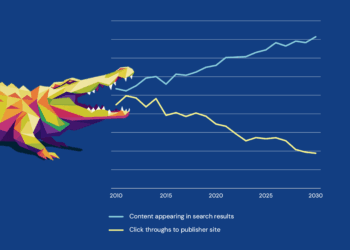
Have you noticed how you use Google these days? Has it changed? These days, I don’t click on links as much; an AI overview is usually enough to give me the information I need. This made me wonder how these overviews have affected the search behavior of researchers. As they type a search query, do they really click, or are they satisfied with the comprehensive and seemingly confident AI-generated overview that they get in response to their query? I believe it is the latter.
Zero-click readership can therefore be described as research that is consumed, interpreted, and even reused without the reader ever accessing the original source. What does this mean? From a discoverability perspective, this means no PDFs are downloaded, no tabs are opened, and no papers are read, which is such a drastic change from how papers have traditionally been read. Search –> Scan a list of results –> click the promising articles –> read/skim through these articles –> and cite — this was the traditional search journey for papers. But now the search journey is shorter. Search –> Read the AI-generated overview –> Move on.

From the reader’s perspective, this new way of finding synthesized information is faster and more efficient. But if readers are increasingly finding what they need without clicking on the paper, then what happens to journals as destinations? And what happens to the integrity and visibility of the research itself? Real traffic to the papers will decline, and this weakens the visibility of not just the papers but also journals that host them. This also affects data that publishers use to understand their author base. It could also have a potential impact on authors, affecting decisions related to funding, tenure, and promotions.
While efficient, this change has its share of risks for the reader; it comes at the cost of comprehension. Traditionally, there has been friction as readers move between papers. They may notice inconsistencies or grapple with details in the Methods section as they evaluate the paper critically. But this is slowly changing because they are no longer challenging what they read. They are learning to accept what is synthesized by AI.
Over time, this could have subtle but significant effects, for instance, early-career researchers who rely on AI-synthesized papers may not learn to evaluate manuscripts critically. AI systems may hallucinate, misattribute findings, or overstate, and summaries may often oversimplify things. The result is a version of research that is easier to consume, but potentially harder to question.
AI isn’t just summarizing research; it is, in fact, selecting what needs to be shown in the overview. Publishers, journal editors, and peer reviewers are traditionally considered gatekeepers; they are the ones deciding what should be selected and what is worth reading. There have been so many panel discussions and articles written about gatekeeping and the biases and limitations. These are at least visible and contestable. But what about the kind of gatekeeping that AI introduces? It decides which papers to include, which findings to show, and which perspectives to omit. This filtering happens at the back end without any clear signs of what is being left out. This process is opaque, and there is no editorial board to question or peer reviewers to challenge.
It’s like algorithmic obscurity is replacing editorial bias. Highly cited papers are more likely to be published. Papers in English are more likely to be surfaced than papers in regional languages, and well-structured AI-readable papers with accessible language and a standardized format are more likely to appear in searches.
It’s like a loop. What is visible ends up getting more visible, and what is hidden stays hidden. This is all the more an issue for authors in the Global South whose work may never reach the synthesized layer where AI discovery begins.
Another important change we see is that publishers may no longer be the primary interface between the research and the reader. They have, in fact, become part of the underlying infrastructure, essential but not as visible. They continue to produce, curate, and validate content, but that content increasingly serves as input into other ecosystems rather than drawing users into their own. Their role becomes foundational, but less visible.
This dynamic is not entirely new. Indexing services and aggregators have mediated access to scholarly content. But AI accelerates and deepens this trend by collapsing discovery and interpretation into a single step. The user no longer moves from platform to platform.
In such a situation, it’s important to consider: how can publishers continue to remain visible even when readers are not directly encountering their platforms? How does their role evolve beyond supplying credible content? Can they be instrumental in influencing transparency and traceability in AI outputs?
Finally, how does this new search behavior affect the way we analyze the impact? Today, we are discovering articles through synthesis, not discovery. If papers aren’t actually being read, then what exactly are citations measuring? This creates a fundamental misalignment between how knowledge is used and how impact is measured, i.e., via article downloads and citations. Downloads lose meaning if fewer people are actually clicking on a paper to read, and it is unclear if citations are the result of direct reading or interpretation via AI summaries. We are, in a sense, measuring a system that no longer reflects how knowledge is being used.
It is tempting to frame these shifts as a loss of traffic, visibility, and control. What matters, though, is not resisting AI-mediated discovery but shaping how it evolves.
- There should be traceability: a way for readers to track back to specific sources. Without this, the trust and reliability of research results are compromised. If researchers cannot easily distinguish between what is drawn from literature and what is inferred by AI, then the boundary between evidence and interpretation begins to blur. Publishers need to play a role in defining these expectations.
- How impact is understood needs to evolve: Should we consider new forms of influence? Perhaps one measure of impact would be inclusion in AI-generated summaries and answers, more specifically, how often does research surface in discovery systems, and how is it attributed by AI?
- Metadata matters: Abstracts, keywords, funding information, and contributor roles are not just descriptive elements; they are signals that determine how research is surfaced. Poor or inconsistent metadata not only reduces discoverability but also risks rendering the research invisible, so this needs to be encouraged.
The integrity of the academic system has rested on a relatively stable premise: that those engaging with research will return to the source. That premise is now being tested. Which brings me to my final unresolved thought:
If research is increasingly accessed through AI-generated summaries rather than via primary sources, then what does it mean to “engage with research” at all?

Discussion
6 Thoughts on "Zero-Click Readership: Are AI Overviews Changing the Way We Discover Research"
Another factor to consider is what happens to library subscriptions as a source of revenue for publishers as zero-click becomes the prevalent research method. Librarians generally rely on publisher-provided usage stats to make renewal decisions; and we have a hard time justifying renewals when the campus usage stats are low or nonexistent, especially in a time of declining budgets. If libraries start to cancel zero-use subscriptions, what happens to the sustainability of the scholarly publishing infrastructure?
I believe one thing we could think about is how rapid change will also skew research utilizing content for AI. AI will more readily utilize rich metadata, content available through MCPs, more solidly hosted and integrated content. The content producers most able to respond to that change will undoubtably be large publishers who have significant resources for augmenting and creating data that is truly machine-ready-for-AI. I fear this will “leave behind” the content less well represented by those large commercial entities, but that may hold a lot of value. Organizations that, for instance, have the budget to modernize their backfiles for machine ingestion could then be over-represented in training that occurs. We may rapidly need a way to evaluate AI outputs for source bias, understand more fully the provenance of the data on which an LLM was trained, etc. Making AI-ready data will take effort and technology, and not all will catch up at an equal speed.
This also extrapolates to how Google (& other search engines) optimise results to float the top of the search based on the data points of the person searching. We’ve always known that one person’s google search will look entirely different to another person’s. Now, however, will publishers/marketeers seek a paid “partnership” contracts with Google so their publications are prioritised for the AI overview algorithm? What kinds of hierarchies of power will this engender in the research sector? What will this do to the fundamental premise of scholarly communication? It feels like mere grift and marketing. It changes the whole paradigm and I can’t say I like that.
I also note that as a health librarian I’m becoming a big sceptic & avoidant re the AI “overview” in Google, because info is being pulled from “health” websites that are basically marketing sites for supplements and products. The AI overview can be little trusted to provide ethical, evidence-based health care, and it’s a huge worry, because it’s soooooo goshdarned EASY to consume – like buying packaged shredded carrots at the supermarket!!
You nailed it. Thank you.
I will only add that whole carrots or packaged shredded carrots are both equally good for you. The same can’t be said of a AI slop versus a authentic scientific research paper published in a peer-reviewed scholarly journal.
Very interesting read. Whilst there is merit in argument on AI making people dumb, there is also a counter to that – a lot of research that has exponentially exploded in recent years can’t be replicated. Therefore there is no way to assess the quality of methodology beyond a certain point and hence inherent subjective acceptance is built in anyway without deep challenge.
Publishers should therefore publish research extremely selectively using all the modern tools at their disposal. Whilst peer review process is a function of multiple authentication layers, added time pressure and pace of evolving research does provide weight to the point about use of modern tools challenging status quo and modernize at pace. There is a difficult choice of Quality versus Quantity that is faced by publishers due to competition and standards does go down a few times.
Summarily, AI seems to be shifting people from pursuit of intelligence to smartness and it will be interesting to see the impact on collective consciousness in few years !
The origin of what we have in academia today had its beginnings when Robert Maxwell understood that articles are written and vetted and Pergamon could publish the volumes at a profit. That idea is responsible for the number of vetting entites, that over time have evolved to address issues such as those discussed here that validate what gets published and evaluated because, for some, those rankings are used for multiple purposes including the basic publish/perish, promotion/tenure or validity that could have serious life/death consequences.
If one would go through the academic publications there are articles that are “flawed” which have stood for periods and often even have articles that are shown to not hold, as understanding advances. Are the concerns of the capabilities of AI needing addressment different from the spectrum of the humanities through hard sciences or when the ideas escape from the walls of the academic cloister and whether AI mediated is the issue at hand different from the first academic journals