Many Scholarly Kitchen readers will know Richard Wynne from his time at Aries Systems. He left the company in 2018 and, for the past couple of years, he’s been busy developing a new platform, Rescognito, which he hopes will help transform how researchers are recognized and rewarded for their contributions. We have both been talking to Richard about his new venture and how it ties in with his views on the importance of assertions in adding value to publications. In this interview, he answers some of our questions about this, as well as sharing his vision for decoupling the assertion workflow from the content workflow as one way to simplify the publication workflow for authors and publishers alike.
What problems and opportunities do you see in scholarly publishing?
Let me say out loud what almost everyone involved in scholarly publishing knows: the transition to Open Access will not by itself significantly reduce the cost of publishing, nor is it likely to improve the culture around research incentives. Consequently, there remains a pressing need to reduce costs and improve research culture; but in ways that do not dismantle the proven — but expensive — benefits of peer review and editorial evaluation.
How can that be achieved?
Despite the transition to Open Access, many researchers, librarians, and research funders continue to feel short-changed and profoundly dissatisfied.
Scholarly publishers are perplexed by these complaints because they believe they provide a good service that offers their authors value for money. They consider their internal operations to be efficient and staffed by well-intentioned, hard-working, and appropriately compensated employees. To find the source of this misunderstanding, therefore, we need to analyze publisher costs.
Publisher costs usually include copyediting/formatting and organizing peer review. While these content transformations are fundamental and beneficial, they alone cannot justify the typical APC (Article Publication Charge), especially since peer reviewers are not paid. Missing from this picture is the cost of generating and curating the large number of “assertions” that distinguish a published manuscript from its unpublished version.
What do you mean by “assertions”?
In this context, assertions are explicit or implicit authoritative statements of fact about a document that increases its value to readers and the broader community. Here are some examples: “Who created the document”, “Where was the work done”, “When was it released”, “Who funded the work”, “The statistics are sound”, “It was not plagiarized”, “The document was peer reviewed by anonymous reviewers”, “The findings are supported by the data”, “The work is novel”, “The work builds-on (i.e., cites) other work”, “The authors have these conflicts of interest,” etc.
Think of it this way: the value is not in the content, it is in the assertions — scholarly publishers don’t publish content, they publish assertions. This provides a coherent model to explain why publishers add value even though the source content and peer review are provided for free. Journals incur legitimate costs generating and curating important and valuable assertions.
The problem is that generating assertions is too expensive.
Why do you say it is expensive to publish “assertions”?
For historical reasons arising from the limitations of paper-based dissemination, it has been necessary to (a) encapsulate assertions inside the document itself for delivery to readers and (b) have the assertions be made by trusted, branded gatekeepers to guarantee their provenance.
As it was necessary to combine assertions and content into a single workstream, publishers evolved complex machinery (I call it the manuscript “sausage machine” – illustrated below) to manage the process:
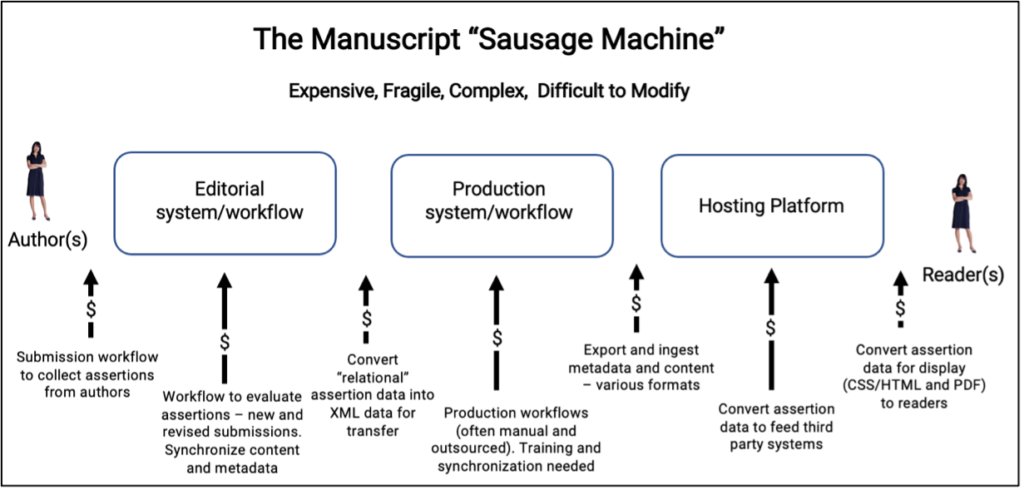
Choosing to make the “sausage” this way is understandably expensive because assertions are “touched” multiple times by multiple teams and undergo multiple data transformations. The entire process has to be coordinated, managed, and synchronized — often over multiple continents.
So, generating and curating assertions is not expensive because publishers are obtuse, incompetent, or evil. It’s expensive because publishers use a process that assumes assertions must be combined into content. By re-engineering this process it could be possible to reduce cost without degrading the integrity of the assertions.
Can you give a tangible example?
Let’s say your organization supports the DORA declaration. Article 8 states that organizations should: “encourage responsible authorship practices and the provision of information about the specific contributions of each author”. In immediate, practical terms this means implementing the CRediT taxonomy.
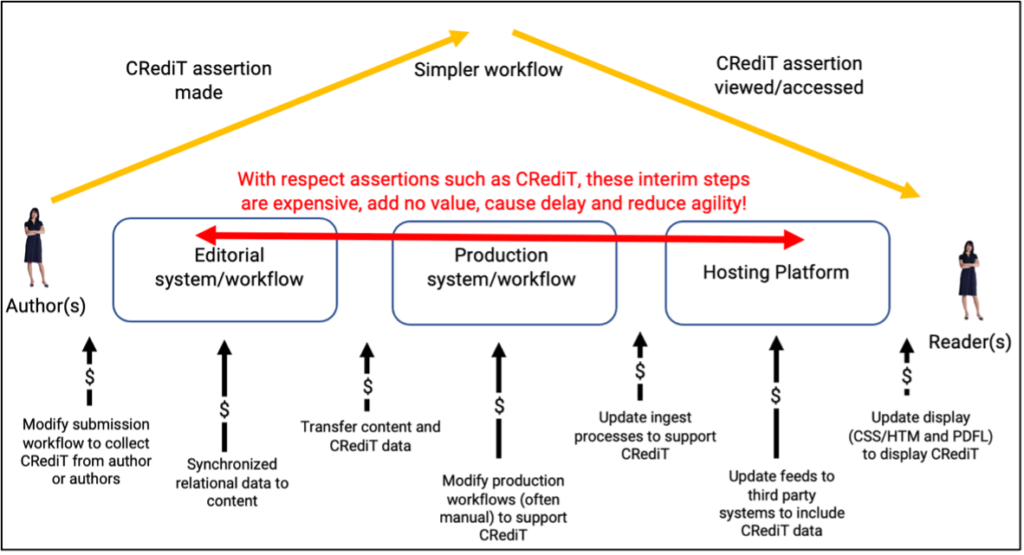
Using the traditional “sausage machine” to implement CRediT, a journal has to (a) modify its peer review submission process to collect CRediT terms from contributors, (b) synchronize CRediT claims stored in a relational database with manuscript content, (c) output the CRediT assertions to their production workflow in a standardized manner, (d) train their production operators to implement CRediT in XML, (e) transfer the XML to a hosting platform, and (f) arrange for the hosting platform to transform and display the CRediT information into useful HTML and PDF display formats.
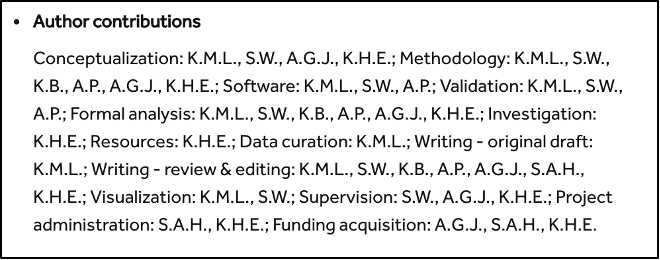
Because the legacy process is so tortuous and expensive, journals understandably take shortcuts. But this results in sub-optimal assertions. In the CRediT example below, the assertions lack specificity, attribution, provenance, usability, and re-usability. What should be a publishing “value add” becomes an informational cul-de-sac.
Fortunately, this process can be re-engineered. Because contributors are verifiably and unambiguously identified by their ORCID iD, a much simpler workflow is available (illustrated below). The author(s) make CRediT assertions, and readers/users view the CRediT assertions.
Using this simpler approach also increases the utility of the assertions by leveraging persistent identifiers. For example, in Rescognito we leverage DOIs and ORCID iDs to display assertions in a variety of formats (e.g., https://rescognito.com/v/10.1111/nph.17214).
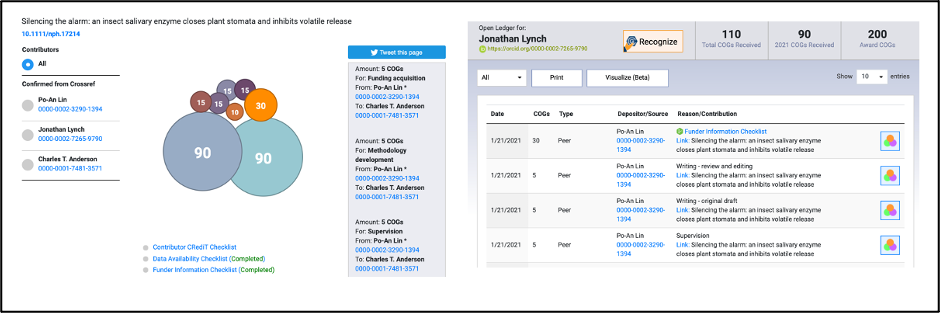
Another benefit of structured assertions is that they can be accessed via APIs (e.g., https://api.rescognito.com/1.0.0/getOrcidCOGs/0000-0002-9217-0407), allowing for integration with third party applications such as CRIS, faculty management, and conference systems.
In other words, decoupling the assertion workflow from the content workflow could massively simplify the process. No data transformations, no XML manipulation, no data synchronization, no DTD updates, no transfer between vendors, no coordination, no training, no management time! In addition, the assertion outputs are superior in granularity, provenance, specificity, display, and usability.
What has been your experience putting these ideas into practice. What feedback have you received?
We developed Rescognito as an Open Access platform where organizations and individuals can make assertions about research outputs and activities, and get recognition for their work through COGs — units of recognition, which can be used for comparison purposes.
For example, any researcher who is issued a DOI via a Journal, Figshare, Zenodo, bioRxiv, or a university Institutional Repository can make supplemental assertions using Rescognito. When this occurs, their Open Ledger is updated. To see examples of recent researcher assertions and recognitions, visit the Rescognito homepage and look for the “recent recognitions.”
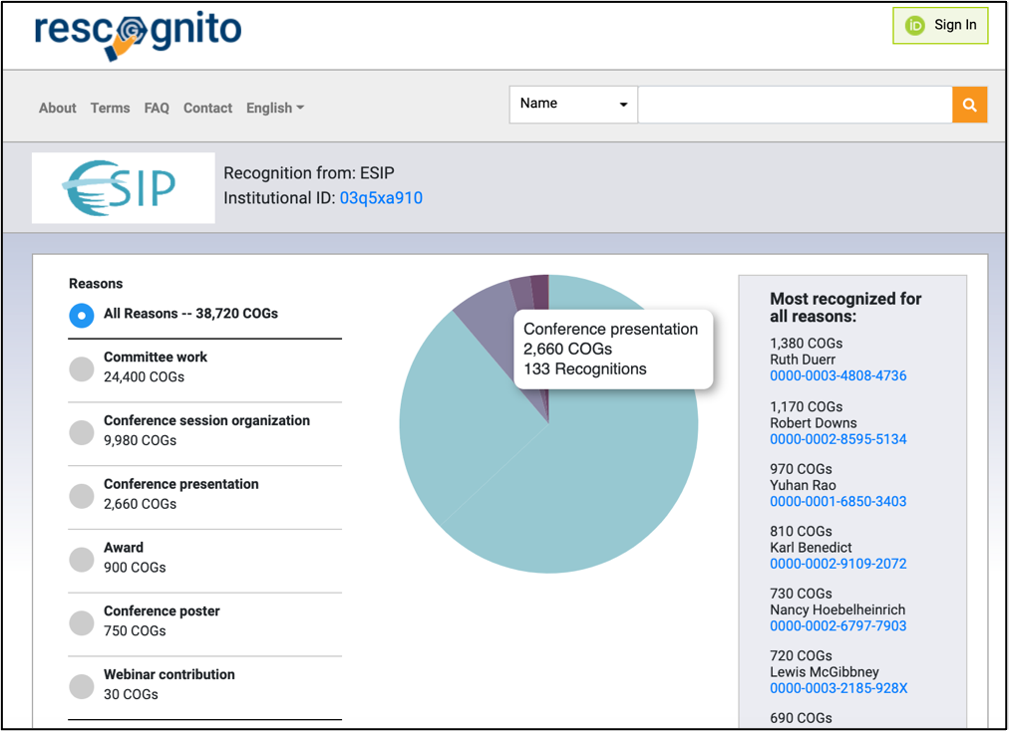
We also make it possible to generate and store assertions about activities that have no proximate physical or digital corollary, such as “mentoring” and “committee work”. By way of example, the Earth Sciences Information Partnership (ESIP) awarded more than 38,000 COGs to hundreds of their members for a wide range of contributions during 2020, including: Committee work, Conference posters, Conference session organization, Conference presentation, and Webinar contributions. These institutional assertions can then be associated with the ROR identifier of the asserting organization. ESIP recognitions can be viewed here and here. Erin Robinson of Co-Founder and CEO of Metadata Game Changers and former Executive Director of ESIP observed: “This is so fantastic!! I love being able to quantify and visualize the community contributions”.
Earlier on you mentioned the research incentive system. How do you see that evolving?
Much has been written about the problems of using citation counting as a measure of research impact. We need something better, something that nudges researchers towards greater accountability and reproducibility. Transitioning to an assertion/recognition model would help in two ways. Firstly, it enables the recognition of contributions that are traditionally ignored because they are outside of the scope of research publication, such as library support, clinical trials management, teaching, or mentoring. Secondly, assertions are more transparent and granular than citations. This creates a fairer picture of individual contributions, which is particularly important for early career researchers. I’ve written more about this elsewhere.
Unlike most (or any?) other systems and platforms, Rescognito is built around -0 and powered by — ORCID. Why is that?
Rescognito is a straightforward idea. It is a trustworthy place on the Internet where individuals and organizations can make assertions about scholarly activities, so ORCID is ideal!
Thanks to ORCID, Rescognito requires no registration, no log-in, and everyone who has an ORCID iD automatically has a Rescognito “Open Ledger” and can seamlessly make and receive assertions.
To see this in action, visit somebody’s Open Ledger and recognize them for a scholarly contribution. For example, you could visit my Open Ledger: https://rescognito.com/0000-0002-9217-0407 and click the “Recognize” button at the top of the page to recognize me for a scholarly activity such as “Positive public impact”.
How do you see the future for assertion workflows?
Scholarly publishers and research funders continue to focus primarily on the transition to Open Access, but embracing a new payment model will not by itself fix customer satisfaction problems or reduce costs. At some point there will be a need to articulate a more coherent explanation of how scholarly publishers add value, and to implement efficient systems that reflect this understanding. Assertion workflows are one possible solution to this problem.


Discussion
8 Thoughts on "Can We Re-engineer Scholarly Journal Publishing? An Interview with Richard Wynne, Rescognito"
I was struck by this rather naïve assertion, especially as Wynne knows better:
“. . . a trustworthy place on the Internet where individuals and organizations can make assertions about scholarly activities, so ORCID is ideal! Thanks to ORCID, Rescognito requires no registration, no log-in, and everyone who has an ORCID iD automatically has a Rescognito “Open Ledger” and can seamlessly make and receive assertions.”
ORCID is full of bogus IDs, perhaps up to 73% of its total. That means millions of spammers might have access to Rescognito to make “assertions” about things like Bitcoin, marijuana, pornography, politics, and so forth.
See: https://thegeyser.substack.com/p/orcid-needs-to-clean-its-room and https://thegeyser.substack.com/p/orcid-wallpapers-over-its-flaws for examples of how ORCID is being abused and misused.
You can already find a Rescognito record for “Hannibal Lecter.”
There is also an interesting one for “Princess Leia Lucas,” a woman with the real name of Linda Haskin-Gologorsky. She peddles brain stimulation and other treatments to prevent Covid, and was accused of forging documents in a divorce settlement and retained on $2 million bail (https://www.mercurynews.com/2017/03/30/woman-who-goes-by-princess-leia-lucas-accused-of-falsifying-documents-in-divorce-court/). The bail was reduced to $532,000, while her mental competency was questioned (https://patch.com/california/fostercity/foster-city-woman-dubs-self-princess-leia-lucas-court-questions-mental). She was ultimately found guilty on multiple counts, and lost an appeal, which is interesting to read (https://casetext.com/case/gologorsky-v-gologorsky), as it reiterates she is “not to be trusted” and has “no credibility whatsoever.” And this from two courts of law.
Basing any open system on the idea that ORCID is providing a bulwark against fraud or fakery is not a great plan, I’d assert.
Kent – ORCID definitely needs better housekeeping, but you’re missing the point. The purpose of ORCID is persistence and uniqueness – NOT identity validation. Identity validation arises over time through network effects created by journals and platforms like Rescognito because we are now able leverage the characteristics of uniqueness and persistence provided by ORCID. It’s not perfect, but it’s a lot better than using a text string to identify contributors.
Well, you said you’re creating “a trustworthy place on the Internet where individuals and organizations can make assertions about scholarly activities, so ORCID is ideal!”
Is it trustworthy when Princess Leia Lucas — a convicted liar using a fake name — can have 20 cogs?
When Godzilla has a ledger?
It’s not hard to find ledgers that are bogus. Is that what you’d call “trustworthy”?
I’m only missing the point because the goal posts seem to keep moving.
No, that’s not what I call trustworthy. I was trying to explain that trust arises through relationships, not through individual self-claims of identity which, as you correctly point out, can easily be fake. One of the purposes of a service like Rescognito is to enable the expression of validated relationships whose existence, over time, can serve to increase trust.
For example, the fact that the scholarly society Earth Science Information Partners recognized this ORCID iD https://rescognito.com/0000-0003-1245-1653 for a “prize” should increase your level of confidence about this iD. If this ORCID now recognizes somebody else, your level of confidence/trust about that third party increases too, etc. That’s what I meant about trust and network effects.
So, I could make a bunch of fake ORCID IDs, use these to cross-promote a central, deceptive one, and leverage network effects in an illegitimate manner, and there’s nothing ORCID or Resognito could/would do about it?
Basically, astroturfing is allowed?
There seems to be a great misunderstanding of what ORCID is.
1. ORCID doesn’t validate identity. It means only that the person submitting an item to which they have authenticated their ORCID iD is in control of that ORCID iD. They demonstrate that control in having signed into that ORCID account and authorising the targetted system to obtain their ORCID iD (and possibly read data on their ORCID record or later add data to their ORCID record). ORCID at no point validates a user’s identity — it doesn’t even require that a user validate their email address before being able to authorise a system to read their ORCID iD.
2. ORCID has decent web rankings (apparently). Spammers trying to use ORCID to advertise their services — and apparently failing as a simple search on a search engine would demonstrate — is different from an individual creating a fake ORCID iD to connect to a fake identity to submit fake research to a real journal.
The former is a failed attempt to abuse ORCID’s positive web rankings to increase SEO. The latter is creating a fake persona, just as one could create a fake email address, affiliation, etc.
Hmm. Things like CRediT roles should already be going in JATS XML and funder information in Crossref XML so you’ll still need XML. I feel like if I were to interface with Rescognito, I would still be building tools based on the content workflow. CRediT and funder information comes from authors anyway, so the logical place for them to input it is via submission metadata or for it to be extracted from the manuscript during production. The result is that the assertion workflow remains an offshoot of the content workflow, which should be already largely automated. I don’t really see how Rescognito can build Crossref XML or JATS XML based on author assertions after publication.
So, the point of including CRediT in manuscript workflows is also to encourage author groups to have this important discussion together and so that each author is aware of their roles as part of a whole, as discussed here: https://www.pnas.org/content/115/11/2557. The writing/revision/editorial process has an important role in facilitating and coordinating this awareness and discussion, including raising questions of who else should be included as an author (or not). Pushing this to each individual author post-hoc is unlikely to serve that important purpose and indeed losses integrity in the assertion. As John notes, ideally the CRediT taxonomy is then encoded in the paper, sent to ORCID, funders, universities, etc. and able to harvested for an integrated display (great). It’s a lot more than just tagging or an individual assertion.



