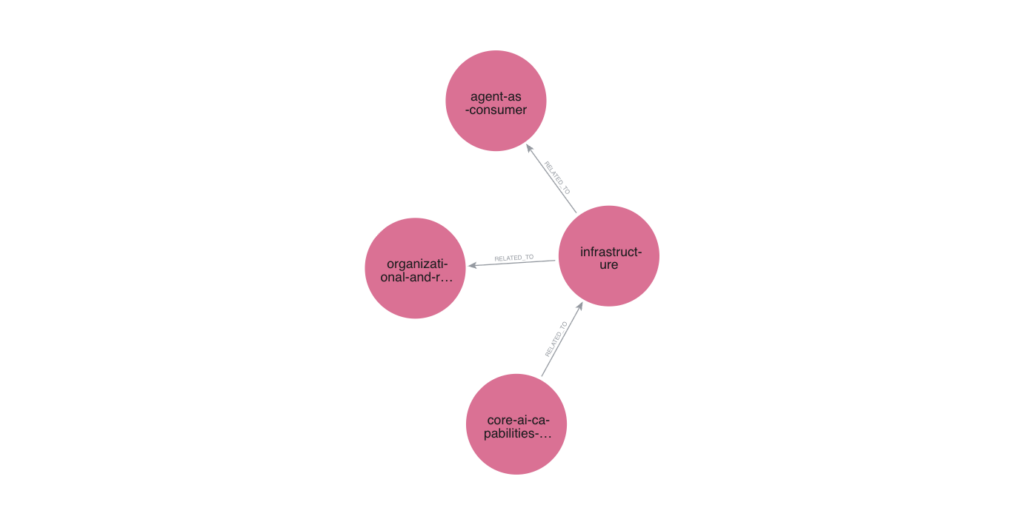
That cluster is informative. It tells us that infrastructure in this sector is partly a technical problem (legacy architectures in a fast-changing environment), partly a data problem, and partly a change-management problem.
That is not an easy square to circle, but it is where the durable advantage will accrue. The two moats reinforce each other: infrastructure will let publishers truly leverage machines, while brand and community are what will keep them meaningful to humans.
What Next?
The field will have new entrants, for one thing.
We asked the attendees of a session called “Journal 2030” whether major AI technology players will move into the scholarly content market by 2030. The answer was a resounding yes by 23 of 30 polled participants.
So, what will publishing workflows look like in 2030? The directional bets coming out of PurePub.ai look something like this:
- agents will be fully embedded within workflows;
- human roles will still be there but more concentrated around matters of accountability, taste, judgement and community; and
- the publishers who successfully leverage AI will be the ones who have gotten on top of infrastructure.
If your own organization is sitting somewhere on that experimental-to-operational arc, how does our take match what you’re seeing? The comments are open.
Authors’ note: We compiled an article structure of bullet points and narrative excerpts and then used Claude to build this into essay form as an initial draft. This was extensively revised, validated and sent to colleagues for feedback before publication. Claude was used in the construction of the knowledge graph featured in this article to extract nodes and edges from transcripts of 15 sessions. These were then validated and consolidated before the final graph was constructed.



