Editor’s note: Today’s guest post is by Veronica Showers, Heather Kotula, and Marjoirie Hlava from Access Innovations.
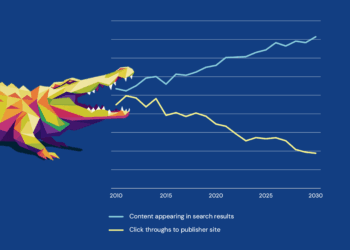
For years, scholarly publishers have quietly powered the world’s scientific progress. You published the research that helped design the mRNA vaccine platform. You host the clinical guidelines that determine how physicians treat disease. You steward the discoveries that shape global policy and scientific innovation. Yet for all that influence, publishers were largely spectators during the early wave of generative AI.
In the last two years, a quiet shift has transformed the relationship between scholarly publishers and the world’s most powerful AI companies. Large language models (e.g., OpenAI, Google, Anthropic, etc.), and a growing ecosystem of DSLMs (Domain Specific Language Models), and RAG vendors are coming to publishers asking to license their content. And it reveals something important:
These models can write poems. They can summarize Wikipedia. They can generate marketing material. But they cannot reliably answer expert medical questions, interpret advanced scientific concepts, or synthesize field-specific knowledge. They often struggle with nuance, precision, and terminology. They can create connections to fill gaps when they have incomplete or missing information.
This absence of meaningful and accurate information is becoming a problem for AI companies.
Despite their extraordinary fluency, LLM-related services have only used open-access content and have not had meaningful access to peer-reviewed, paywalled scholarly literature. Studies of LLM training sets confirm that the bulk of model training comes from sources crawled (e.g., Common Crawl), such as public books, free datasets, and open-source text.
This absence is becoming a problem for AI companies. Their systems produce responses that feel magical to the user, but they lack the conceptual rigor, domain specificity, and factual grounding that scientific content provides. To move into professional markets (such as medicine, clinical decision-support, engineering tools, policy systems, environmental modeling, and others), they need curated, authoritative content. And that content resides almost exclusively with scholarly publishers.
Simply holding the content is no longer the differentiator. AI companies don’t need more text. They need meaning and interpretation of results. They need the conceptual scaffolding behind the text, specifically the relationships, hierarchies, parent/child concepts, and synonyms that organize domain knowledge. XML alone cannot express these. XML remains a durable success: a structural backbone that standardized production and ensured preservation. But it describes form, not meaning.
This is where semantic enrichment becomes transformative.

The New Centrality of Meaning
For years, publishers treated semantic enrichment as an add-on, something that improved search, browsing, and recommendations. It was good for SEO. It made curated subject collections possible and easy to create. It allowed users to navigate a semantically structured landscape rather than wander through a maze of full-text search results.
But in the age of generative AI, semantic enrichment does something far more fundamental: it turns unstructured text into organized knowledge.
Semantic enrichment exposes the conceptual architecture within scholarly content. It shows the relationships of content to other content. Ontologies (taxonomies, etc.) tell machines not just what the words are, but what they signify. It resolves ambiguity (“Java” as a language vs. island vs. slang for coffee), links related concepts (melanoma → skin cancer), unifies variant terminology, and preserves hierarchical relationships (Birds → Chickens → Leghorns). It transforms an article from text into a navigable knowledge asset.
This isn’t theoretical. Multiple recent studies now provide clear empirical evidence that semantic or ontology-based layers directly improve RAG (retrieval-augmented generation) performance, including those used along with an MCP (Model Context Protocol) server.
The OG-RAG architecture of Sharma et al., grounded retrieval in a domain ontology and saw higher factual recall and improved correctness compared with standard RAG across four LLMs. Zhong et al., showed that combining semantic chunking with a knowledge graph “significantly improves retrieval relevance and correctness” versus traditional, text-only RAG. Tiwari’s OntoRAG outperformed both baseline RAG and GraphRAG in comprehensiveness and diversity of answers. Sun’s environmental QA research states plainly: “using ontology in RAG systems introduces a structured way of organizing information that can significantly enhance the retrieval process” and yield more accurate, context-aware outputs.
Major vendors echo this. Amazon Web Services writes directly that “semantic search enhances RAG results” and improves the quality of context fed to the LLM. Microsoft’s GraphRAG documentation reports “substantial improvements” in question-answering performance versus naïve semantic search over plain-text snippets.
The message is consistent: RAG systems that incorporate structured meaning consistently outperform those that rely solely on unstructured text.
For publishers, this means that enriched content is not only more valuable, but it is also more compatible with how modern AI systems actually work.
Why Enrichment Matters for Licensing and Strategic Value
When AI companies license raw text from publishers, they must still extract entities, deduplicate terminology, resolve ambiguities, build their own ontologies, and maintain conceptual consistency over time. This engineering effort is expensive, ongoing, and error-prone.
When publishers supply content that is preprocessed, specifically, intelligently chunked into coherent, meaningful units (such as overlapping sentences and paragraphs) and semantically enriched at the chunk level (creating a semantic layer), much of that work is already done, and more importantly, it is done by the people who own and understand the knowledge domain. This semantic grounding enables retrieval systems and language models to select appropriate content, rather than merely textually similar passages, and to interpret it within the correct disciplinary framework. Publishers retain control of the organizing logic, the preferred term usage, and the conceptual relationships that define their field. That semantic layer then becomes a defensible intellectual property asset.
Equally as important, semantic enrichment reduces misinterpretation. It creates a conceptual guardrail, a guide to meaning.
For AI companies, that distinction is critical. Raw text is expensive to process. It requires massive engineering efforts to clean, normalize, classify, and disambiguate. When content arrives already enriched, the cost of integration drops, accuracy rises, time-to-market shrinks, and the system’s overall reliability improves.
This is why enriched content is more valuable in practice, even if the license price isn’t explicitly “per tag” or “per concept.” It is not that AI companies will always pay more simply because tags exist. Rather, enrichment strengthens your negotiating position. It turns your content from “just more text” into a knowledge product. It gives you the ability to offer not just content dumps but APIs, knowledge services, RAG-ready feeds, and domain-specific assistants built on top of your own structure.
Additionally, LM developers do not think like publishers. Publishers think in terms of articles and prefer to license years’ worth of information via subscription. LMs think in terms of tokens and small data chunks (sentences to paragraphs). Licensing of intellectual property needs to be based on both points of view. As such, adding semantic structures increases the licensing options available to publishers.
This is more than an operational advantage. It creates new monetizable components: text, metadata, ontologies, and semantic tags. These can be priced and licensed separately. Analysts studying AI training ecosystems have noted that structured, rights-cleared data and metadata are emerging as distinct economic assets. Semantic enrichment turns that possibility into a publisher-owned reality.
Publishers as Active Participants in AI Integration
Publishers are no longer engaging with AI solely as content licensors. Increasingly, they are adopting emerging integration frameworks, e.g., Model Context Protocols (MCPs), to connect their content directly to AI systems, retrieval layers, and agentic workflows in controlled and auditable ways. An MCP is a standardized way for AI models to securely access external information sources, such as publisher content, databases, APIs, or retrieval systems, at the moment a question is asked, rather than relying solely on what the model learned during training.
As publishers explore MCP-enabled integrations, a critical requirement becomes clear: AI systems can perform only as well as the structure and grounding of the content to which they are given access. MCPs do not interpret raw documents; they broker access to information that must already be prepared in a form language models can reliably consume. This shifts responsibility upstream to the publisher to ensure that content is genuinely AI-ready before it is exposed through these integration layers.
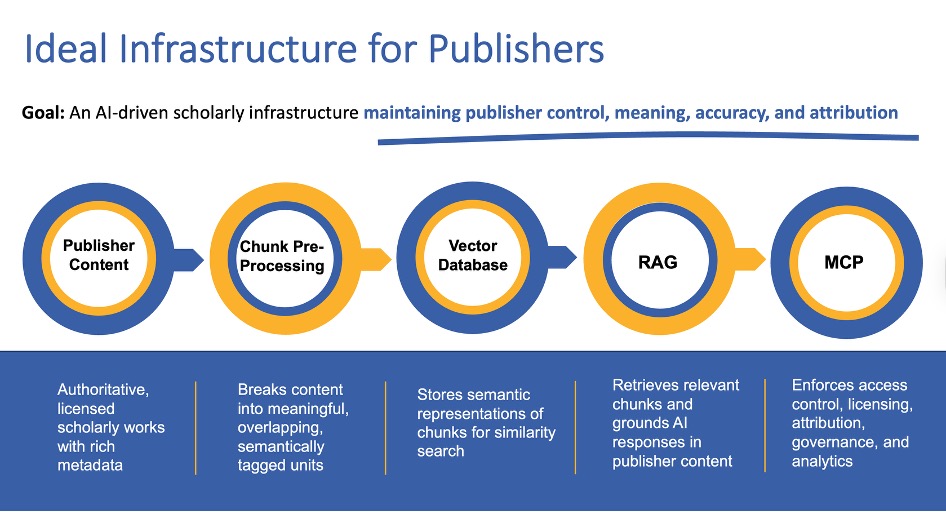
In this context, preprocessing is a requirement. Raw full-text XML or PDFs, even when structurally well-formed, are insufficient for AI use without preprocessing. To function effectively within MCP- and RAG-based workflows, content must be intelligently chunked. Equally important is semantic tagging at the chunk level. Applying ontologies ensures that each content unit is explicitly anchored to authoritative concepts, domains, and relationships. Creating this workflow: Content to Preprocessing to Vector Database to RAG to MCP to LM, shown in the figure below.
When Semantic Enrichment Isn’t Used
Despite its importance, semantic enrichment is not universally used. Vector-only RAG pipelines are fast and convenient for vendors, which is why many still rely on them. They retrieve passages based on surface similarity rather than conceptual correctness, often misinterpret domain-specific terminology, and are prone to hallucinating. When content is licensed solely for training or fine-tuning, structure is ignored entirely: the model consumes raw text rather than meaning. And because AI companies must merge information across medicine, engineering, finance, and law, they often avoid adopting any single publisher’s ontology for fear of constraining their flexibility. The result is that vendors rebuild their own internal view of your discipline, one that may be incomplete or inaccurate, yet it becomes the version millions of users experience. In these systems, it is their model, not your editorial expertise, that defines the meaning of your field.
This is precisely why semantic enrichment remains foundational for publishers, even if vendors do not directly ingest it. Enriched content is cleaner, more consistent, and far harder for AI systems to misinterpret. It preserves the logic and relationships your discipline depends on, stabilizes terminology, and ensures that, as RAG evolves toward knowledge-aware architectures, the conceptual map the AI relies on is anchored in the authoritative version you provide rather than the one a model guesses at. In a world where AI increasingly mediates how knowledge is discovered, interpreted, and trusted, safeguarding the meaning of the discipline is critical. It is the publisher’s most important responsibility.
A Future Built on Meaning
We are entering a period where AI will mediate more and more research discovery, clinical practice, regulatory analysis, and public understanding. In this future, the difference between content that machines can read and content that machines can understand will determine which publishers thrive and which fade into the background.
Semantic enrichment elevates content into a knowledge model, and that knowledge becomes the foundation of search, discovery, licensing, and AI applications. Publishers are no longer licensing documents; they are licensing the conceptual structure of their field. In today’s world, semantic enrichment unlocks the future.
We have entered a moment when publishers must stop thinking of themselves as providers of articles and start recognizing themselves as stewards of knowledge. You are not licensing text. You are licensing meaning. The structure you apply today determines how your content will be understood, retrieved, reasoned over, and valued in every AI system that comes next.
Your content was never trained into the models, and that is your advantage. Because now, as the industry is finally getting ready for it, you have the opportunity to shape how your knowledge enters the next generation of technology. With semantic enrichment, you don’t just prepare your content for AI. You make it indispensable to AI.
That is the kind of value no model can manufacture on its own.



Discussion
11 Thoughts on "Guest Post — AI Readiness and the New Value Equation in Scholarly Publishing"
Excellent post. It’s difficult for me to assess the applicability of the framework you present to small social science and humanities knowledge and journals. It would be great to see a working model.
Thanks so much for the thoughtful comment and for raising an important point about applicability for smaller social science and humanities journals. You’re right that scale, resourcing, and workflows can look very different in those communities, and it would absolutely be valuable to see a working model in practice.
We are developing a path that could be taken/ pursued centered on publishing collectives or shared-service collaborations that help smaller journals access enrichment, infrastructure, and AI-ready delivery tooling without each journal having to build it alone. And since AI (and AI-driven discovery/delivery) is here to stay, the real question becomes how we start solutioning in ways that are practical and sustainable for smaller publishers.
Social Science and the Humanities are strong candidates for this model, along with news and popular media. While these fields often use less descriptive, more eye-catching titles, they also rely on terms that can have multiple meanings depending on context. That makes it imperative for a Language Model to recognize the intended meaning within the specific publication, article, or book.
The challenge is compounded by the way language evolves over time. Terminology shifts as discourse changes, and new preferred terms emerge. For example, concepts such as “homeless,” “unsheltered,” and related terms can have dozens of variants, making it difficult to reliably find all relevant research. Likewise, what we now call “COVID” evolved rapidly and was referred to by many different names early on. When terminology changes—or when terms are discouraged or “suppressed”—older literature can become harder to discover because links between related terms are lost as the “term du jour” falls out of use.
The solution is to apply control to terminology by tagging content against a controlled vocabulary: a preferred form of each concept plus its synonyms and related terms, made available in a structured way for consuming applications and ingestion pipelines.
Good to know that the small-journal community is on your radar. I think you’ll find interest in collective action. I’d be happy to hear about any developments.
I’m 110% in support of what you propose here. My concern is that the value of semantic enrichment is insufficient for the AI organizations to offer publishers an ROI on their enrichment efforts and expense. Despite my enthusiasm, I haven’t seen evidence that the investment(s) will pay off.
Thank you, this is a fair concern. I agree that enrichment should not be justified on the expectation that AI companies will pay more simply because tags exist.
The ROI is less about immediate revenue and more about control and reuse. AI vendors will structure publisher content regardless through their own chunking and semantic enrichment pipelines. The question is whether that machine-readable representation remains vendor-bound or becomes a publisher-governed asset.
When publishers control this layer, it can be reused across RAG deployments, agentic workflows, MCP integrations, internal products, and licensing opportunities, avoiding repeated reprocessing as strategies evolve. It also mitigates risk by ensuring AI responses are grounded in expert-defined structure rather than generalized automation.
In that sense, the return comes from reuse, reduced dependency, and future cost avoidance, not payment for enrichment alone.
Hidden in here seems to a ‘problem for AI companies’ that is ‘the publisher’s most important responsibility.’ and yet ‘It is not that AI companies will always pay more simply because tags exist’.
Why should publishers invest to solve others’ problems if there is no guarantee of payment for this investment?
I agree publishers should not invest simply to solve AI companies’ problems, particularly without guaranteed payment.
However, AI systems will inevitably chunk and interpret publisher content. The practical question is whether that structuring happens exclusively inside vendor platforms or exists as a publisher-controlled, reusable foundation.
Publisher-governed enrichment supports reuse across RAG, agentic workflows, MCP-connected ecosystems, and licensing, while preserving attribution, provenance, and consistency. It also reduces the risk that AI outputs are derived from poorly grounded representations that do not reflect domain expertise, a risk that ultimately affects publisher trust and reputation.
So the ROI is not payment for tags, but ownership of the grounding layer, strategic flexibility, and avoidance of significantly higher restructuring costs later.
Perhaps the question more generally is why do semantic enrichment at all? Adding tags/keywords/concept labels to the content provides context, enables discovery, and ensures that the meaning in the writing is preserved. English has words with many meanings and words taken out of context lead to sometimes amusing, but often incredibly incorrect, interpretations of the information presented. There is a reason we have so many puns!
Let me highlight just two areas.
1. Words often change labels or meanings quickly in modern discourse leaving the earlier writings unfindable, buried in old terminology. Take the case of homeless / unsheltered / unhoused / street people /etc., and earlier, hobos / drifters / vagrants. We came up with at least 57 synonyms for this. Laws and research exist for every one of those terms. That is a big search parameter! Or look at when COVID appeared on the scene as Coronavirus, SARS (Severe acute respiratory syndrome), SARS-CoV-2 (Severe acute respiratory syndrome coronavirus 2), Covid-19, etc. How do we keep track of these changes and ensure that we are really doing a full scan of the available research data?
2. Words have different meanings in different domains. “Mercury”, for example, can be an element in chemistry, a planet in astronomy, a god in mythology, an automobile, a messenger, a plant, etc. “Lead” can be a management term, something you use to walk the dog, the inlet of a river to a larger body of water, or an element on the periodic table.
3. Words mean different things in different orders:
a. The dog bit the man. The man bit the dog.
i. Changes who the aggressor is
4. Punctuation matters and is often lost in GPT systems:
a. Let’s eat Grandma! Let’s eat, Grandma!
i. Who or what is being ingested, Grandma??
The value of semantic enrichment within AI is that when the data is chunked, tokenized, and fed into vector databases, all links to the word usage (meaning and context) are lost unless we tag that data in the beginning so it is held together throughout the ingestion process by the terminology control that the semantic enrichment provides. The prediction of which word might come next is powerful: it is more powerful with guardrails of a taxonomy or other vocabulary control.
The reasons to add semantic enrichment? Here are some:
1. Keep your meaning intact
2. Items linked back (attributed) to an author should preserve their intent
3. Prevent misinterpretation
4. Preserving data integrity
5. Preventing hallucinations (wrong interpretations)
6. Comprehensive search finding terms by all synonyms
7. Precision and recall in search
The reasons for caution:
1. Perceived cost
2. Not sure it will help with your publications
3. Convincing management to give you a budget
4. Trying to figure out how to cover the cost by charging the LLMs for use
5. Fear of the future
Is the caution really worth the potential misinformation and loss of integrity? If you’re reading about what AI companies are doing, you’ll see that they are coming for scholarly content, and they are doing it now. The lawsuits over copyrighted materials are now coming to closure, and the message is clear: AI companies have to license content and pay fairly for it. Semantically enriched content does two things: it preserves the context of your content so that GPT output based on your content is accurate and gives scholarly publishers some leverage over the AI companies – either they pay fairly for your content, or they don’t get it. For once, scholarly publishers have the upper hand.
I’m very glad to see this discussion opening up. It’s wonderful because it gets at the basic differences between social science (and the humanities) and the hard sciences. While your responses, Veronica, assume the inevitability of AI as the evolving hegemon, and they portray publishers as possible contributors to the veracity of AI, the financial rewards will accrue to the purveyors of AI while the publishers are left with moral superiority.
As Marjorie points out so well, preserving meaning and nuance by contextualizing words and phrases is as infinite a task as reducing the language of social science and common discourse without losing meaning and especially nuance. Lynne Truss’s “Eats, Shoots and Leaves” provides a host of examples. Similarly exemplary, as powerful and insightful as the dramaturgical framework of Erving Goffman was (see “The Presentation of Self in Everyday Life”), it mostly lives ghostlike in today’s sociological discourse.
I guess I was hoping for a miracle in my initial comment, that something as powerful as AlphaFold 3 (or 4) in the treatment of language might be emerging. I guess not.
Perhaps the best future for publishers is to compete with the AI organizations. Already, Elsevier is working on small-language model AI. Maybe there’s a case to be made for discipline-specific language models. After all, the same word can have different meanings in different disciplines.
Then again, perhaps we need to celebrate our “all too human”ness. Wake up Ned Ludd!
I do believe that the future for most of us will be in Small Language Models or Focused Language Models. It does not matter if it is humanities or STEM the vocabularies vary by discipline. Plasma is very different in medicine vs space science vs engineering.
Google and other large search engines (as opposed to search software) will find LLMs competitive. the rest of us have topical areas of interest which do better with a focused approach. And the controlled vocabulary to match. There are a great many vocabularies (taxonomies, thesauri, ontologies) available for use with or without auto tagging engines. The more specific the better the retrieval. here is one example https://www.accessinn.com/knowledge-domains/