Editor’s note: Julie Zhu is Manager of Discovery Service Relations for IEEE, “the world’s largest organization dedicated to advancing technology for humanity”. She works with internal teams, library service and search engine providers, libraries, and other parties to make the IEEE content more discoverable, linkable and accessible from external discovery channels. She has been active in NISO since 2010, currently serving in the Information Discovery & Interchange Topic Committee, ODI Standing Committee and KBART Automation Working Group.
Information discovery and access is often a source of frustration for scholarly information stakeholders. Feeling fed up with the many stumbling blocks in web-scale discovery service tools, some are chasing “new” discovery solutions or supercontinents of scholarly publishing, even though these new solutions may not improve search or retrieval. Believing that web-scale discovery has passed its heyday, some are focusing on authentication products that bypass paywalls. Still, promoting library branding, some librarians are enhancing their own library discovery pages and making content in institutional repositories and archives more discoverable. The landscape of scholarly information interchange is becoming more complex, more fragmented and more siloed.

Wherever researchers start their content discovery, no solution can promise a wonderland where all discovery, linking, authentication and access problems magically disappear. As scholarly communication professionals, we need to demystify and decode the channels of scholarly information discovery and interchange. It may help to imagine these discovery channels as a complex network of content pipelines, connecting various electronic systems, from author research and manuscript submission, to online publishing, syndication, indexing, linking, authentication and much more. Like any plumbing system, these data pipes can leak, break or be blocked in many possible ways.
For example, authors who format their names incorrectly upon submission, such as not capitalizing, or including math symbols, may find their names left out of search results in Google Scholar. Content pipelines inside a publishing organization may break if one group decides to change the format of one data element, a column in a database table, or a simple workflow without informing other groups. External content feed pipelines may break if FTP transfer fails on either the sending or the receiving side, without triggering a warning. Content pipelines may be blocked when a discovery service vendor does not index received content in a timely way, maps content incorrectly, fails to provide a link, or produces a broken OpenURL link. The largest blockages may come from libraries that inadvertently turn off the faucets, by not enabling the correct collections in a discovery index, not selecting the correct title list targets in a link resolver knowledge base, or not putting the discovery tool or databases under proxy for off-campus users.
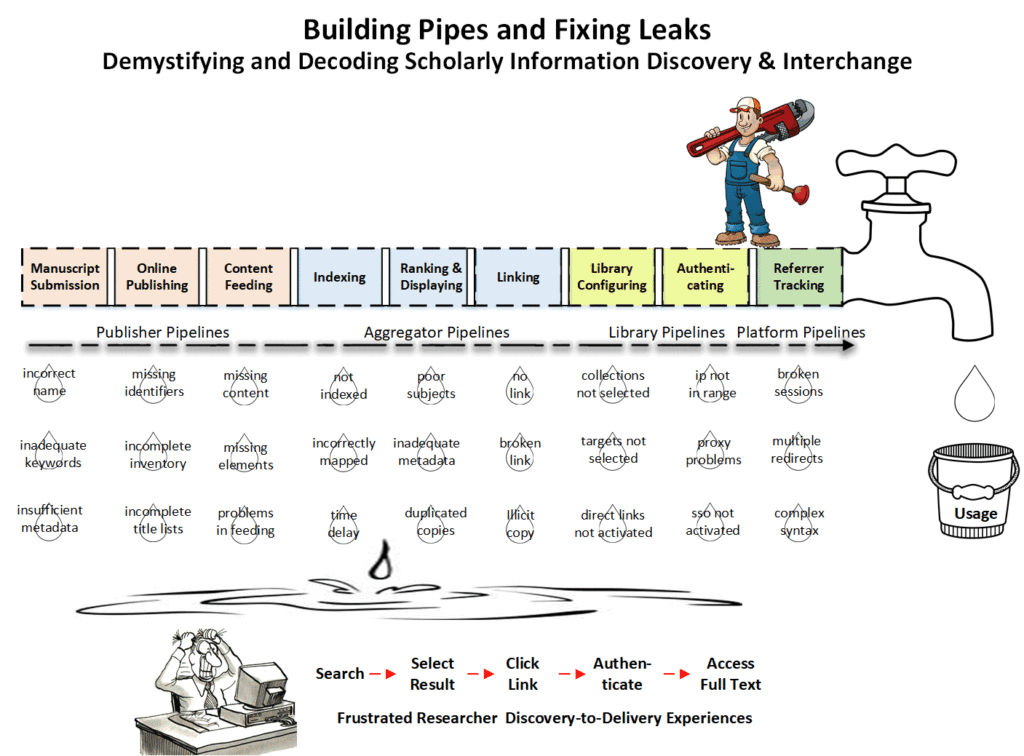
Stakeholders in the scholarly information content supply chain need to design and build effective content pipelines to find and fix content leaks, breaks and blockages. NISO’s Open Discovery Initiative (ODI) is a committee of librarians, content providers and discovery service representatives dedicated to enhancing scholarly information discovery through greater collaboration across the community. ODI engages all parties in the discovery chain, for web-scale discovery services like EDS, Primo, Summon and WorldCat Discovery, to ensure transparency and freedom of choice through rich metadata inclusion, resource interoperability, statistical consistency, and link customization and optimization.
In 2018 ODI published The ODI Implementation Guide for Content Providers, to help content providers conform to the ODI Recommendations issued in 2014. As a checklist developed out of “Should publishers work with library discovery technologies and what can they do?”, the Implementation Guide is a roadmap to help content providers detect and fix discovery-related problems. Although the focus is on web-scale discovery tools, the methodologies can be used for other search channels as well. The following sections summarize recommendations from the Implementation Guide and provide examples on how content providers, discovery service providers and libraries are working together to build better content pipelines and fix leaks.
- Dedicate resources towards content discovery
ODI recommends content providers allocate resources to content discovery, based on the organization’s needs and resource availability. They can designate a discovery service lead to coordinate internal team projects and manage external relationships with vendors, libraries and other industry stakeholders. They can form a cross-functional discovery task force, including members from content and technical units that create content, manage databases, deliver syndicated content, and develop software, as well as from business units that interface with library customers, manage online platforms, and create analytic reports. Since not all the staff are customer-facing or understand the importance of discovery and the downstream complications, it is important to secure cross-divisional management buy-in, for projects like improving internal data quality and flows, complying with industry best practices and collaborating with vendors and libraries. Communication is a key component, internally and externally.
In 2013, IEEE assembled a three-person team to look for problems in discovery services, work with vendors and create discovery service and knowledge base configuration guides for libraries. After determining that distributing this work across multiple teams and people wasn’t effective or efficient, IEEE created a position of a dedicated Discovery Service Relations Manager in June 2014. The remit was to conduct deeper analyses of the problems, create roadmaps for overall improvements and coordinate internal and external resources for resolving issues. In 2015, with support from the IEEE management, a nine-person Discovery Service Working Group was formed, to communicate regularly on detected issues, ongoing projects and ways to collaborate with vendors and library customers.
More publishers, of various types, sizes and focuses, are devising ways to allocate resources to content discovery. Since 2015 at least eight publishers have created job titles including the word “Discovery.” The publishers are Gale, SAGE, Oxford University Press, Emerald, Springer Nature, Bloomsbury, SAE International and IOP Publishing. In dozens of other organizations, such as Wiley, Cambridge University Press, Taylor and Francis and SPIE, staff, mostly in the departments of Product Management, Marketing, Sales and Library Support, have volunteered to take on extra responsibilities on content discovery. Lacking internal expertise, some publishers hire consultants to carve out a content discovery strategy before creating a dedicated position.
- Assess content gaps and leaks
ODI advises that content providers conduct some testing for the discovery, linking and authentication of their content in the major discovery service tools and decide whether further systematic investigations are warranted. “Collaborating to Reduce Content Gaps in Discovery” demonstrates how IEEE assesses content gaps in the syndication feeds delivered to indexing partners, the indices of four major discovery service tools and twenty-four library configurations of the discovery tools. It also analyzes the causes of those gaps and suggests ways to close them.
Some other publishers have started systematically assessing content gaps and leaks. Oxford University Press is investigating content gaps for several key products and trying to learn more about how content types are categorized across discovery services. Emerald Group Publishing regularly audits major discovery indices to spot systematic issues affecting coverage and monitors web traffic from different library discovery services to detect service-wide issues affecting multiple customers.
It is understandable that each publisher needs to find its own ways to assess content gaps and leaks, because each may have its unique content types, metadata challenges, workflows and connections to discovery tools and library systems. It is also an ongoing process, as new content and collections continue to be added to publishing platforms and syndications. To refine content discovery and retrieval techniques, publishers may need to collaborate internally, as well as externally with discovery, link resolver and authentication tool vendors and mutual customers that deploy them.
- Improve workflows and conform to industry best practices
ODI encourages content providers to improve data quality and workflows and conform to industry recommended best practices, such as ODI, KBART II and ALI. Conforming to industry recommendations is no easy task. Content providers may find that they need to do remediation work on improving metadata quality, assembling needed metadata elements, increasing content inventory and even changing workflows. These projects can be complex, time-consuming, costly and may prove difficult to demonstrate immediate return on investments. It is important to keep educating publishing staff about industry best practices, secure cross-divisional management buy-in and find ways to show value for work on discovery-related issues.
In June 2015, Credo, Gale, IEEE and SAGE were the first four publishers to declare conformance with NISO’s Open Discovery Initiative. Since then five more have completed ODI Conformance Statements. ODI encourages more content providers to declare ODI conformance. In “A brief history of the Open Discovery Initiative,” Rachel Kessler, Co-chair of ODI, assures content providers that the goal of ODI is transparency, not perfection. Declaring conformance means that the “organization is honest and forthcoming” and is making plans “to improve upon the areas where they are not yet perfect.” This ODI implementation guide for content providers also intends to help content providers, as well as other stakeholder parties, to overcome some of the hurdles.
- Collaborate with library service providers
Content providers may develop working relationships with each of the major discovery service, link resolver, authentication product and search engine vendors and set up regular meetings or other channels of communications. The collaborations can cover a wide range of topics, such as assessing content gaps, delivering content feeds, indexing new content, filling in missing content, improving results ranking, setting up link resolver targets, creating MARC Records, improving authentication, diagnosing usage reports, creating and updating configuration guides, resolving mutual customer issues and more.
Several discovery service providers have dedicated staff to working with publishers to ensure publisher content is best represented in their services. EBSCO has opted to create more EDS Partner Databases and, to increase global reach, has made the EDS Partner Database Questionnaire available in 11 languages. EBSCO Discovery Service – Publisher Guides lists links to EBSCO Discovery Service Quick Reference Guides and Full Text Finder Quick Reference Guides for over a dozen publishers. Proquest’s Publisher Relations Engagement Managers are having regular conference calls with several dozen publishers, often scheduling several calls a day. The calls cover a wide range of topics. Abigail Wickes, Senior Library Discovery and Information Analyst of Oxford University Press, finds these relationships with discovery partners “have been incredibly valuable and have allowed OUP and discovery partners to be much more collaborative in troubleshooting and supporting linking and access.”
- Work with libraries
ODI proposes that content providers interact more with libraries and understand the librarian roles, functions, tools and workflows. Content providers can develop systematic ways to track, troubleshoot and respond to library inquiries about discovery, linking and access problems. They can also proactively detect, resolve and prevent discovery related problems through creating and promoting system configuration guides, conducting discovery auditing and training support staff and librarians on discovery troubleshooting.
Since 2015, IEEE staff have conducted discovery workshops in UK, Ireland, Germany and Austria, created technology profiles for hundreds of library accounts, audited discovery and link resolver configurations for subscribed IEEE Xplore content by over 1,000 libraries and reached out to librarians to help make corrections. Dominic Benson, Analytics & Discovery Officer at Brunel University London, attended an IEEE discovery workshop in 2015 and found it very useful in identifying missing IEEE holdings. He has used IEEE’s auditing approach to improve his library’s overall holdings in the knowledge base. He appreciates IEEE’s including proactive discovery auditing as part of the post-sale support service and considers library-publisher relationship one of the key factors when considering renewals.
We need your help!
Building effective content pipelines and fixing leaks to ensure better scholarly information discovery and interchange is not easy. It takes patience, persistence, and perspiration.
- It asks organizations to develop a culture that appreciates data quality and flows and be willing to invest in resources and initiatives that will benefit information interchange downstream that will result in improved researcher experiences;
- It calls for collaborations among stakeholders along the content supply chain, i.e., publishers, vendors and libraries, to design better architecture for electronic systems, tools, platforms and content pipelines; and
- It requires stakeholders to do better data plumbing, i.e., developing better routines to check for defects and fix leaks.
We invite more organizations and individuals to join the efforts to improve scholarly information discovery and interchange. We encourage you to participate in NISO’s standards development activities and utilize NISO resources such as those published on the NISO ODI website. We invite publisher discovery leads to join Google Group for Content Discovery Managers, to network with colleagues facing similar challenges.
ODI Standing Committee is working on a new set of working items to help make content more transparent and discoverable in web-scale discovery services:
- Address needs of A&I service providers
- Identify sources of records in the discovery interfaces
- Identify additional metadata and content elements
- Handle open access content
- Define and protect fair linking
- Disclose content coverage at collection and title levels
- Provide more meaningful discovery usage statistics
- Recommend library best practices
For information gathering, the committee has designed surveys for the three stakeholder groups: libraries, content providers, and discovery service providers. Please participate in these surveys to ensure the revised recommended practice reflects current discovery practices. The surveys will be available until July 19, 2019. You can preview the survey questions using the PDF linked on the survey welcome screen.
- Content Provider Survey – https://www.surveymonkey.com/r/odi-contentprovider
- Discovery Provider Survey – https://www.surveymonkey.com/r/odi-discoveryprovider
- Library Survey – https://www.surveymonkey.com/r/odi-library
We hope to hear from you!
Julie Zhu would like to thank Abigail Wickes, Lola Estelle, Michael Roberts, Dominic Benson and Benjamin Johnson for responding to my questionnaires and sharing their insights. I appreciate helpful feedback from Marjorie Hlava, Scott Bernier, Prakash Bellur and Tiffany McKerahan. Special thanks go to Lettie Conrad for guiding and supporting this article throughout its multiple iterations.
Discussion
6 Thoughts on "Guest Post — Building Pipes and Fixing Leaks: Demystifying and Decoding Scholarly Information Discovery & Interchange"
This is such a good overview of the challenges involved in content discovery management, especially the point that it’s an ongoing process as new content and collections continue to be added. Establishing relationships with discovery services and adhering to industry standards are so crucial, and the metaphor for this data flow as a pipeline with many potential fault points is very apt. Thank you Julie!
Thank you, Julie, for this post and putting so many great resource links out to our community.
I often think of some of the stats and comments from this Guardian article from 2018 – https://www.theguardian.com/higher-education-network/2018/may/21/scientists-access-journals-researcher-article
“It takes an average of 15 clicks for a researcher to find and access a journal article”
While some of the comments from researchers are mixed on that 15-click number, it does seem clear that the barriers to discovery are pushing people (who could legitimatly access) to places like Sc*-H*b.
This post has prompted our company to get involved in ODI. We continue to refine our solution for this issue: DCL Discovery Bridge.
I think your #1 point of dedicated resources is spot on. Are there any organizations who have a CDO? Chief Discovery Officer
Marianne: You asked a good question.
The title Chief Discovery Officer does exist in some law and product development organizations: https://www.lawsitesblog.com/2015/04/a-new-title-in-the-biglaw-c-suite-chief-discovery-officer.html.
Libraries found the importance of content discovery quite a few years ago. The University of Brunel London Library has a position of Analytics & Discovery Officer. Many libraries have Directors of Discovery, such as CDL https://www.cdlib.org/cdlinfo/2018/06/21/meet-sarah-houghton-cdls-new-discovery-delivery-director/.
Publishers started creating positions on content discovery only a few years ago. ODI maintains a list of Publisher Contacts for Content Discovery, currently including over thirty contacts: https://www.niso.org/standards-committees/odi/resources-content-providers-discovery-service-providers. All of them are far below the C-level. Most are struggling to do their work because to improve content quality, workflows and discovery, they need support and collaborations from multiple internal departments and groups. Often they have little or no influence over many of these groups, and some organizations do not have enough infrastructure to support cross-divisional collaborations.
I hope solutions like DCL Discovery Bridge will help some publishers understand the complexities facing content discovery and appreciate the importance of infrastructure support.
I find it odd that the entire discussion of discovery fails to mention brand. Many researchers look to a specific journal to follow developments in their field. This doesn’t mean that they don’t use various discovery tools, but the brand was and is the best search tool that there is. The reason we have all these discovery tools is that the number of publications is enormous, but one very good way to explore something is to follow the guidance of a top-flight editorial team, whose protocols winnow the fields of information.
Joe — Quite right, brand is key for readers — but that is an aspect of the human information experience in content discovery. In my experience, optimizing discovery requires strategic awareness of *both* the human aspects of information experience and computational factors (machine readability, indexing, info architecture). Julie is addressing the later, where metadata supply chains and pipelines are critical. Her intent was not to focus on readers’ information experiences — where, of course, brand is a factor (although, I would argue one aspect yet not the full picture, at least not as I read the info-sci research). Search behavior demonstrates a reliance on the metadata, indexing, and other computational factors that lie behind those ever-popular search engines that (hopefully) point us to the brand we trust. 🙂
Thank you, Joe, for the comment, and Lettie, for the clarification.
I agree that branding is an important part of content discovery. Actually many parties are promoting their brands, including journal editors, publishers, A&I database providers, hosting platforms, libraries, and even various discovery tool vendors. My opening paragraph mentions that some libraries try to promote their “library branding”, for fear of being drowned among so many competing brands.
So a researcher may decide which brands to follow. Most researchers do follow certain journal brands. A top-flight editorial team safeguards the quality of the journal brand and its content. However, the editorial team is not involved in all of the content creation, production, transferring and distribution processes, and not necessarily familiar with the complex pipelines that make discovery, linking, authentication and access possible. The high quality of a journal does not guarantee that its content can always be discovered and accessed by all researchers through all discovery channels.
We agree that nowadays most researchers have to go beyond sticking with several journal brands, because it is not likely for these journals to include all the quality content they need in their fields. If they start their searches from a favored platform, an entrusted database, a leading search engine, or a library home page, they are likely to encounter some of the problems illustrated in the blog article. The longer the content supply chain, the more likelihood for content leakages.
Authors, editors and readers are among the major players in content creation and consumption. But behind the shining brands are the time and toil of numerous “engineers” and “plumbers” working behind the scene in the publishing industry and the library communities to make content discovery possible. I hope that the article will provide more transparency to the content discovery process and contribute toward more understanding among the various parties.



