Today’s interview is with an organization that is very close to my heart! I first started to engage with DataCite while I was at ORCID, including working with them and other persistent identifier (PID) organizations on PIDapalooza, one of the most fun and productive industry events ever (in my totally unbiased opinion!). I’ve stayed involved with DataCite since leaving ORCID, including as a member of the DataCite Community Engagement Steering Group, one of the groups that has helped shape their next three-year strategic plan. It’s with that hat on that I invited their Executive Director, Matt Buys; Community Engagement Director, Helena Cousijn; and Outreach Manager, Paul Vierkant to tell The Scholarly Kitchen readers a bit about DataCite’s evolution, values, and goals.
Let’s start with an introduction to DataCite — who are you, what do you do, and why?
DataCite is a global not-for-profit membership organization that provides open infrastructure to identify, find, cite, connect, and use research. DataCite was founded in 2009 to make research data citable in the literature using digital object identifiers (DOIs), thereby providing an incentive for researchers to share their data. Since then, a lot of work has gone into making the magic of data citation happen. Initiatives such as the Joint Declaration of Data Citation Principles and FAIR data principles, and collaborations in the context of Make Data Count, the Research Data Alliance, FORCE11, and the Enabling FAIR data project have played a big role in the implementation of data sharing and data citation.
Helping organizations share their data remains an important focus for us, but over the years we have moved beyond just data. It is increasingly recognized that all different types of research outputs are needed to replicate and reuse research, and DataCite provides infrastructure to facilitate that. As a global organization working with around 1,100 other organizations around the world, we now provide persistent identifiers (PIDs) and the associated metadata for a range of research outputs and resources, which include software, workflows, samples, data management plans (DMPs), and a range of text documents. Our members inform us about the needs in their communities and help us identify and expand into new areas where DataCite services are needed.
DataCite was founded to enable data citation, why does data citation matter and how is it evolving to include so much more than just datasets?
Formally published papers have been used to communicate research for centuries. However, articles provide only a fraction of the information required to fully evaluate — or replicate — a study: just a short description of the work and conclusions. It is very important that the underlying information is also available, as well as a mechanism to easily link to the experimental design, the research data, and the analytical tools that were used to generate the reported outcomes. Otherwise, the research community is unable to fully understand the results of the research, to replicate it, or to evaluate and reuse it. Availability of the different outputs of a research project also enables reuse of data and software in order to aggregate findings across studies, to evaluate discoveries in the field, and ultimately to assess and accelerate progress. Making outputs FAIR (Findable, Accessible, Interoperable, and Reusable) and assigning datasets a PID are a crucial part of this.
Why are persistent identifiers and metadata important when sharing research?
What we hear from our members is that PIDs and metadata are very important for discovery of research outputs, which leads to more visibility for researchers and institutions. The FAIR principles provide a broader explanation of why you need PIDs and metadata. The F(indable) principle explains that “(meta)data are assigned a globally unique and persistent identifier (PID)” and “Metadata clearly and explicitly include the identifier of the data it describes” to make resources findable. To be A(ccessible), “(Meta)data are retrievable by their identifier using a standardized communications protocol”. PIDs improve I(nteroperability) by creating links between digital entities and providing context through metadata with references to other metadata. Finally, PIDs play a role in the R(eusability) of data by enabling rich metadata and provenance to be associated with a digital object.
What does being a community-led organization mean in practice for DataCite, and how would you describe your community?
Our community consists of people and organizations throughout the research lifecycle and around the world, who believe in open research and want to identify and cite their research — this includes universities, research organizations, research funders, research facilities, and researchers themselves, from different disciplines. Our members come together to support the infrastructure they need; their voices drive our work.
To facilitate this, we work together following these core values:
- Reliability: We develop and support reliable persistent identifier services.
- Transparency: We make transparent decisions and engage openly with the community in all that we do.
- Trust: We seek to be a trusted partner for our members and other community stakeholders by delivering services that uphold community principles.
- Inclusivity: We support a global community and value diverse perspectives.

How has DataCite evolved since its inception? What’s different and what’s stayed the same?
DataCite was founded 12 years ago. At the end of 2009, there were 12 organizations from nine countries under DataCite’s umbrella. Today, we have 1,095 organizational members from 50 countries, who have collectively registered over 29 million DOIs from over 2,400 repositories.
As mentioned, while data citation remains a core use case for DataCite DOIs, conversations in the community have shifted in recent years to use cases that extend beyond simply citing data to facilitating data reuse and reproducibility by identifying and citing resources used to generate, process, and provide context for data. Back in 2009, there were just 11 resource types with the majority of outputs being datasets, whereas now our metadata schema includes 28 different resource types. Our Metadata Working Group and the DataCite team continue to work with the community to identify emerging needs for identifiers for different outputs and entities, guiding the development of our schema and services.
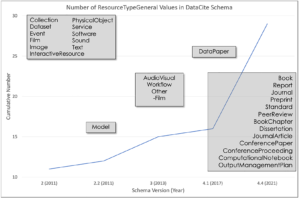
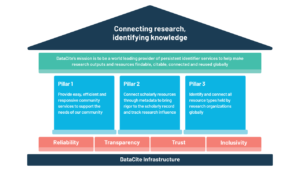
What about the future? You recently launched your strategic plan for 2022-25, comprising three pillars — what are they, and how and why were they developed?
During 2021, building on our core values, we went through a strategic visioning process with our community to understand current perspectives of DataCite, how we can continue to thrive in the future, and what roadblocks might get in the way of achieving our vision. Our new strategic plan emerged from this process, and provides the blueprint for the next steps towards achieving our vision and mission. We divided our areas of action into three pillars, which we will use as signposts that guide us over the next three years.
The first pillar is operational and will keep us on track with the member-driven development of our services. The second pillar focuses on different aspects of metadata such as completeness, connectivity, and discoverability, and reflects many of the FAIR data principles. By focusing on metadata, we enable our members to make their outputs FAIR and enable other stakeholders to reuse the metadata through services such as the PID graph. The third and final pillar is about broadening resource types beyond just a research paper and its underlying research data. Open research is a research lifecycle in which many different resources play important roles and therefore need to be taken into account. Together with our community, we want to do our share to enable researchers to fully evaluate the outcomes of research.
How will you know if your strategic plan is successful?
Every year we set annual goals and objectives, building on our strategic plan, which are reviewed periodically and adjusted as necessary, enabling us to qualitatively measure how our strategic plan is working in practice. In addition, Pillar 1 of the strategic plan will help us measure our success in quantitative terms, by: l (i) evaluating our operational objectives and processes annually to align with community needs as they evolve; and (ii) executing against priority indicators that measure our delivery of easy, efficient, and responsive services to support community needs. For example, we will analyze the completeness of DataCite metadata iteratively over the next couple of years, and check if progress has been made. Similarly we will analyze the increase in connections between research outputs using the metadata in the PID graph.
DataCite is part of the overall open research infrastructure community, which includes other persistent identifier services (Crossref, ORCID, etc), as well as a range of other organizations. What are some of the challenges and opportunities of working with these organizations?
DataCite – as an open research infrastructure – has always collaborated with other open infrastructure organizations such as Crossref and ORCID, and will continue to do so. All of us are driving towards the common goal of improving scholarly communication and enabling open research. For example, the three organizations collaborate on ensuring that outputs with a DOI are added to a researcher’s record. We also regularly organize webinars and workshops together, and Crossref and DataCite collaborate on establishing the connections between articles and datasets in the context of Scholix.
Over the years, we have partnered with several communities to scale their PID infrastructure services for various research outputs and resources. Some recent examples include our work with DMPtool.org and launching DMP IDs, and most recently partnering with IGSN to scale the IGSN ID registration services. We are always happy to engage with interested communities that share our vision.
What’s something most people don’t know about DataCite, but should?
People are often surprised when they hear that the DataCite team consists of only 13 people who all work fully remotely from around the globe. We try to meet as a team once or twice a year in person, and as often as possible with our community stakeholders, usually at community events. During the pandemic this has not been possible and our team has missed the in-person interactions.
What opportunities are there for organizations or individuals to get involved with DataCite?
Let us start by saying that there are many ways to get involved with DataCite and we are always happy to collaborate! Organizations that are interested in using our services can join us as members, as can organizations that simply want to express their support. Member engagement opportunities include:
- The DataCite General Assembly — all DataCite members together form the DataCite General Assembly
- The Executive Board of up to 12 people is elected by the General Assembly to govern DataCite
- Our two Steering Groups: Services and Technology, and Community Engagement help us set priorities and identify strategies related to sustainability planning, services, and outreach
- Three regional Expert Groups ensure we work with organizations from around the world and stay connected to regional needs and initiatives
- The Metadata Working Group determines and maintains DataCite’s metadata schema, in consultation with DataCite members and under the guidance of the DataCite Executive Board
Our steering and expert groups welcome representatives from non-member organizations, such as the author of this post :). It is very important to us to be inclusive and ensure that our services are accessible to everyone. Members use our services through their memberships, and individual researchers and research groups can use open platforms to register DOIs for their outputs and track the use of these outputs through DataCite Commons.



