As publishers, libraries, and technology providers grapple with customer and end-user demands for discovery as well as delivery of scholarly content, we have seen a surge of scientifically minded search engines and browser extensions released in the last year or two. Have these modern discovery tools finally solved our age-old limitations, from metadata to access controls? Can cutting-edge solutions in data science and authentication unite search and retrieval of scholarly literature (outside the library)?
With my doctoral student cap on, I recently test-drove the latest scholarly search tools to see how well they are responding to reader expectations for synchronized discovery and authorized access of full-text publications. When I last explored search options for scholarly readers, it was obvious that innovations are on the rise, but most academic reader needs were yet to be fully satisfied. However, at this time of this writing, the latest in search software still have a ways to go.

The newest entrants in the scientific search market demonstrate that the expected focus on the research workflow has indeed arrived. The focus on user experience is clear and commendable. In particular, we’re seeing a strong drive toward solving access control issues, with several competing options for browser plug-ins to sync with institutional credentials and follow a user across various databases and platforms. In my experience, however, no one has yet cracked the code for connecting discovery to full-text delivery. In fact, after tinkering with various browsers and settings and search criteria, I must confess that the newest entrants in the discovery marketplace have not inspired me to change my workflow.
Before I proceed, dear reader, let me clarify that I am not the average scholarly user. Given my professional background in academic and professional publishing, I take up my own doctoral work with a measure of insight into the sausage-making realities of scholarly communications. However, in my Ph.D. journeys, I have experienced the same tangled-web realities of digital and remote academic pursuits of typical researchers. (Also note: This post does not pretend to emulate the type of rigorous bibliometric or systems testing from other information researchers.)
While working on a doctoral publishing project the other day, polishing the reference list prior to submitting an original article, I needed just a quick citation check — and was quickly reminded of the chaotic information experiences and obstacles in digital research. While fuming about a simple metadata mismatch that cost me 20 minutes of biblio-sleuthing, I began to question my own research practice and citation-search workflow. Usually, I start with my library’s discovery layer or Google Scholar (where I have set up library links). But, maybe I’m stuck in a rut? Perhaps there are newer tools I should be learning and adopting? Might the latest plug-ins be the answer to some of these stumbling blocks? Should I rethink my off-campus approach to content discovery and access?
I decided it was worth a few hours one Sunday to run some discoverability tests, much like those I employ in my professional life. Using one of the known items from my search project a few days prior, I used a heuristic (exploratory) method to compare the results and choose-your-own-adventure pathways offered by several new free / mainstream academic search products. As you’ll see in my results, that conclusion would change dramatically if (when?) my library were to license one or more of the leading solutions for off-campus authentication.
My baseline for this comparative exercise was my successful (albeit sometimes frustrating) library or library-enabled Google Scholar experiences. Although I can expect the occasional embargo period, broken link or indexing error, I have developed a somewhat efficient formula for using the two together as my go-to search starting points. And, as both information professional and information scholar, I have a degree of faith in both my university library’s systems and the Scholar database to surface the most relevant, authoritative, accessible content for my initial search purposes. In this test, a search of my library’s installation of Primo Central located the article in question and offered a handful of access options via a link resolver page. Similarly, the same search on Google Scholar pointed me to the target article and the “Find@” library link sent me to the same link resolver page of institutionally enabled access options.
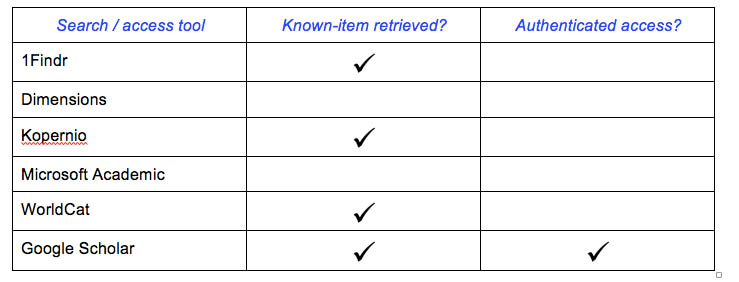
With that benchmark in mind, I began my tests with the newest open-web search tool that week, 1Findr, from the Canadian-based 1Science. Entering the paper’s title, author surname, and publication year into the search bar produced relevant results, including my target article. While the DOI link pointed to the primary publisher site, the bold full-text button took me straight to a PDF of the version of record on the author’s institutional repository. For my citation-checking purposes that day, I trusted the former over the latter, but on the whole I’d say that 1Findr is one to watch.
Using the same query format, I next explored the free version of Dimensions, part of the suite of workflow products from Digital Science. Initially, I expected to find a new STM search engine, but was surprised to see numerous multidisciplinary subject filters across the social sciences. Despite Dimensions’ efforts to be multidisciplinary, however, my target paper was not to be found there. Although were a number of headings within the information sciences, they favored the hard-science-leaning fields of systems design and bibliometrics. From what I’ve seen so far, Dimensions is a promising platform with some pretty sharp tools, in particular to filter and compare various data-points, covering dozens of information needs across the industry. I can imagine I’ll return to Dimensions for other needs, both scholarly and professional. However, for my initial search-and-retrieve trial run, it did not convince me to change my scholarly discovery process.
As an extended point of comparison, I also tried out my citation search with a few other established scholarly info-seeking options. Asking the same query of Microsoft Academic led me to an endless stream of results, none of which included my target article. The same search in the public version of OCLC’s WorldCat also surfaced thousands of results, but the use of quotation marks did the trick and directed me to the article on the publisher’s site. For good measure, I also tried a few new services that I know to be specially designed for biomedicine or other STM fields. As expected, I was unable to locate my target article through MyScienceWork, as I have found in the past with ScienceOpen and Semantic Scholar. Frankly, I did not bother testing my citation with Meta, given the hard-science focus (and the required registration before any searching can be done). So, I nixed these as out of scope for purpose of this test.
I then enlisted help from Kopernio, one of the several new browser extensions that aim to facilitate cross-platform content retrieval leveraging a user’s institutional credentials, recently acquired by Clarivate. After tripping over some bugs and finding the app worked best in Chrome, a new search in Google Scholar led to Kopernio retrieving a version hosted with Academia.edu. I went back to Dimensions and tested 5 other known items in addition to my original target article, but could not successfully link from Dimensions’ free search results to library-enabled full text via Kopernio. Although my library account appeared to be correctly plugged into the app, I saw no indication of successful proxy access and all subsequent test searches led either to pages in ResearchGate, Academia.edu, or directly to PDFs with a kopernio.com address (without indication as to the hosting source). While Kopernio was successful in retrieving the necessary item, thus receiving a check-mark in the table below, the results left me with some doubt regarding the business logic and why the article’s source was being obscured. I wonder if other students would question the authority of the sites often produced by Kopernio searches. I’m guessing this linking behavior will raise flags for publishers and other industry stakeholders as well.
Notably, selecting the Unpaywall app from the preview page of my target article produced a message stating that it “couldn’t find any legal open-access version of this article.” I found this very interesting, especially given the PDFs provided by Kopernio and 1Findr. If my library subscribed to the LeanLibrary or Anywhere Access apps, I’d be curious to see how closely they mirror or surpass the experience with Google Scholar library links — and I’d be hopeful they would generate more check-marks in the access column of the table below. Despite this recent spike in browser extensions that aim to bridge the gaps between mainstream search and institutional access, Google Scholar’s library links have proven the most reliable in getting the job done to date.
On reflection, these latest offerings in scholarly search prove that discovery is no longer enough and we’re seeing full-text access more regularly paired with search indexes. All major players seem equally focused on synching up with authorized institutional access as the ideal scenario, though some are engineering more stringent checks for legitimacy than others. Any scholarly reader searching on the mainstream web is at risk retrieving outdated versions or questionable resources. However, those apps that default to unverified PDFs on sites like Academia.edu or ResearchGate may increase pressure on libraries and content providers to participate in indexing and data-sharing, to increase the likelihood of capturing usage on primary publisher sites. Perhaps this practice will do just the opposite and drive away cross-sector cooperation.
In the latest search technology, discovery workflows are increasingly mobilized, with browser plug-ins catching on as an extended service for platforms to deliver both personalization and access to content across the sectors (including non-academic providers, like DeepDyve). To make this magic happen, dozens of successful linkages must be maintained across all necessary library systems, publisher sites, and intermediary data sources which is a challenge for all service providers, so I acknowledge that performance inconsistencies and bugs are unavoidable. However, I doubt users will see value in a service that does no better than a standard Google search and cannot consistently integrate with off-campus credentials.
Most of these new discovery and access services promote “fast” retrieval in “one click,” which speaks to the motivation to simplify the scholarly user experience. However, the more noble goal may be to strike a balance between quality and convenience, rather than to favor one over the other. Some new providers are prioritizing both authorization and validated versions of record over speed of delivery or convenience — which may cause some uneven user experiences, but are values which are usually well received by publishers and libraries alike. And, ultimately, I believe scholarly users will accept minor delays if they know they are receiving legitimate, citable resources in a way that honors the hard work of the authors behind the research they are reading.
In addition to reliability of content, breadth and coverage of publications may be an even sharper point of the competitive edge in this domain and some may give current giants, like Scopus and Google Scholar, a run for their money. The newest entrants follow suit in our industry’s dominant focus on journals and the discoverability of articles. While I predict ongoing metadata challenges and resulting usage limitations for reference works, book chapters, and videos, some of these new services are extending their reach to all types of content libraries and their users care about. This includes patents, grants, preprints, conference proceedings, OA articles, and institutional repository materials — which hints at new opportunities and/or disruptions for traditional library discovery services.
One takeaway from this exercise is that user priorities for discovery tools are largely subjective and situational. In my test case, I had a specific information need to validate a citation, but these search tools are being designed to attend to many different user practices and purposes. Generally, though, I’m finding that the top priorities for most scientifically oriented searchers are accuracy, coverage (both topical and in publication breadth), access, and reliability / authority. The ease of use and usability of search-result page designs sit alongside these priorities, where services with simple, clear, and familiar information architecture win out every time.
In the end, I decided my search process was just fine — my allegiance remains with my library because they are the one player in this landscape that can both reliably get me to a citable version of a given publication. I (heart) my library — or any service, like Scholar, that works with my library to make my workflow as smooth and successful as possible. I admit this means that I accept lack of personalization and the occasional metadata, proxy access, or other technical issues. And, as my library has invested in Google Scholar’s library links, I trust they will perform due diligence on the newest plug-in options and continue to further support us remote, off-campus students. Together, my library and Google Scholar come closest to Roger Schonfeld’s vision for a scholarly discovery supercontinent.
Acknowledgements: The author wishes to thank Roger Schonfeld, Sara Rouhi, Jason Chabak, Jan Reichelt, and Johan Tilstra for their insights and contributions to this post.

Discussion
23 Thoughts on "The Latest in Search: Do New Discovery Solutions Improve Search as well as Retrieval?"
Frankly I was shocked to learn that Kopernio makes no effort to determine whether the content they are delivering is legal or not. This certainly goes against the approaches of most companies in this field. I suspect that they will be hearing from angry publishers shortly, and unless this policy changes, may find themselves blocked from indexing a significant portion of the literature.
Hi David,
Ben here, one of the Kopernio founders.
Let me assure you that quite the opposite is true! In fact one of the chief motivations behind Kopernio was the difficultly I personally experienced locating authoritative copies of journal articles. This tripped me up during my research, trying to reproduce results from a pre-print with a critical typo that was subsequently corrected before publication.
Kopernio always goes to the publisher first to retrieve the original published journal article (PJA), via the institutional subscription and using the university’s authentication system. This results in a counter-compliant download giving the authenticated user the publisher’s version of record. Research workflows are very fragmented across different online platforms (thousands of which are supported by Kopernio). Kopernio massively increases the reach of subscriptions across these platforms ensuring they are available to researchers at the point of need, and re-routing the user back to the publisher’s version.
Only if the publisher route fails, Kopernio will look for alternative versions that could also be found via Google Scholar for example, so would be retrieved as well by the user via other means. This might be institutional repositories, preprint repositories, but also Scholarly Collaboration Networks. The benefit of using Kopernio is thus that Kopernio always gives preference to the publisher, whilst recognising that other sources are being used by researchers as well. Kopernio is happy to work with publishers to help understand such user behaviour.
In Lettie Conrad’s case (the author), Kopernio delivered freely available versions (i.e. the same as the Google Scholar search) due to a library proxy related issue. We had a couple of email conversations and a video call about this and this is now resolved. Kopernio is still an emerging technology (like all the other tools mentioned), but our data tells a clear story: Kopernio significantly increases downloads back to the publisher version of record – the legitimate, legal version.
We would invite any interested publisher to get in touch with us and we are more than happy to demo to you David so we can correct this miss-information.
Ben
I don’t see any misinformation. You’re essentially saying that if the user doesn’t subscribe or if we don’t make the article free, then it’s okay for you to send the user to an illicitly pirated copy. That if Google Scholar will source an illegal copy of an article, then it’s okay for you to do so as well. But it’s not okay for Google to do this (and many publishers have been discussing this with Google). If your tool is deliberately pointing users to copyright infringing material, then it is not a tool that I personally am willing to support, and I suspect many publishers will feel the same. Note that other similar tools do not include sites where such rampant copyright infringement is the norm. Why don’t you just send the user to Sci-Hub?
David,
Can you explain more about what *should* happen? What would a good tool do, in what order, to prioritize the discovery?
Unpaywall finds open content and does not use Academia.edu or ResearchGate as a source.
The priority should be to get the user to the best available legal version of a paper that they have access to.
I’ll then say the tool should suggest ILL, which is legal. Contacting the author is legal too.
David, what level of certainty are you expecting for “ethical” linking? The studies I have seen show that the majority of copy on RG is licit. And, that was before RG pulled down content after the Coalition lawsuit, the fact that increasingly content being published OA, and publisher partnerships (such as the SNCUPT one I wrote about here on SK). Given all this, isn’t RG hosted content increasingly likely to be licit?
Where does one draw the line? One could argue similarly about Sci-Hub — there’s lots of OA content available there, lots of stuff in the public domain. Why not send the reader there as well? Just because content is from a SNCUPT publisher and hasn’t been taken down yet (remember, the point of that agreement was for RG to help those publishers in their efforts to remove infringing content from the site), it doesn’t mean that it is legally available for redistribution.
And if I was running a company in a crowded, competitive market, and my product required the cooperation of publishers to index the content on their sites and access their servers, then I would probably make every effort to build a cooperative relationship with those same publishers, rather than an antagonistic one. Google may be too big a behemoth for publishers to shut out entirely, but as for the smaller, new discovery tools, none has yet staked a claim to the market lead, and acting against the interests of publishers may put a company at a disadvantage as compared to the many other services that deliberately do not include content delivery from known sources of copyright infringement.
Agreed David – that’s what I am asking you. Where and how do you draw the line? It seems that RG is “over the line” for you. I’m trying to figure out why – on what criteria. Purpose/mission? Any illicit content? Majority? Is it the source/method of gathering/posting? For me, I see significant differences between SciHub and ResearchGate on multiple criteria and thus I’d be fine with linking to RG but I would not be to SH. I’m seeking to understand the principles upon which you reason to a different conclusion. It seems that you think there is an ethical imperative here beyond a business reason – but maybe it is just business reasons?
Side note – if it isn’t okay for Google to link to RG either, one wonders why so many publishers (such as, for example, OUP) link to Google from the reference lists in articles on their platforms as a mechanism for readers to navigate to full-text content. To use your reasoning, should we be asking whether publishers really be linking to Google when Google is pointing to RG?
For me, a site that has millions of infringing articles and that has 7X the traffic that goes to Sci-Hub is about as over the line as you can get without being Sci-Hub. If part of the site’s business model is to deliberately entice traffic in illicit materials and force the copyright owners to spend the time and expense needed to police the actions of the company, then to me, yes, that’s over the line. And again, if you’re starting a business and you need to rely upon the cooperation of publishers, then driving traffic to a site that many of the largest publishers see as an existential threat is probably a bad idea. See for example the many discovery tools that do not include piracy sites, which seem more likely to me to see publisher support.
As for Google, what makes you think that publishers haven’t been trying to work with them to remove links to piracy sites? In some ways, Google is an 800 pound gorilla. The entire scholarly publishing market is a daily rounding error to Google, and so unfortunately publishers have little leverage with them. There’s also the reliance most publishers have on the traffic Google sends to them. Here, Kopernio has no such leverage, and it seems to me little reason for publishers to work with them when there are so many companies willing to work cooperatively toward mutual benefits.
Thanks. I appreciate understanding a bit more of your perspective on RG. (I had somehow missed that RG had so much more traffic than SH … that’s fascinating to learn!)
As for Google … I’m making no such assumption that publishers haven’t tried to lobby Google on this. In fact, I would assume that they have. I’m making the observation that, in spite of pointing out that Google does indeed link to pirated copy, publishers continue to link to Google from the reference lists of their own publications. The answer seems to be that publishers are too addicted to the benefits of their relationship with Google to stop linking to Google even if Google is enabling piracy of the publishers content? Kopernio’s flaw is not being able to “leverage” something over the publishers like Google can?
Ultimately I guess the question is how Kopernio – and other services – balance publisher priorities and user priorities. If users discover that they can get more access (which they believe to be licit – whether it is or not) using other tools, then they won’t use the ones (like Kopernio) that drive them to subscribed content. Which might ultimately be what publishers might want to prioritize – even if a tool provides links to content that may/may not be licit – if it ultimately drives more to the publisher site, isn’t that a tool publishers would prefer to see succeed? A conundrum!
Thanks again for detailing out your thoughts a bit more for me!
I’m probably not the right person to talk about Google with — I have a lot of issues with them and think what they do is bad for society. I moved off of GMail 6 or 7 years ago and switched over to DuckDuckGo long ago for my searches. But there is something right in what you’ve said, a pragmatic tradeoff — publishers will put up with more from Google than they will from a company that isn’t quite so mission critical. And given that Kopernio is part of a company that is a direct competitor for many of the big publishers in the data analytics game, any reason to drop support for that competitor is probably welcome. I see why a discovery company would want to dive into the world of infringing articles, the more content they can get to a user, the more they would be valued. But it also seems reasonable to me that if you’re suing someone, as several of the largest publishers are doing, you might not want to be partners with a company that is actively boosting your legal target’s business.
And the traffic figures for RG come from this article by Robert Harington (originally compiled by Wiley):
https://scholarlykitchen.sspnet.org/2017/10/06/researchgate-publishers-take-formal-steps-force-copyright-compliance/
David: In my mind stealing is stealing. The publishing of an illegal copy and then making it available to the public is called stealing. The user of the article says whats the harm and with a wink and a nod downloads it. I think that if law enforcement officer appeared at the door of a respectable academic and slapped the cuffs on him/her and had them do a perp walk to the car that the problem of using an illegal copy would quickly end!
It’s hard to miss the irony of publishers complaining about users’ obtaining their content for free, while expecting to get, also for free, the benefits of broad discovery. Distribution and promotion of their authors’ work product is part of the core mission of scholarly publishing, just as much as the management of peer review, editing, and production, so why should publishers expect such a vital service to be without a cost? If publishers want to promote their content without having to rely on services that that also provide easy ways for users to get their content for free, some level of investment will be required to make their legitimate distribution channels more discoverable. Can I tell you about a low-cost and proven-effective way to optimize discovery on a publisher’s own platform?
To be fair, many publishers are investing in their own such programs, and many partner with and financially support others. This isn’t about the publisher getting something for free — we’re eager to work with such services toward our mutual benefit (and let’s not pretend that there’s not a significant business model behind those magically “free” discovery services — last I heard TrendMD was not a charity). This is about the service skirting the law and trying to get something for free that actively damages the publishers’ business. That’s not mutually beneficial, that’s not even neutral, that’s actively hostile.
Understood, but rather than wringing their hands and relying on the lawyers to solve the problem, publishers need to find ways to proactively enhance discovery. My point was simply that many publishers have come to rely on Google and other free channels of discovery, without recognizing that they come with their own type of cost. Just as in the wake of the wreckage of the music industry, artists have had to become savvy marketers in order to find those individuals who will be most interested in their work product. TrendMD provides publishers with strategies to do exactly that, and at the lowest possible cost, due to our unique credit system. Making the basic service available for free has helped make this effective by quickly building our network, but yes – the best results come when publishers invest a portion of their marketing budgets to support the effort.
Lawyers are generally the last resort — see the years of negotiations that took place before anyone started legal responses to ResearchGate for example.
I’m not so sure that publishers are ignorant of the dangers of Google, as in my experience, most are about as wary toward Google as they are toward Amazon. And you’re probably right about some segment of the market being understaffed, or at least not putting enough effort toward marketing, but at the same time, we’re seeing consolidation around the big players, all of whom have enormous marketing departments and substantial investments.
Google has a cost every time we have to change metadata, change tags, redesign pages to have the abstract “above the fold,” as dictated by Google. As for Google links in references? I’ve not seen this as a viable solution to anything. More errors or just citation records instead of paper records than actual help. That could be way better and more helpful.
The “discovery tool” or search engine provider with millions of users calls the shots. Right now it’s Google Scholar. I also suspect there are many publishers that would love to partner with RG on expertise mapping and other networking tools but RGs insistence on hosting content under copyright is a no go. Google Scholar is not hosting content illegally.
The Kopernio relationship with Web of Science is concerning, but again, WoS is a major driver of publisher traffic…for now.
Mea culpa! Thank you to @terrybucknell for pointing out that my test article in this post is indeed discoverable within Dimensions, found with the help of a search operator + date filter. https://app.dimensions.ai/details/publication/pub.1023532201
Still puzzled as to why I missed it the first time around — but perhaps an important reminder of how difficult / complicated it is to get scholarly search right, from both the provider and end-user perspectives!
So, at risk of turning this into a series of corrections to your chart … it seems another would be in order. With article and journal title as a free text search, Microsoft Academic retrieves this one record: https://academic.microsoft.com/#/search?iq=And%28Ti%3D%27a%20model%20of%20information%20practices%20in%20accounts%20of%20everyday%20life%20information%20seeking%27%2CComposite%28J.JN%3D%3D%27j%20doc%27%29%29&q=a%20model%20of%20information%20practices%20in%20accounts%20of%20everyday%20life%20information%20seeking%20j%20doc&filters=&from=0&sort=0 which provides a link to the copy on the author’s website.
More puzzlement as to why you didn’t retrieve it I imagine. What I would hypothesize this tells us is that users (such as yourself) develop tacit expertise with tools that they use regularly that allow them to overcome limitations and/or develop efficiencies. When they move to new tools, that are unfamiliar, those tacit strategies fail them because they are either ineffective or not brought to bear because the user does not realize that they have been employing them. To me, that is one of the expert abilities that librarians bring to search and why we can many times locate items that users do not – we bring to the forefront explicit knowledge and use of strategies that others either do not have or only have tacitly.
Anyway … I think it is ultimately good news that these tools do have the coverage that we might hope, at least as tested with this n=1!
Ah, the distinction being in this case I was not using the journal title in my test searches — instead, article title, author surname and year. But, great point about users repeating the formats and strategies that work in one service to other search engines, expecting similar results. I also think this proves that extending the query terms is an important aspect of advanced search skills (perhaps also having a measure of patience!). I am encouraged by the wealth of high-quality scholarly pub-data out there, as well as the competitive landscape in making use of that data!
I think this is the key takeaway “repeating the formats and strategies that work in one service to other search engines, expecting similar results” may not be the winning strategy. FWIW, when I start typing in the article title in MSAcademic, it gives me an auto-complete with the author’s name, and then it’s the one record again. But, then, if I force an absolute keyword search of the same terms by copy/pasting them in and particularly adding in the date, I see the mess one ends up in.