Editor’s Note: Today’s post is by Hong Zhou with editorial support from Megan Prosser. Hong is Atypon’s Director of AI and R&D, responsible for overseeing the implementation of artificial intelligence–driven information discovery technologies and has published 14 articles for various computer science journals and conferences. Megan is Atypon’s Senior Director of Marketing, experienced at building marketing teams and strategies for high-tech startups and publishing organizations.
In what constitutes probably my least conventional job responsibility, every year I lead a small team of colleagues and graduate students in an intensive, months-long international AI competition — BioASQ. It’s a head-to-head technology challenge among tech powerhouses like Google and Amazon, plus brilliant teams from the NIH and top research universities around the world.
Who wins, you might ask?
Everyone — literally! — given that the goal of the competition is to generate open source AI systems that help advance medical progress. It has been estimated that every 23 seconds or so, a new medical journal article is published, so in theory, anyone wanting to stay on top of the literature would need to read roughly 5,000 a day.
As the BioASQ team describes it, their mission is foremost about helping biomedical professionals access highly specialized information that is dispersed across, and sometimes buried deep within, “hundreds of heterogeneous knowledge sources and databases.”
Beyond its targeted biomedical community mission, this relatively little-known, state-of-the-art-accelerating technology contest addresses a universal challenge particularly relevant to scholarly publishers: discoverability.
We live in an era of information overload. Digital transformation and the information revolution have generated more valuable “needles,” but they’ve also unleashed an exponentially expanding data “haystack.” And that’s a fittingly unsexy analogy for all the painstaking programming work and model building that goes into BioASQ Challenge participation.
What’s thrilling is the end goal, the not-so-distant prospect of researchers, doctors, and even patients being able to get accurate, clear, and potentially life-saving natural language answers to urgent medical questions, à la Star Trek.
For now, on a personal and professional level, BioASQ has not only made it possible for me to do some of the most meaningful work of my career, the competition has also connected me to an extended community of brilliant, dedicated professionals who have broadened my thinking (and become good friends).
Since I couldn’t connect with the BioASQ family in person last year due to Covid, writing this piece felt like a good way to support their mission and generate greater awareness for the Challenge, now in its ninth year. So a few months ago, I reached out to the core BioASQ team to catch up — and learn more.
Neural Networking
“We came up with this nice idea for a competition and infrastructure that would let other people from around the world contribute to our mission,” explained Anastasia Krithara, lead BioASQ organizer and a postdoctoral researcher in machine learning, information extraction, artificial intelligence, and biomedical informatics at Greece’s National Centre for Scientific Research.
Her BioASQ colleague Tasos Nentidis, an associate researcher at Demokritos and Ph.D. student at Aristotle University, joined us on a Zoom call as well. “This year’s Covid tasks really highlight the ultimate goal of BioASQ,” said Tasos. “Our focus is helping biomedical experts be more productive by managing the abundance of useful science that is out there.”
“Information about BioASQ has been disseminated mostly through academic channels and the international natural language processing and machine learning research community,” Anastasia added. “But we really appreciate the opportunity to reach a broader audience and would love to attract more private sector tech companies.”
Personally, I think it would be great if, for example, IBM — doing amazing work in natural language Q&A — signed on to compete. (Although some companies and organizations elect to engage with BioASQ and exchange information on a less formal basis.)
Technology alone cannot replace human knowledge and discovery, of course. But it can accelerate its journey to progress. In that sense, BioASQ is a big rally-style race towards an open-source finish line. And I happen to like races (in fact, my first year out of university was spent developing race car video games for a major British publisher).
Chasing Golden Data
The Challenge’s greatest challenge is the exacting, specialized labor required for creating the “golden data” — the desired needles painstakingly extracted from an open-sourced haystack by the dedicated biomedical experts who do the heaviest lifting each year to make the Challenge possible. The data sets that they compile are natural language questions and answers, plus relevant snippets (sentences from peer-reviewed articles). Competitors create and submit systems that dive into the haystack to try and extract the most useful needles the fastest.
With each BioASQ Challenge task, the central “golden data” can be thought of as the track. A biomedical question becomes the starting flag. A responsive, accurate biomedical answer is the finish. Who can get there fastest by tackling the data with AI? Who can get there again and again and again and again, automatically… without veering off track or crashing?
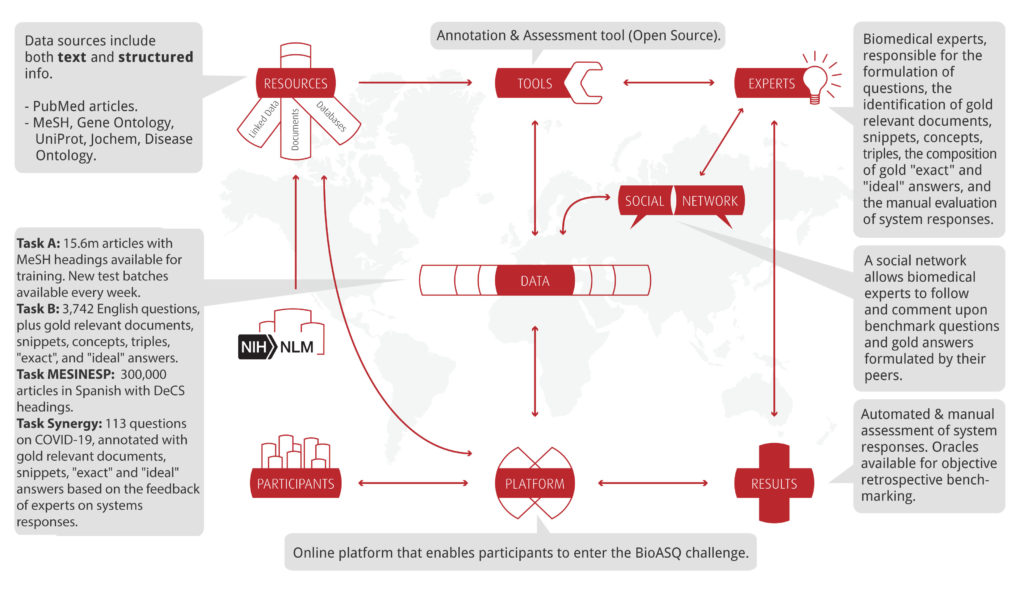
Creating a level playing field for all Challenge participants is imperative. The gold standard that BioASQ’s “golden data” lets us all work towards is a reliable, user-friendly, AI-driven system capable of performing instantaneously what a trained medical professional requires many hours to accomplish. The difference between first place and second place winners is almost always a matter of minute degrees in accuracy.
Traditionally, biomedical research has been made searchable through manual indexing; teams tasked with reading every piece of published literature and summarizing it with an indexing process that’s necessarily time-consuming, costly, and fallible. There is an urgent need for solutions that are more accurate, responsive to natural language, and capable of operating at scale — across all industries, but in particular life-saving ones.
For example, the Medical Text Indexer (MTI) is a tool developed by NLM to assist in the indexing of biomedical literature. Its performance has improved by almost 10% in the last 8 years, largely due to the adoption of ideas from the systems that compete in the BioASQ Challenge. The best performing system in the Challenge functions even better, reaching an accuracy level of 70%, which could potentially support fully automated indexing of the biomedical literature.
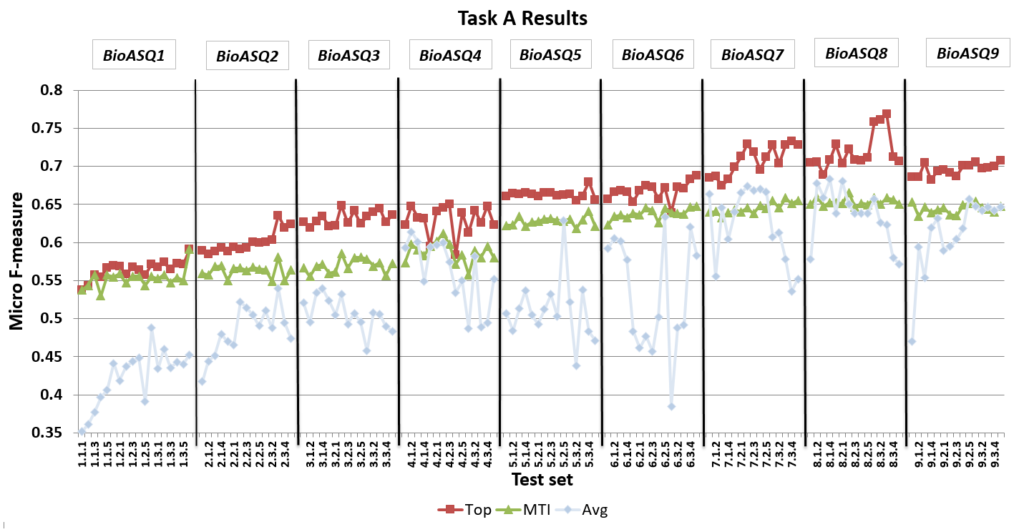 Approaching the point at which AI can perform tasks not only instantaneously but also more reliably than humans is especially exciting and game-changing. Now that finish line — actually, a starting line — is finally within sight.
Approaching the point at which AI can perform tasks not only instantaneously but also more reliably than humans is especially exciting and game-changing. Now that finish line — actually, a starting line — is finally within sight.
And reach.
A two-year project now in its ninth year
“Originally, BioASQ was European. The EU funded a two-year project, from 2012 to 2014, to organize challenges for biomedical semantic indexing and question answering,” Anastasia notes. “But it was so successful, we wanted to keep it all going as an independent entity with sponsors.”
The US National Institutes of Health (NIH) was the BioASQ Challenge’s main patron initially. Google and my company, Atypon, have also been sponsors in recent years.
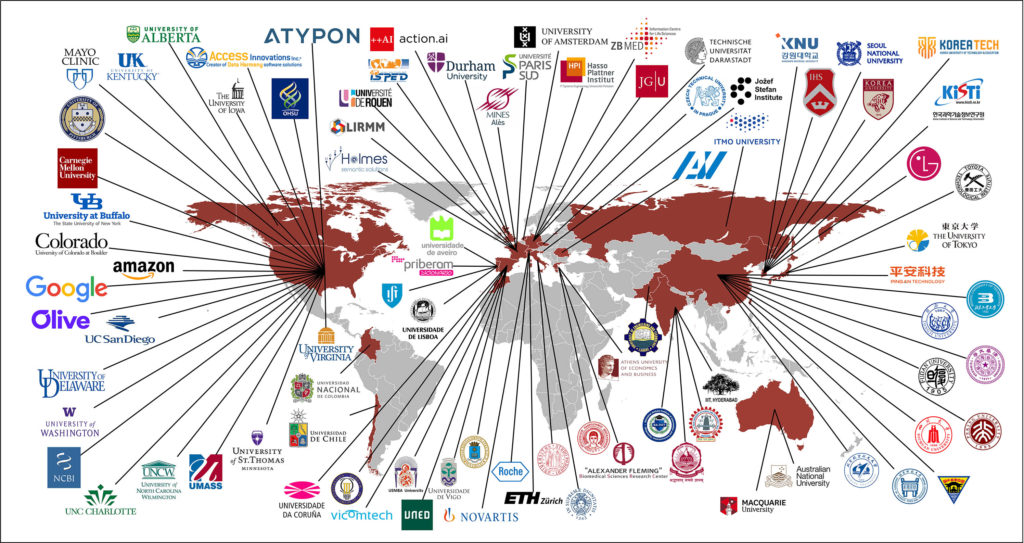
“The NIH’s National Library of Medicine (NLM) has helped us a lot,” Anastasia says. Arguably, no more ideal partner exists. Not only are they the largest biomedical library in the world, NLM is also the tech innovator behind PubMed, GenBank, ClinicalTrials.gov, and MedlinePlus, dedicated to “integrating streams of complex and interconnected research outputs that can be readily translated into scientific insights, clinical care, public health practices, and personal wellness.”
But BioASQ has also helped NLM: specifically, thanks to BioASQ Challenge-winning systems, NLM researchers have improved their Medical Text Indexer, which indexes biomedical literature based on the MeSH (Medical Subject Headings) thesaurus.
The two main tasks from the original Challenge in 2012 continue today: semantic indexing and question answering. A third task was introduced two years ago — automatic indexing in Spanish biomedical literature.
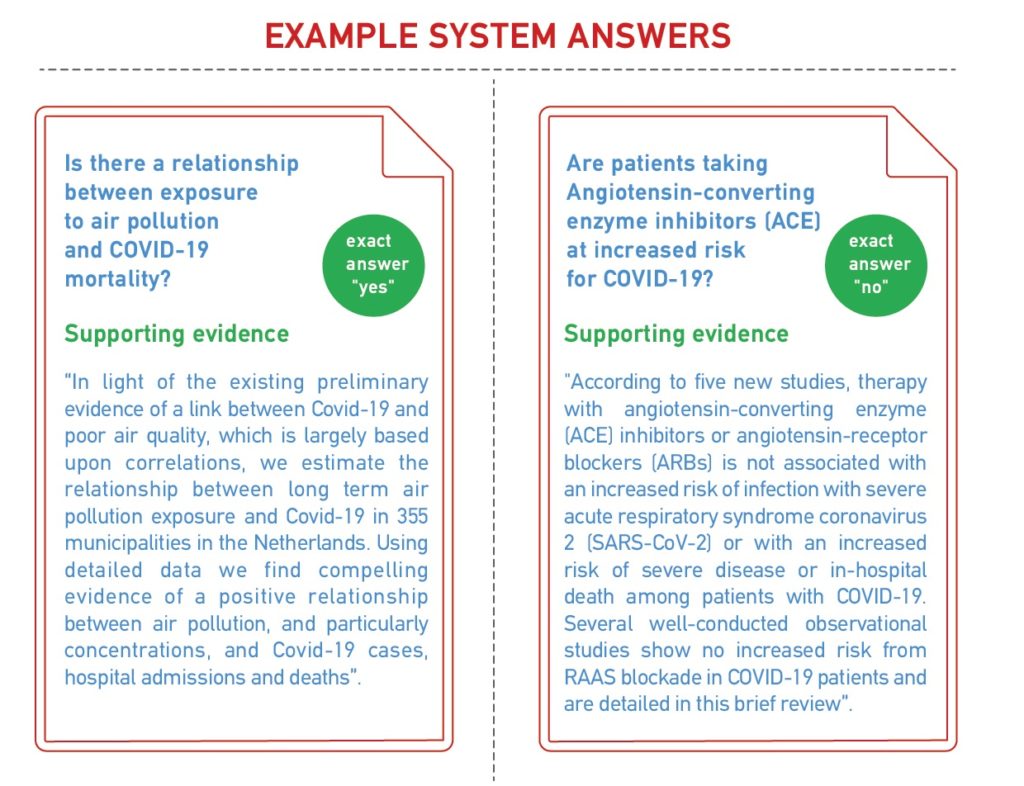
The Challenge’s most recent task (the fourth) is focused on Covid-19 and does not include a data set that’s created in advance “because there are many open questions,” Anastasia explained. “New articles are published about Covid-19 every day and so many questions cannot be answered yet. Or maybe they couldn’t be answered back in, say, September, but can be now because we now have the facts. So we’re quite excited.”
Meanwhile, holding the BioASQ Challenge workshop and awards conference online in 2020, due to Covid-19, led to more attendees than ever before. In previous years, many participants lacked the funding to travel. This time, all they needed was an internet connection.
This year’s challenges are already well underway, with the 9th BioASQ Workshop scheduled for September 21-24th, in Bucharest, Romania, as part of CLEF 2021 — the Conference and Labs of the Evaluation Forum (formerly the Cross-Language Evaluation Forum). For a while there, it looked like attending in person might be back on the table. However, the call was made to have both events be virtual once again.
The silver lining there, I suspect and hope, will be record attendance once again.
The other day, a colleague asked if I hope my team takes top honors again. I said, actually, I want someone to come along and beat us. Then we get pushed harder to come back and beat them!
Not only is healthy competition more fun, it’s more effective.

Discussion
5 Thoughts on "Guest Post — BioASQ for the Win: Inside the Healthiest Competition You’ve Never Heard Of"
Excellent post and initiative, great to hear about this, this is a similar event/competition I have been supporting for 5 years, via a connection through the SSP Fellows mentoring scheme, and being connected with Mohammad Hossein Asadilari the then Managing Director of Canadian NFP STEM Fellowship, each year there’s a different theme, but it’s truly inspiring how the participants both learn data analytics skills, but find stories, passions, insights, and truths from within the data https://stemfellowship.org/undergraduate-big-data-challenge-2021/
Thank you, Adrian! Appreciate the kind words and hearing about this undergrad competition you support. Glad to see challenges nurturing young talent.
One great part of the BioASQ Challenge, for me, has been working closely with talented graduate/PhD students. Their contributions have been indispensable (and their energy helps keep me young at heart).
This piece was a joy to read. Well written and engaging!
Thank you, Candice! (And thanks to my colleague, Megan, for patiently reading drafts and helping shape the piece.)
This is a great post! We are happy to see BioASQ pushing the state of the art forward and inspiring people!
We also have an infographic about our most recent effort, Task Synergy on the incremental understanding of COVID-19: http://www.bioasq.org/project/promotional_material/infographicSynergy
Anyone interested in participating, attending the workshop this September, or supporting BioASQ is welcome!
Stay tuned at http://www.bioasq.org/ and follow @BioASQ on Twitter


