Editor’s note: Today’s post is by Rob Johnson, Founder and Managing Director of Research Consulting.
A few weeks ago, I shared a post on LinkedIn about the Research Nexus Score, an open-source tool that scores scholarly publishers on how thoroughly they deposit metadata with Crossref. The numbers were striking and highlighted significant gaps in metadata completeness for many of the largest scholarly publishers. The American Physical Society was the only top-20 publisher by volume to score an A-grade in the tool for its recent publications.
The post generated over 25,000 impressions and some of the most substantive discussion I’ve personally experienced on LinkedIn. Publishers checked their own scores. Librarians asked why metadata quality isn’t a bigger priority. Several experts — including Bianca Kramer (Executive Director of the Barcelona Declaration), Andy Byers (The Open Library of Humanities), Fiona Hutton (eLife), and Toby Green (Coherent Digital) — challenged aspects of the methodology, and the tool’s creator, Aadi Narayana Varma Dantuluri, responded by shipping fixes (in some cases within hours) and logging requests for improvement.
The volume and quality of the response told me something: metadata quality has gone from a niche concern to a sector-wide anxiety. So, I spoke with Aadi to understand more about what lies behind the numbers — and what can actually be done about them.

The Pipeline Problem
The most important finding from Aadi’s work is not the scores themselves; it is that the majority of metadata gaps are pipeline problems, not content problems. The information often exists somewhere in the publishing workflow — ORCID iDs, affiliations, and some contributor role information captured during article submission, along with limited funding data described in acknowledgements sections — but it doesn’t survive the journey through to the Crossref deposit. As Aadi explained, “When I ran the analysis on individual journals, I could see ORCIDs deposited one month but missing the next. Is it that authors aren’t filling in the form? Is it the production supply chain dropping data at a handoff? Or is it an editorial or clerical error? Once you can see the pattern month by month, you know where to look.”
This resonates with what several commenters to my LinkedIn post observed. Paula Kennedy, Head of Publishing at University of London Press, noted that the good quality metadata publishers create is “so badly mangled as it goes through the supply chain” that the end result often bears little resemblance to what they started with. Toby Steiner from Thoth Open Metadata pointed to a recent report from Community-led Open Publication Infrastructures for Monographs (Copim) documenting what he calls the “Leaky Metadata Pipeline” – the systematic deterioration of metadata quality across the book supply chain.
Aadi’s insight comes from direct experience. A product engineer who has worked in scholarly communications for 15 years, his path to building the tool started when he quit his PhD because the incentive system felt broken. Subsequent roles at production services company TNQ Technologies, AI research platform SciSpace, and institutional CRIS provider Cintelligence each showed the same metadata problem from a different stakeholder’s perspective. “The metadata pipeline isn’t the publisher’s pipeline,” he explained. “It’s a supply chain with multiple handoffs. The publisher wants complete metadata, the service provider is optimizing for throughput, the researcher filled in the submission form in a hurry. Everyone has different priorities and, as a result, the metadata suffers.”
His design principle follows from this: if you can’t attach an action to a number, the number has no business existing. Every gap in the Nexus Score comes with a recommendation, and every recommendation points to a specific fix in Crossref’s documentation. It is intended to be used as a diagnostic tool, not a ranking exercise.
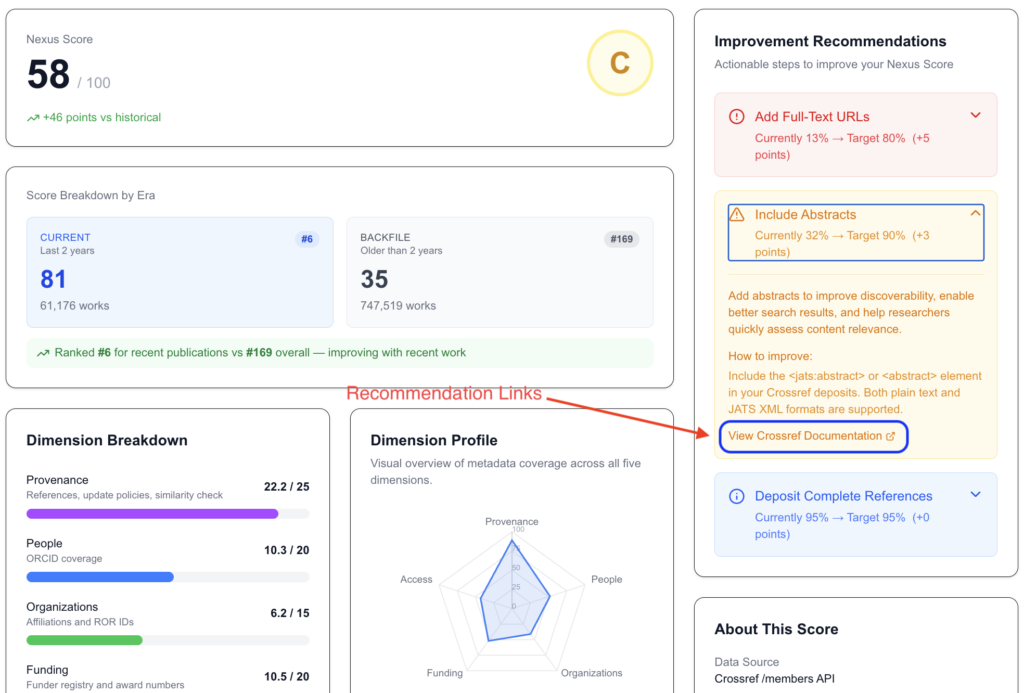
Why AI Changes the Stakes
Metadata has always mattered for discoverability, but AI is raising the stakes considerably. AI-driven research tools – Semantic Scholar, Elicit, Consensus, and the retrieval-augmented systems being built by every major technology company — depend on structured metadata to function. They don’t read PDFs one at a time; they reason over the scholarly knowledge graph. When metadata is missing, the paper may not even appear to exist to these systems. Clearly documented descriptors around the origins and provenance of scholarly work matter more than ever as discovery tools layer on top of content — they are increasingly fundamental to research integrity and to trust in science. Aadi explains, “If AI doesn’t have author identifiers, if it doesn’t have references, if it doesn’t have affiliations — how can it give you better recommendations? Researchers are already using AI to write articles. If AI can’t cite the right article because of missing metadata, people are losing citations. And that’s the future we are heading towards.”
He extends the point to a consequence that has had less attention than it deserves: when metadata is incomplete, AI systems may compensate by doing more work – more retrieval calls, more reasoning over noisier inputs, more compute burned to arrive at the same answer.
“Every missing identifier is a query the model has to run anyway, just less efficiently. Cleaner metadata isn’t only about better discovery; it’s about not paying, financially or environmentally, for the same information twice.” — Aadi Narayana Varma Dantuluri, Research Nexus Score
A methodology built in the open
One of the most striking aspects of the community response to Research Nexus Score was how quickly constructive criticism was acknowledged and addressed. Fiona Hutton pointed out that the tool was including all content types in its calculations, meaning that peer reviews and correction notices were diluting eLife’s score even though their journal articles actually had 99% abstract coverage. Within hours, Aadi shipped a content-type filter, and eLife’s score went from 31/F aggregate to 97/A for journal articles.
Andy Byers flagged that scoring publishers down for missing funding metadata penalizes research areas like the humanities, where research is often not supported by external grants but undertaken as part of an academic employment contract. Toby Green noted that institutional authors like the OECD don’t fit the ORCID framework, which is designed for individuals – meaning the People dimension is structurally unfair to certain organizations. Both points were acknowledged and logged as open issues on GitHub.
This matters because, as Bianca Kramer noted, composite scores inevitably introduce a subjective element in how different metadata fields are grouped and valued. Aadi’s response to this has been to make the methodology fully transparent and open to challenge. “If you can see something that is not right, we will fix it together,” he told me. “This is version 0.01. For it to reach version 1.0, we cannot build it in isolation.”
Kent Anderson offered a more fundamental challenge, questioning whether the tool’s grading scale and data processing had been properly validated. It is a fair point — and one reason why the open methodology matters. The scoring dimensions, weights, and thresholds are all documented and open to scrutiny on GitHub. The community is, in effect, peer-reviewing the methodology in real time. Research Nexus Score may have room for further development, but it has focused sector attention on metadata gaps that need addressing. For example, in comments on my original post, MDPI committed publicly to improving its ROR and ORCID coverage — a concrete response from a major publisher that would have been unlikely without a public scoring mechanism in view.
Beyond Publishers: The Institutional Angle
My original post generated engagement almost entirely from the publishing community, plus a handful of librarians. But when I spoke with Aadi, he stressed that Research Nexus Score should also be of interest to a much wider audience.
He has developed a live institutional view of the tool that takes an institution’s name, pulls its recent publication outputs from OpenAlex, and maps the metadata gaps by publisher. For the University of Nottingham, UK – where Research Consulting is based — it showed which publishers were depositing complete affiliation data and which were not; which were including ORCID iDs and which were leaving them out; and an estimate of the manual reconciliation cost that filling these gaps imposes on institutional systems. It is worth noting here that publishers can only deposit what authors provide, and submission systems do not typically mandate complete author metadata — but the leaky pipeline often wastes information that has already been captured, rather than information no one ever supplied.
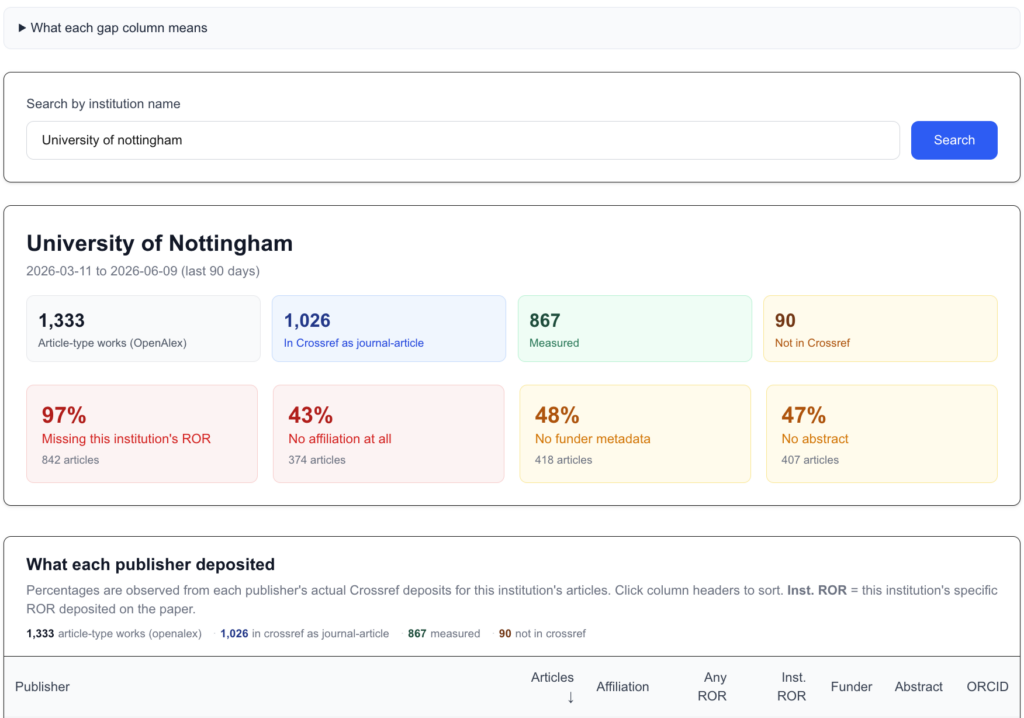
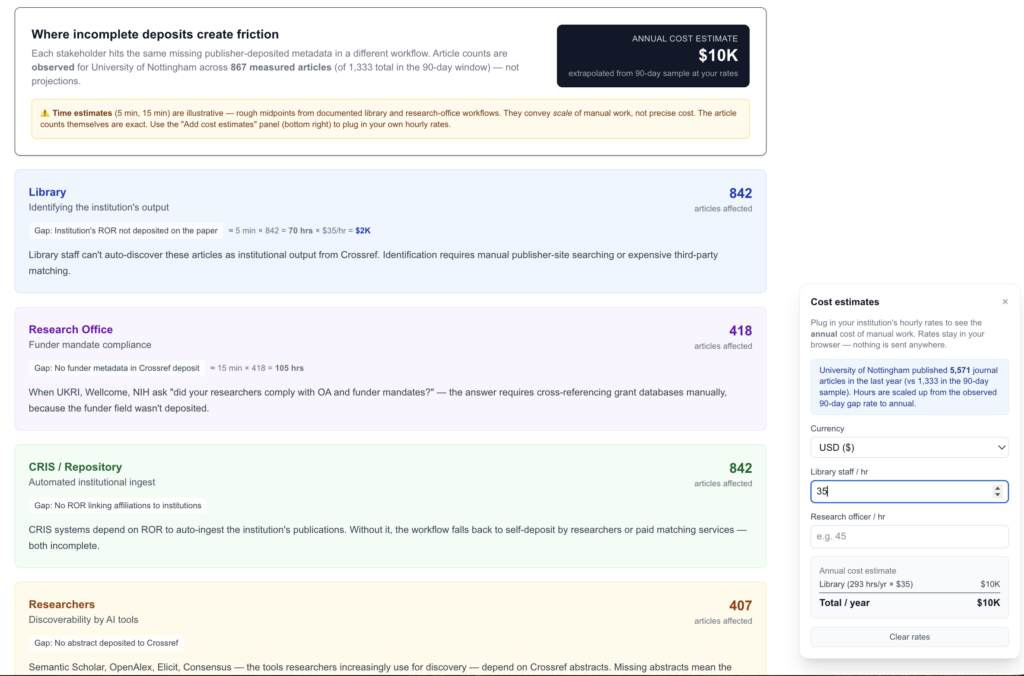
The implications are significant. When metadata is missing from Crossref, the intended user of that data — whether a university’s current research information system (CRIS), a funder’s grant reporting tool, or an AI discovery system — cannot automatically ingest the output. Someone has to reconcile it manually. Multiplied across thousands of papers and hundreds of publishers, there is a substantial hidden cost. Aadi sees similar potential for funders wanting to check whether their funded research has complete metadata, and for researchers choosing where to submit.
This is not a niche concern. A new OCLC report, Unlocking the future of e-resource management, describes metadata as “the connective tissue of e-resources management” and documents how pipeline gaps — missing persistent identifiers (PIDs) and metadata — such as ORCIDs, RORs, and funder IDs that fail to propagate across knowledge bases, resolvers, and discovery systems — create hidden costs for institutions through broken links, duplicate records, and manual reconciliation. The diagnosis is converging from multiple directions: publishers, libraries, and infrastructure providers are all identifying the same structural problem.
This connects directly to a growing movement to make metadata quality a condition of library licensing agreements. The Barcelona Declaration on Open Research Information, which now has over 130 signatories from 26 countries, has made this an explicit strategic priority. In October 2025, the Declaration launched a Joint Task Force with OA2020 specifically to develop model negotiation clauses and frameworks for embedding open metadata requirements into publisher contracts. As Ludo Waltman, co-chair of the Task Force, put it: “Universities make large investments in agreements with publishers, but many publishers do not even make basic metadata such as author affiliations openly available.”
What has been missing is an easy way for publishers to identify and fill gaps, and for other organizations to monitor compliance. Tools like Research Nexus Score, along with Crossref’s enhanced Participation Reports (and the accompanying gap-filling report and documentation), offer a way to address this.
What Next?
Aadi is currently running pilots with publishers, providing journal-level diagnostics through a prototype called Journal Nexus. This tool analyzes a publisher’s entire portfolio at the journal level, identifies where the pipeline drops data, and maps what can be recovered from open sources like OpenAlex. Early results are promising: when a publisher turns on a deposit field, coverage typically improves across all their journals regardless of discipline – confirming that these are infrastructure problems with infrastructure solutions.
Aadi is also developing a new third tool — Nexus Gap Fixer — which sets out to close the loop. It takes a single article (as a PDF or Word file) and produces both a Nexus scorecard and a deposit-ready file that can be sent straight to Crossref. The tool runs on the publisher’s own systems, so manuscripts don’t leave their network. Most of the work — pulling out ORCIDs, affiliations, funder IDs and the like — happens for free, using public registries. A large language model can also be used where the user decides it’s worth it for a particular paper, and the cost (a fraction of a cent in most cases) is shown upfront. You can find more information on the project page.
The Research Nexus Score is available at nexus-score.vercel.app. It is open source, built entirely on Crossref’s public API, and the methodology is open to comment on or challenge on GitHub.
Discussion
6 Thoughts on "Guest Post — Fixing the Leaky Metadata Pipeline: A Conversation with the Creator of Research Nexus Score"
Thank you, Rob, for the thoughtful conversation and for bringing this discussion to The Scholarly Kitchen.
One thing I would like to emphasize is that Research Nexus Score is not intended to be another ranking system. It is an attempt to make metadata gaps more visible, measurable, and fixable.
For me, this connects back to a 2017 PeerJ preprint where I argued that scholarly communication is an ecosystem, and that meaningful change has to align the priorities of researchers, publishers, funders, governments, institutions, and infrastructure providers: https://peerj.com/preprints/3015/
That still feels true today. Metadata quality is not just a publisher problem, a librarian problem, or a technical deposit problem. It is a shared infrastructure problem.
As AI becomes more involved in research discovery and synthesis, incomplete or inconsistent metadata will directly affect attribution, accountability, visibility, and trust in the scholarly record.
I’m grateful for the discussion and very open to feedback from the community on the methodology, edge cases, and how Research Nexus Score can be improved.
Thanks, Rob, for highlighting that metadata quality is no longer a “niche concern”—fully agree, and those in the community who worked on [Metadata 20/20](https://metadata2020.org/learn-more/outcomes/) have been making that case for a while. Thanks also, of course, to Aadi for building such useful diagnostic work on top of Crossref’s open API; exactly the kind of community use we hope to see when we collectively invest in open infrastructure.
And as you say, the nuances underneath the scores matter more than any single metric (as ever)… Crossref has been investing for some time in helping members see and fill these gaps, often hidden behind the various service providers and platforms they use—through our enhanced [Participation Reports](https://www.crossref.org/members/prep/) (that you mention), our [Metadata Matching program](https://www.crossref.org/community/special-programs/metadata-matching/), and our [Metadata Health Check webinars](https://www.crossref.org/events/metadata-health-check-webinars/), where members can get direct help with the record-level issues that Aadi’s tool surfaces.
We are part of the Barcelona Declaration and co-organised the [community roundtable](https://barcelona-declaration.org/news/20251023_community_roundtable/) last October that produced their recent [Call to Action on open funding metadata](https://doi.org/10.5281/zenodo.20189998). The Call explicitly points to Grant DOIs and ROR IDs as technical anchors for the connected record we’re all working towards—I’m re-sharing this here as a little opportunistic nudge for TSK readers who are also Crossref members or integrators to please include them in your metadata 🙂
One small note on names: Aadi’s tool (“Research Nexus Score”) and Crossref’s strategic framework (“the Research Nexus”) share a name but are different things. Our [Research Nexus](https://www.crossref.org/documentation/research-nexus/) is our vision of a connected, open network of research objects, contributors, organisations, funders, and integrity actions—the foundational linking layer we operate. Aadi’s tool—which he named independently—is a separate diagnostic of how Crossref members are contributing to that wider record.
The results of this tool are seriously flawed for any journal that publishes conference abstracts in the journal, for example as a supplement. Unfortunately, based on information I was given when investigating Crossref indexing of meeting abstracts, a known limitation in Crossref causes meeting abstracts to be classified as journal articles rather than proceedings. Specifically, the way the Crossref metadata schema is set up, journal content and conference-related content are totally distinct. Anything that’s published within a journal issue and associated with the journal title and ISSN(s) as a container can only be characterized as a journal article.
To register the abstracts as conference material, they’d have to be characterized as conference papers within a conference proceedings volume, not within a journal issue.
Because conference abstracts will invariably be missing much of the metadata this tool is measuring to assign scores, the scores for the abstracts will be very low. This combined with the fact that published meeting abstracts can greatly outnumber true published journal articles, causes the journal score to be dramatically depressed and unrepresentative of the quality of the metadata in the true journal articles.
I need to thank Michael Di Natale for investigating this issue last year.
Ah yes good point that there are always caveats like not all content within a journal container would even have abstracts or references and not everything would have funding at all too. We always emphasise these nuances when doing metadata health checks, and it again emphasises why the percentages of “completeness” aren’t to be read into alone – more of a tool thank a ranking.
Echoing Dan’s comment, the results of this tool are seriously flawed for any journal that publishes conference abstracts in the journal. Due to how Crossref indexes these meeting abstracts, it is not possible for Research Nexus Score to produce accurate metrics for publishers publishing abstracts this way.
Meeting abstracts published in supplemental issues are captured as journal articles in Crossref rather than conference proceedings. They do not get indexed as proceedings. I discussed this with Crossref support last August and was informed that this is due to how their metadata schema is set up. Journal content and conference related content are totally distinct, so anything that’s published within a journal issue and associate with the journal title and ISSN(s) as a container can only be characterized as a journal article. To register the abstracts as conference material, they’d have to be characterized as conference papers within a conference proceedings volume, not within a journal issue, which is not how all publishers operate.
Crossref was said they we’re aware this is a limitation and noted that it was something they’d like to address in future schema versions. I’m not sure where this action currently stands, but it tools are going to leverage the Crossref data base like this then Crossref needs to provide a solution. Research Nexus Score should take this into account as well.
Thank you Daniel, Mike, and Ginny. This is a very useful clarification and exactly the kind of edge case that needs to be handled carefully.
I agree that conference abstracts and meeting abstracts published within journal supplements create a real interpretive challenge. If they are represented in Crossref as journal articles because of the current schema/container structure, then a completeness-based score can be depressed in ways that do not necessarily reflect the metadata quality of full research articles in that journal.
This is also why I think the score should be read as a diagnostic signal rather than as a final judgement or league table. A low score should prompt the next question: what kind of content is being measured, what metadata should reasonably be expected for that content type, and where in the workflow or infrastructure is context being lost?
Ginny’s point is important here: the percentages are useful, but they should not be read in isolation. Crossref is a foundational part of the scholarly metadata infrastructure, but records also move into downstream systems such as OpenAlex, institutional repositories, discovery platforms, and indexing services, where they may be enriched, reconciled, interpreted, or sometimes lose context.
So, to me, the broader question is not only whether a field is present in one source, but how well a scholarly object remains discoverable, attributable, connected, and usable as it travels across the research information ecosystem.
Research Nexus Score should take these cases into account, especially where conference abstracts, supplements, corrections, editorials, peer review materials, or other content types are mixed with full research articles. I see this as part of the broader value of the discussion: it helps identify not only missing metadata, but also where the scholarly infrastructure itself may need better ways to represent different kinds of research objects.
Thanks again for raising this. It will help strengthen the tool and the way the scores are interpreted.



