
Author’s Note: This post has been appended with an official response from Wim Meester, Head of Content Strategy at Scopus.
Every metric, like every Greek hero, has its weakness. For the mighty Impact Factor, its Achilles heel can be found in the way citable items are defined and counted. Here, one discovers how the poison arrow of inconsistency plays favorites with some journals while penalizing others.
In this post, I explore how Scopus, a competing product owned by Elsevier, deals with the problem of citable items, highlighting where I think they do a much better job, but also where I think they fail to deliver what they advertise.
We should evaluate Scopus metrics for another, more pragmatic, reason: Thomson Reuters is looking to sell off its Intellectual Property and Science businesses. While one could speculate endlessly on the future of the company that produces the Impact Factor, it is not unreasonable to consider that, in the foreseeable future, we may collectively follow a different metrics hero. Just as the Peloponnesian War was not won over a single battle, Elsevier has been playing a long, tactical game with the development of Scopus and their strategy is paying off.
Like our last post, we begin our metrics evaluation by starting with document classification.
Scopus, just like Thomson Reuters’ Web of Science, classifies papers by document type (see p.10-11). While many document types are identical to the Web of Science, Scopus uses a much broader definition for “Article”, which they define as “original research or opinion,” and may be as short as a one page in length. Scopus also defines a document type called “Note”, which covers discussion and commentary, and another called “Short Survey”, which covers “short or mini-review of original research,” and are usually shorter and contain fewer references than “Reviews”. There is also an “Article-in-Press” document type that is temporary and replaced when the paper is officially published.
For most journals, indexing is not difficult and Scopus assigns the same document type as the publisher; however, there are some journals — most often medical journals — that contain other article types that may not have an obvious designation in Scopus. According to Wim Meester, Head of Content Strategy, Scopus will create a journal “style sheet” for these journals so that their content is indexed consistently. Their solution is not unlike the authority files used by indexers at Thomson Reuters, only that it is the publisher who defines Scopus’ document type, not an independent indexer.
Like Thomson Reuters, Scopus defines the number of citable items by counting Articles, Reviews, and Conference papers. All other article types are considered non-citable. It is not unreasonable that a publisher may wish to define “Article” as narrowly as possible, to highlight just original research but insist that commentary, perspectives and opinions are indexed as “Notes” or “Editorials”. Similarly, publishers can insist that their mini-reviews be classified as “Short Surveys” (non citable) rather than Reviews (citable). Scopus’ document definitions are much too ambiguous to expect consistent indexing across journals, especially when Scopus defers classification authority to the publisher.
Subscribers of Scopus can see how their content is being indexed, yet Elsevier also licenses Scopus’ raw data to third-parties to create journal-level indicators: CWTS Journal Indicators, which is published by the Center for Science and Technology Studies at Leiden University, and Scimago Journal and Country Rank (SJR), which is produced by Scimago Labs. Both sources produce free journal-level metrics.
For comparison sake, I counted the number of citable items published in 8 leading medical journals as reported in CWTS, Scimago, and the Web of Science.
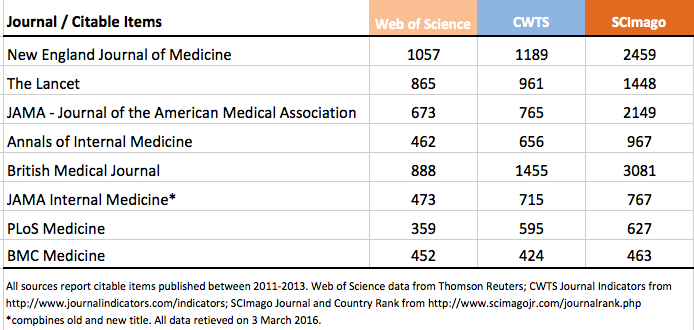
While it shouldn’t be surprising that the Web of Science reports a different number of citable items — after all, it employs a different classification rubric on a different dataset — we should be very surprised that CWTS and SCImago — using the identical dataset and definition — report radically different citable item counts. In some cases, SCImago citable item counts are double what are reported in CWTS. As a result, some journal-level metrics are radically different between CWTS and SCImago.
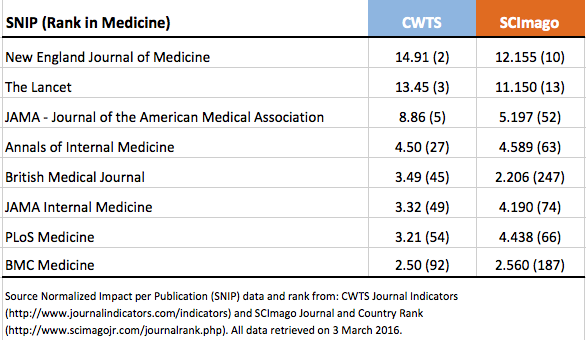
In the next table, I compare the 2014 score each journal received along with its rank among medical journals. The metric consistent between both websites is the Source Normalized Impact per Publication (SNIP). Those interested in how this SNIP calculated can read more here.
Not only will you note different SNIP scores between CWTS and SCImago, but different journal rankings as well. Most notably, the British Medical Journal drops from 45 in CWTS to 247 in SCImago. One should also note that CWTS reports accuracy to the second decimal point, while SCImago reports to the third.
I brought these issues to Wim Meester, who initially responded that the numbers may partially be explained by “the date of calculation and availability of the data at that time.” He also offered that “CWTS and SCImago are the bibliometric experts and own the methodology for calculating the metrics… [They] do their own assessment of the data before doing the calculation, [and] they may also have their own interpretation of the classification in the Scopus data.” I found this response puzzling and problematic, because according to both websites, CWTS and SCImago claim they use the same data source based on identical definitions of citable items and point to the same document describing how to calculate SNIP scores.
Meester then responded that I am focusing on “problematic” journals; however, I spot-checked four other medical journals (Science Translational Medicine, Journal of Clinical Investigation, Radiology, and Clinical Journal of the American Society of Nephrology) and found divergent citable item counts and SNIP scores in all four cases. For the JCI, CWTS reported 1317 citable items while SCImago reported just 1. Further investigation of their dataset, which can be downloaded as an Excel file from the SCImago website, revealed 220 journals listing 10 or fewer citable items published between 2011 and 2013. This can’t be right. Either Scopus has a data integrity problem or its licensing partners are not able to compute basic metrics from their dataset. Either way, Scopus metrics should not be trusted until they can identify and fix some fundamental problems.
After being unable to adequately explain the discrepancies, Meester contacted both CWTS and SCImago and discovered that neither third-party was using the same definition for counting citable items: CTWS was excluding all papers that do not list cited references and SCImago was adding Short Surveys to its citable item count. Meester told me that both parties will be updating their websites to make these details clear to users.
In the end, we are left with three separate sources of Scopus journal-level metrics (Scopus itself, CWTS, and SCImago), all three of which provide different interpretations of the same definition and different calculations based on the same data source. Now, add the possibility that each party may be working with a different version of the dataset and that some versions may contain serious errors.
Scopus has developed a basket of alternative journal metrics, all of which offer improvements over the Impact Factor. At present, however, this basket still suffers from data integrity problems that need to be identified and fixed before anyone should trust their metrics. Yet, even if data integrity problems are solved, Scopus‘ model of allowing publishers to classify their own content and make modifications to its indicators does raise serious concerns.
Meester tells me that Scopus is in the process of developing a new metric that is independent of document types. If it indeed solves their document indexing problem, it does not address their third-party licensing problem, and it is here that we may find mighty Scopus‘ real Achilles heel.
Update (7 March at 9:30am): In preparing this post, I inadvertently confused SNIP with SJR, both of which are based on similar, but not identical, ways of calculating journal performance. Readers are encouraged to read the comments between Ludo Waltman at the CWTS and me for clarification.
Update (7 March at 12:40pm): As my original post included errors, I have offered to give Wim Meester an opportunity to respond in in the main text, rather than risk his comments be lost to readers, I include his response below:
After our correspondence on this topic it is good to read the resulting blog post and see the discussion of document type classification issues and journal metrics. Via this way, I would like to clarify some of the statements in the above post.
I believe that some nuance is lost with respect to how Scopus document type classification is described. In contrast to where it is mentioned, “Scopus‘ model of allowing publishers to classify their own content and make modifications to its indicators”, we in fact do not allow publishers to classify their own content and make modifications. We take the publisher provided classification and match that to our own definition of the document type. While we are open to feedback and/or publisher disagreement with classification, we will not change a document type if it does not match with our general document type definitions.
I would also like to clarify confusion about the reported SNIP ranks in the table. Source Normalized Impact per Publication (SNIP) is a journal metric calculated based on a proprietary methodology developed by CWTS. SNIP measures contextual citation impact by weighting citations based on the total number of citations in a subject field. SCImago does not calculate SNIP values, but calculates a metric called SCImago Journal Rank (SJR). The SJR methodology is developed by SCImago and it is a prestige metric based on the idea that not all citations hold the same weight. With SJR, the subject field, quality and reputation of the journal have a direct effect on the value of a citation. SNIP and SJR are two different type of journal metrics and therefore, their values and ranks should not be compared. More details on these metrics and how they work can also be found here:http://www.journalmetrics.com/.
This approach, the provision of Scopus data to third parties, is not different from how we work with other organization like university rankers who use Scopus data as input for their rankings. For example, Times Higher Education and QS both use Scopus data for their world university rankings, however, the weight they give to citations and the methodology they use to calculate citation impact differs. Therefore, the eventual ranking will be different, although Scopus is used as the citation data source for both rankings.
I think the actual comparison that you are interested in and what we corresponded about is the differences in document counts (sometimes referred to as the “citable items”). Scopus assigns the document type to the data and every year we provide the full dataset to CWTS and SCImago. As described in Ludo Waltman’s response below and the research papers he quotes, CWTS takes the article, review and conference papers and then further excludes those documents that do not contain cited references. That document count is used on the calculation of SNIP. From the same provided dataset, SCImago takes article, review and conference papers and adds “short review” documents to the document count which is then used for the calculation of SJR.
Therefore, I believe it is not the integrity of the dataset but the different methodologies to calculate different type of journal metrics that explains the difference in document counts. Also note that the actual IPP, SNIP and SJR journal metric values that are reported by CWTS and SCImago are exactly the same as reported in Scopus and any other Elsevier sources. These values are consistent and can be trusted.
Finally I do want to thank you for your critical look on document type classification in Scopus and how these are used to calculate journal metrics. If there is one thing I learned from this exercise is that we should even be more transparent and that there is room for a simple, easy to use journal metric that gives credit to every document regardless of how Scopus or anybody else classifies it.

Discussion
14 Thoughts on "Can Scopus Deliver A Better Journal Impact Metric?"
Hi Phil, this is an interesting blog post and I think you are raising some valid issues. However, there is a serious error in your story. You state that “The metric consistent between both websites (CWTS and SCImago) is the Source Normalized Impact per Publication (SNIP).” This is not correct. My center, CWTS, indeed makes available the SNIP indicator, but SCImago makes available a completely different indicator, the SCImago Journal Rank, abbreviated as SJR. SCImago doesn’t make available the SNIP indicator. You also state that “Not only will you note different SNIP scores between CWTS and SCImago, but different journal rankings as well.” Again, this is not correct. SCImago doesn’t provide SNIP scores. It provides SJR scores. Obviously, since SNIP and SJR are different indicators, they have different values and yield different rankings.
My apologies, Ludo. The descriptions of both SNIP and SJR are very similar and I obviously confused them. Thank you for this note. How do you explain differences in citable items–the number that should go into the denominator of these indicators, however?
SJR (SCImago Journal Rank) indicator (from http://www.scimagojr.com/help.php)
It expresses the average number of weighted citations received in the selected year by the documents published in the selected journal in the three previous years, –i.e. weighted citations received in year X to documents published in the journal in years X-1, X-2 and X-3.
SNIP (from http://www.journalindicators.com/methodology). The source normalized impact per publication, calculated as the number of citations given in the present year to publications in the past three years divided by the total number of publications in the past three years. The difference with IPP is that in the case of SNIP citations are normalized in order to correct for differences in citation practices between scientific fields.
The explanation can be found in the scientific papers documenting the SNIP and SJR indicators. In the case of SNIP, please see footnote 13 in http://dx.doi.org/10.1016/j.joi.2012.11.011. In the case of SJR, please see Section 3 in http://dx.doi.org/10.1016/j.joi.2012.07.001, where it is explained that not only articles, reviews, and conference papers are considered in the calculation of SJR, but also short surveys. (Unfortunately, on its website, SCImago incorrectly does not mention short surveys in its definition of ‘citable documents’.)
In your post, you write “we are left with three separate sources of Scopus journal-level metrics (Scopus itself, CWTS, and SCImago), all three of which provide different interpretations of the same definition and different calculations based on the same data source”. You are right that the calculations are different, but it is not correct to say that the definitions are the same. The above-mentioned papers clearly provide different definitions. Likewise, I don’t believe that SNIP and SJR “suffers from data integrity problems that need to be identified and fixed”. The differences that you observe simply follow from differences in the definitions of SNIP and SJR.
I do believe your blog post is highlighting a more general issue that deserves further attention. SNIP and SJR are complex indicators and the details of their calculation are ‘hidden’ in scientific papers, making it difficult for non-experts to fully understand the indicators. This is a difficult problem. Perhaps more effort should be put in trying to explain the indicators in layman’s terms.
Thanks for your constructive and helpful responses, Ludo. I take responsibility for not fully understanding the differences between the three metrics sources, some of which may result from errors on the SJR website, details buried in footnotes of technical papers, and responses from officials. If Elsevier wants users–publishers, editors, and authors…not bibliometricians–to take Scopus metrics seriously, they will need to address the source(s) of my misunderstandings.
Using terminology from a previous post: SJR is a network-based citation metric (AKA source-weighted or eigen-metric), whereas SNIP is based on simpler citation counts (normalized a posteriori to obtain a uniform comparison scale).
While there is a lot not to like about the Impact Factor (and even more about how it is used), one thing I do like about it is that the metric is applied by a party that does not itself engage in publishing the journals that it ranks. Elsevier publishes a large number of journals. Is there any reason to be troubled that the company developing and disseminating this new metric has a very direct interest in the outcome of the measurements it will make?
Yes, which is likely why, despite being around a long time, no one really uses these metrics. In fairness, Scopus provides the data. Two other organizations provide the metric.
The big advantage we see with SJR and SNIP is that the Scopus database is bigger than Web of Science, includes more niche journals, and more international coverage. This helps if you happen to publish other niche journals.
I don’t think the choice of citable items is the only flaw of the impact factor and, indeed, other similar metrics. Another is that the impact factor is too sensitive to outliers. This could be fixed by scoring higher citations slightly less than lower ones, e.g. the 10th citation is worth 0.9 if the first is worth 1. Consider the difference between 95 and 100 citations compared to the difference between papers with 0 and 5 citations – the 96th to 100th citations don’t have so much of an impact on how the paper is perceived. A scaling would mitigate for the effect of a few very highly cited papers and give a better idea of the overall quality of a journal. I’m not aware of a metric that does something like this, but I’d love to hear if there is one.
In my opinion, our first concern ought to be with the weight attached in the academic and research community to indexing and ranking systems and I wonder if such an emphasis is not damaging for the advance of science.
They can give rise to anti-competitive practices and concentration of power, particularly when they are run by commercial publishers. Those systems cannot only be harmful to other publishers, but also have a very detrimental effect on the development of research, particularly in the nurturing of new ideas. This will lead to stagnation and damage of wealth creation. For example, a published journal reporting new ideas may not be recognised due to a conflict of interest with the indexing owned by a major publisher.
Major publishers can deny access to others without offering adequate reasons or the right of appeal, giving preference to their own publications. New journals and book series in particular are at a critical disadvantage.
Ranking authorities in some European countries seem to rely on such systems, which should not be the arbiters of research, in view of their commercial associations.
Large publishers of scientific and technical material are moving into a position that allows them to control the future of scientific and technical information, indirectly becoming the controller of research.
The danger goes beyond the possibility of creating a monopoly or oligopoly. Such a system can perpetuate out of date research forever. It encourages research institutions, councils and other authorities to support obsolete research.
If an indexing and ranking system is needed, would it not be more appropriate for it to be run by an organisation not connected with any particular publisher?
If an indexing and ranking system is needed, would it not be more appropriate for it to be run by an organisation not connected with any particular publisher?
Doesn’t the Impact Factor fit that description? Thomson Reuters aren’t in the business of publishing academic journals.
CWTS and SCImago rankings based on Scopus data. But there is a radical difference in citable item counts between those databases.
If you restrict search to Article, Reviews and Conference papers (considered as citable items) in WoS it shows 1057 items (2011-2013) as given in the article. The similar search was made to Scopus for those years and restricted to the document types and it showed 1870 items. But the CWTS (1189) and SCImago (2459) rankings show two different numbers. I do not know why.


