In order to contribute analytical food for thought at this week’s Joint Roadmap for Open Science workshop, I was invited to facilitate discussion on the current landscape of open science tools and the opportunities for new or improved digital products in service of the research workflow. Among many things, Joint Roadmap for Open Science Tools (JROST) members came together to consider where they might collaborate and innovate to solve problems for scientists and further their shared goals in achieving an open, transparent, and non-profit vision for scholarly communications.
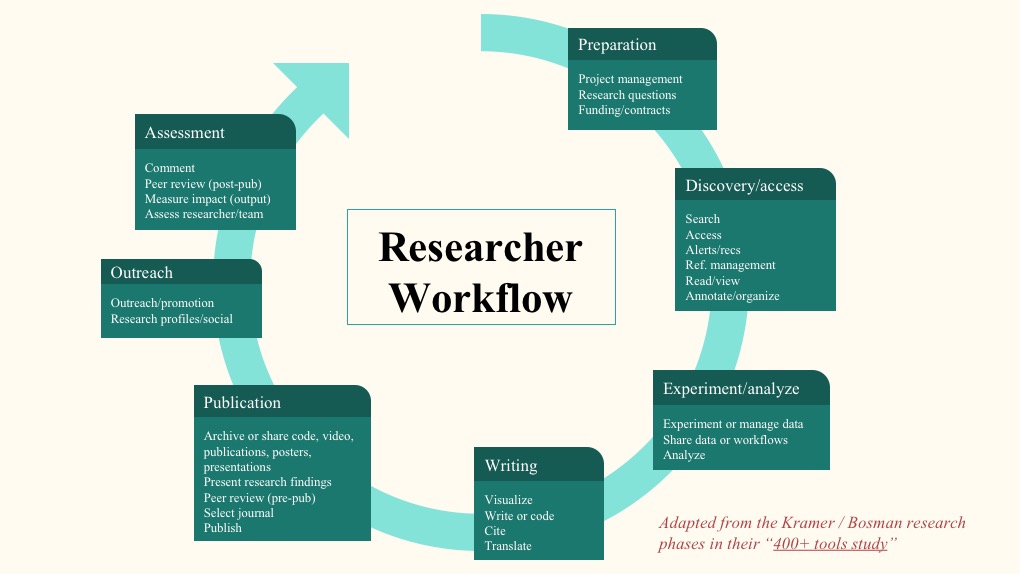
Using a generic view of the scientific workflow, I evaluated all open end-user tools or programs — as well as open information standards or other services — that facilitate the delivery of scientific knowledge. This meant looking at largely web-based applications, with or without download requirements. I took up a broad definition of “tools” to encompass both discipline-agnostic services as well as those that were discipline-specific, especially those with a focus on hard-science fields (see more in the Footnote below). I kept educational or advocacy initiatives as well as generic tools aside for purposes of this project, to enable a targeted focus on digital product development opportunities for science-driven software and services.
Like the extensive work from Bianca Kramer and Jeroen Bosman of Utrecht University Library, all open science tools were assigned to the primary research phase and task that best represented their value proposition. In keeping with the JROST goals, I looked at only those tools that could be classified as truly open science, per their criteria. For purposes of this project, we zeroed in on those tools provided by non-profit or community-based organizations using open source software, offering open data, via an open license, leveraging open standards where possible — basically, as open as humanly and technologically possible.
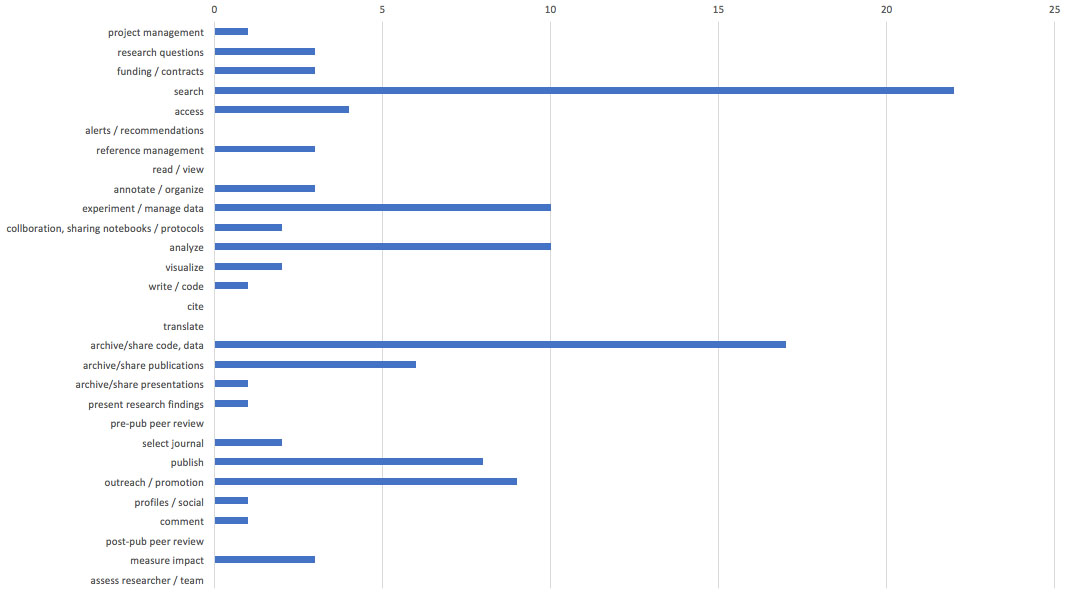
Once all open science tools were tabulated, we could begin to see some clear gaps and opportunities. For example, many open science journals platforms, PLOS or OJS, include content alerting or recommendations. However, using the JROST criteria, there are no fully open tools that offer a cross-publisher push service to keep researchers up to date or provide related content suggestions. Filtering signal from noise is an evergreen researcher issue and poses a rich opportunity for the open science movement to take up.
Similarly, I often hear from STM researchers that translating scientific materials is a top obstacle to accessing the research literature. While many may rely on Google translate, the open science community could scoop proprietary competitors by offering a more reliable, potentially crowd-sourced option for content translations. Discipline-neutral open tools for authorship and visualization offer openings in the market. Tools for soliciting both pre- and post-publication peer review is another area of opportunity to consider, beyond the reviews inherent in submitting a manuscript to an individual journal.
Also noted in a recent OPERAS paper, it is clear that open science authoring and review systems have a ways to go to compete with proprietary systems. While there are some excellent educational initiatives and programs, such as FOSTER or the Center for Open Science, that help identify new research questions and securing funding, there seems to be a lack of self-operated tools or apps to support this stage of the scientific life cycle. These and other gaps in the table above present a chance for the JROST community to dive in and ask scientists — as well as libraries, publishers, funders, and other invested parties — what is needed in those workflow phases without sufficient open-science solutions.
Much like the Kramer/Bosman data that analyzes all apps available to scholarly communications, we are seeing a crush of tools to support key research phases — especially literature or data searching; archiving or sharing of data and publications; publishing and outreach. There are plenty of opportunities in these crowded phases, however, where existing tools may be lacking in usability, accessibility, or interoperability with other systems. Lowering cost for both end users and institutions is a natural fit for open tools. And, where many apps are loaded with every worldly feature, open science could be competitive by offering simple, targeted tools that make a difference in the lives of researchers — as well as achieving their goals for transparency, accelerated innovations, and greater equity of access to scientific knowledge.
What we cannot see in these results are those research practices that rely on analog of offline work, where paper-to-pen or sample-to-test-tube must be integrated into a digital workflow. These results also do not reflect on hidden systems used by academics or unknown tasks in the scientific workflow. We might surmise that research team collaborations are best served by generic, well-known tools, to reduce the cognitive load of learning new tools, but more research would be needed to understand how researchers stitch together a suite of apps to support their teamwork. Having a better view of these realities for researchers would require a field-specific inquiry into the information experiences of the users we aim to serve.
There is a wealth of opportunity available to open science software providers, to address the unmet or under-served needs of researchers and others in scholarly communications. For example, there has been an understandable focus on biological and life sciences, with tremendous potential to address the medical, environmental, and other social challenges of interest to wealthy funding agencies. There are a number of critical developments, as well, in multidisciplinary research efforts and new areas of study — for example, where data science and social / behavioral science intersect. As Roger Schonfeld has pointed out, expanding one’s strategic view to disciplines beyond STM can open up “different models of alignment.”
In this review of scholarly tools, I evaluated the discipline specialty or neutrality in open science workflow solutions. I was surprised to see that 100% of open science tools for the outreach and promotional phase aim to be discipline agnostic. Whereas, data analysis and publication tools favor STM research. There are also some gaps in discipline-specific tools to serve earlier phases of preparation and discovery. There are a number of open-science sharing and collaboration tools in technical, medical, or other hard-science fields, where statistical data generation and analysis rule the day. However, there are big gaps in, and strong demand for, open tools to support qualitative or mixed methods research.

Beyond the researcher experience, there are clear gaps in open science solutions for those stakeholders that make the scientific journey possible, namely libraries and publishers. Their version of the scientific workflow will look a bit different, with both different priorities and expectations. The open science community has an opportunity to solve problems in metadata and indexing, collections management, impact assessment, and other shared needs. As much as we are rightly keeping the researcher perspective at the center of our conversations, the end-user cannot move the open-science needle alone; all providers must keep in mind that researcher experiences are influenced by incentive and reward structures (tenure, citations, etc.) that involve a number of players. We can unearth new strategic opportunities by examining other user cases in the scholarly supply chain.
The natural benefits of open science — greater control over both source code and scientific findings, transparency, reproducibility, etc. — offer JROST members competitive advantages over proprietary approaches. Beyond technology, truly open tools have the capacity to earn trust of both users and developers, establishing the type of reputation that is increasingly difficult for corporate entities to establish. These social dimensions speak to those who are looking to counterbalance the economic and strategic concentration going on in our industry, by investing in technology outside the reach of traditional organizations striving for infrastructure ownership. The measurable benefits of open data and citations are also a valuable point to consider from a product strategy perspective.
Although we structured our conversation around a user-centric research workflow, the JROST criteria for what defines an open science tool was not validated with scientists or end-users during the course of this project. I am confident that many researchers would agree with this approach, however, others likely come to decisions about scientific software with other priorities and preferences. My purpose here was not to take a claim in any debate, but I think it’s important to stay aware of what elements of ‘open’ matter to each stakeholder in the scientific lifecycle. Resources that are open to the public or free may be open enough for some researchers, whereas others have a mission-driven investment in the wider movement to see all elements of research be as open as possible.
As noted above, it was not my role in this workshop to advocate for or against any specific business models or strategic approaches to providing workflow products and services to the scientific community. Instead, conducting this analysis and sharing it with attendees helped me appreciate the value of diverse approaches to solving the various problems and addressing the enormous potential of digital scholarly communications. For example, there are excellent spin-off groups driving workflow innovations within traditional publishing organizations. And even start-ups demonstrate there’s no one right way to contribute to scholarly workflow solutions. For example, Meta was a for-profit entity before it became part of the Chan Zuckerberg Initiative, a non-profit entity; it continues to be a popular tool with scientists in both incarnations.
While there is an increasing number of studies and data-points to help us understand the ecosystem of open science tools and services, more research is needed to fully understand the workflow solutions at varying degrees of open. This project did not endeavor to measure popularity or researcher uptake of open science tools, but this would enrich our understanding of information software needs of today’s researchers. End-user criteria for either specialized and/or generic solutions requires deeper examination. A disciplinary view of the research lifecycle would also be of value, tracking how the information practices differ across humanistic, social and positivist fields. I look forward to these ongoing conversations, at JROST and elsewhere, and your welcome comments here to extend our cross-sector dialogues on open tools to support scientific progress.
Footnote: While each tool is assigned to one primary research task, it understood that these apps and services often offer support for more than one research task or use case. It is also accepted that research tasks are rarely linear, nor carried out in the same manner or sequence across all fields of study. Researchers often ping-pong back and forth across tasks and phases, especially in the initial development of a research question and reviewing relevant literature. Nonetheless, this generic workflow is an important user-centric organizing principle that served as the starting point for my evaluation of the ecosystem of open science tools for this workshop.
Author’s note: Many thanks to Bianca Kramer and Jeroen Bosman for their impressive work on scholarly tools, as well as to the Hypothesis team for the opportunity to join the JROST workshop.

Discussion
1 Thought on "Mapping Open Science Tools"
This is an extraordinarily helpful synthetic overview, Lettie, especially in its analysis of gaps. At an institutional level, as at University of Michigan, we struggle to provide support to researchers overwhelmed by choice (especially in HSS fields) and this kind of framework is invaluable.



