Discussing the Journal Impact Factor inevitably leads one down a rabbit hole. While the numerator of the ratio (total citations) to the journal is clear enough, the denominator (citable items) causes great confusion, and getting a clear answer to its construction requires real work.
This post is about the Impact Factor denominator — how it is is defined, why is it inconsistent, and how it could be improved.
In their paper, The Journal Impact Factor Denominator: Defining Citable (Counted) Items, Marie McVeigh and Stephen Mann describe how Thomson Reuters determines what makes a citable item. Their guidelines include such characteristics as whether a paper has a descriptive title, whether there are named authors and addresses, whether there is an abstract, the article length, whether it contains cited references, and the density those cited references.
The assignment of journal content into article types is not conducted for each new paper but is done at the section level, based on an initial analysis of a journal and its content. For example, papers listed under Original Research are assigned to the document type “Article,” Mini-Reviews are assigned to “Review,” Editor’s Choice, to “Editorial Material,” etc. The rules about how sections are defined are kept in a separate authority file for each journal.
While the vast majority of journals are simple to classify, consisting mainly of original articles accompanied by an editorial, a bit of news, and perhaps a correction or obituary, for some journals, there exists a grey zone of article types (perspectives, commentaries, essays, highlights, spotlights, opinions, among others) that could be classified either as Article or as Editorial Material.
This is where the problem begins.
Journals change after their initial evaluation and some editors take great liberties in starting new sections, if only for a single issue. In the absence of specific instruction from the publisher, an indexer at Thomson Reuters will evaluate the new papers and make a determination on how they will be classified but does not update the authority file.
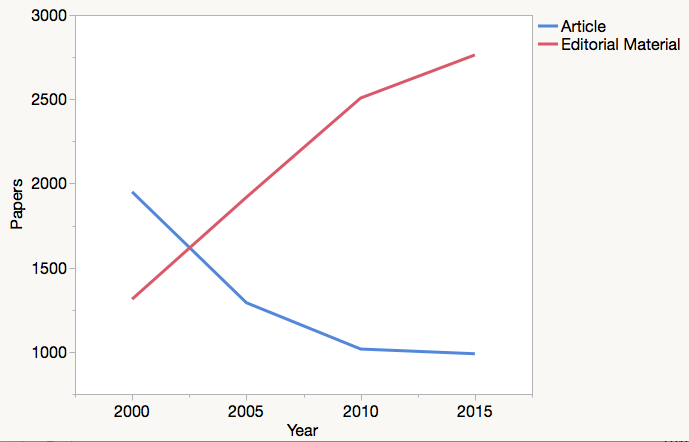
From time to time, Thomson Reuters will receive requests to re-evaluate how a journal section is indexed. Most often, these requests challenge the current classification schema and maintain that papers presently classified as “Article,” which are considered citable, should really be classified as “Editorial Material,” which are not. A reclassification from Article to Editorial Material does nothing to reduce citation counts in the numerator of the Impact Factor calculation but reduces the number in its denominator. Depending on the size of the section, this can have a huge effect on the resulting quotient. For elite medical journals, Editorial Material now greatly outnumbers Article publication (see figure above).
Journal sections can evolve as well, swelling with content that wasn’t there when the section was first classified and codified in the journal’s authority file. The paper, “Can Tweets Predict Citations?” reports original research and included 102 references (67 self-citations were removed before indexing after I called this paper into question), but was published as an editorial and indexed by Thomson Reuters as Editorial Material. The editor of JMIR often uses his editorial section for other substantial papers (see examples here and here).
Thomson Reuter’s approach of classifying by section and revising by demand can also lead to inconsistencies in how similar content is classified across journals. For example, the Journal of Clinical Investigation (JCI) publishes a number of short papers (about 1000 words) called Hindsight, whose purpose is to provide historical perspectives on landmark JCI papers. Hindsight papers are classified as “Article,” meaning that they contribute to the journal’s citable item count.
Science Translational Medicine publishes a journal section called “Perspectives” and another called “Commentary.” These papers are generally a little longer and contain more citations than JCI’s Hindsight papers and are also classified as “Article.”
In contrast, PLOS Medicine publishes an article type called “Perspective,” which covers recent discoveries, often published in PLOS Medicine. While statistically similar by article length and number of references as JCI‘s Hindsight papers, Perspectives are classified as “Editorial Material,” meaning they do not count towards PLOS Medicine‘s citable item count. PLOS Medicine also publishes papers under Policy Forum, Essay, and Health in Action, all of which Thomson Reuters classifies as “Editorial Material.”
What would happen to the Impact Factors of these journals if we reclassified some of these grey categories of papers?
If we reclassified Hindsight papers in the Journal of Clinical Investigation as “Editorial Material” and recalculated its 2014 Impact Factor, the journal’s score would rise marginally, from 13.262 to 13.583. The title would retain its third place rank among journals classified under Medicine, Research & Experimental. If we reclassified Commentary and Perspective papers in Science Translational Medicine as “Editorial Material,” the journal’s Impact Factor would rise nearly 3 points, from 15.843 to 18.598. The journal would still retain second place in its subject category. However, if we reclassified Perspective, Policy Forum, Essay, and Health in Action papers in PLOS Medicine from “Editorial Material” to “Article,” its Impact Factor would drop by nearly half, from 14.429 to 8.447 and have a standing similar to BMC Medicine (7.356).
Should these results be surprising?
If we consider that article classification at Thomson Reuters is determined during an initial evaluation, based on guidelines and not hard rules, is made at the journal section level rather than the individual article level, and requires an event to trigger a reanalysis, we shouldn’t be surprised with inconsistencies in article type classification across journals.
While I have no doubt that Thomson Reuters attempts to maintain the integrity and independence of their indexers — after all, trust in their products, especially, the Journal Citation Reports (the product that reports journal Impact Factors) is dependent upon these attributes — the process created by the company results in an indeterminate system that invites outside influence. When this happens, those with the resources and stamina to advance their classification position have an advantage in how Thomson Reuters reports its performance metrics.
Is it possible to reduce bias in this system?
To me, the sensible solution is to remove the human element out of article type classification and put it in the hands of an algorithm. Papers would be classified individually at the point of indexing rather than by section from an authority file.
The indexing algorithm may be black-boxed, meaning, that the rules for classification are opaque and can be tweaked at will to prevent reverse engineering on the part of publishers, not unlike the approach Google takes with its search engine or Altmetric with its donut score. For an industry that puts so much weight on transparency, this seems like an unsatisfactory approach, however. When classification rules are explicit and spell out exactly what makes a citable and non-citable item, ambiguity and inconsistency are removed from the system. Editors no longer need to worry about how new papers will be treated. When everyone has the rules and the system defines the score, the back door to lobbying is closed and we have a more level playing field for all players.
Under such a transparent algorithmic model, editors may decide to continue to publish underperforming material that drags down their ranking, in principle, because this content (e.g. perspectives, commentary, policy and teaching resources, among others) serves important reader communities. An explicit rule book would also help editors modify such types of papers so that they can still be published but just not be counted as citable items, for example, by stripping out the reference section and including only inline URLs or footnotes.
Understandably, such a move would result in major adjustments to the Impact Factors and rankings of thousands of journals, especially the elite journals that produce the vast majority of grey content. Historical precedent, however — especially when it comes to a metric that attempts to rank journal based on importance in the journal record — should not preside over such necessary changes. Unlike many of my colleagues who decry the end of the Journal Impact Factor, I think its a useful metric and sincerely hope that the company is listening to constructive feedback and is dedicated to building a better, more authoritative product.

Discussion
19 Thoughts on "Citable Items: The Contested Impact Factor Denominator"
Why not periodically check if articles in those sections are being cited? If the citation rate for an “editorial” section is comparable to that for an “article” section then i would certainly think they ought to be considered “citable”! Of course the big problem here is the reliance on Thompson-Reuters to do something sensible…
We’re still left with what is meant to be periodically checked and what a comparable citation profile would look like. This solution also leaves the door of ambiguity open enough for subjectivity, influence, and inconsistency. I think we have to come up with a solution that either removes the human element or adopts a binary definition, like if a paper includes references–meaning, it has the intention to cite other papers–it is citable in itself.
I think the most interesting dimension of this post comes up in the discussion around “black box vs. transparency.” We’ve seen that academics and academic institutions, as well as editors and editorial boards, are often willing to misuse, cater to, and even fraudulently inflate impact factors. This is happening in the current “black box” era (I’d assert the current approach is akin to a black box approach). If the metric increases in transparency, will this lead to better behavior? Or worse? Or just different?
I think more transparency will only lead to more granular private conversations in editorial offices and within editorial boards about what papers to accept, what features to develop, and so forth, along with tools that will allow for scenario-based projections. In a weird way, more transparency could lead to less creativity. At least with a black box, editors are uncertain enough to create features of intrinsic value. If every editorial feature’s extrinsic IF value is predictable, some features may be stifled or stopped, and transparency leads to increased uniformity.
It’s an intriguing set of trade-offs. Do we trust the black box? Do we trust ourselves?
This is a really great discussion topic. At present, TR’s indexing model is neither entirely black-boxed nor entirely transparent, and because of it, we have the worst of both worlds. I agree that both models have their own strengths and weaknesses, but no system is without its caveats.
Thank you for this post. This issue comes up every so often in our editorial board meetings. Editors have questions about soliciting content that is “not counted” for fear of dragging down the Impact Factor. As new kinds of “journals” or journal-like platforms emerge, there are new and creative article types. That’s great–though possibly hard to categorize. Journals should have a way to discuss those categorizations, and in fact we are planning a session at the upcoming CSE meeting on resolving errors or mis-categorizations. This should not be viewed as publishers “negotiating” Impact Factors. I assume it would also be helpful for publishers to clearly define article types in their author instructions. It never occurred to be to tell TR when we add a new type but being pro-active early certainly makes sense.
I’ve always been bothered by these interactions being labeled as “negotiation”. That word kind of strikes me as sending a deliberate message, perhaps part of an unspoken propaganda campaign by those opposed to the Impact Factor in every way possible In my experience, the process is more about error correction. We pre-emptively project the IF for each of our journals, and if TR’s official IF is widely different, we investigate further. Where we think they’ve made an error, or where we think they’ve counted articles that shouldn’t count, we submit evidence to them, and they make a ruling. Sometimes they agree with us, sometimes they realize there’s been a glitch in the system and a correction is posted, and sometimes they decline our request.
That’s not quite the same thing as “negotiation”, where we’re haggling and making trade-offs and exchanges with them. There’s got to be a better, more accurate term that could be used.
Sounds more like an appellate process than a negotiation, for just the reasons you cite. Ranking and scoring systems like this should always have an appeals function. You are appealing their decision, presenting evidence, etc.
How about “advocacy” instead of “negotiation”? Regardless of the label, the risk of favoritism is there, as “those [publishers] with the resources and stamina to advance their classification position have an advantage in how Thomson Reuters reports its performance metrics.”
“Advocacy” still has a ring to it that you’re doing some sort of bargaining, and the way it’s used elsewhere may not be the best fit if what you’re doing is trying to correct a mathematical error. So while it may fit some communications with TR, not sure it’s accurate for all.
Regardless of the label, the risk of favoritism is there, as “those [publishers] with the resources and stamina to advance their classification position have an advantage in how Thomson Reuters reports its performance metrics.”
So, basically, publishers that do their job better than others have an advantage? Should we also penalize publishers with the resources and stamina to do high quality copyediting?
The current system for allocating content between citable and non-citable items is highly problematic. Apparently similar content in different journals is classified differently and this creates a perception that the whole system is open to abuse. So I think there are 3 ways to approach this:
Redesign the Impact Factor – Following the example from Scopus with the Impact per Paper metrics exclude citations both to and from non-citable content. This should align the incentives between publishers, editors and the metric provider. This would require an entire rebuild on the Impact Factor moving from a journal level metric to an article level metric summarised at the journal level, however it would also have the advantage that the Impact Factor would finally match the Web of Science.
Black-Box – If Thomson Reuters could build a true black box this might work. But nearly all of the factors used in the classification would be available to the publisher and as the blackbox would have to fit all 5,000+ publishers, the number of factors it could use would be limited. Springer, Wiley, Elsevier and T&F all have more than 1,000 journals in the Web of Science, each of those publishers could rapidly retro-engineer an approximation of the model using their scale. If the blackbox only included data exportable from the Web of Science then anyone with access to should be able to retro-engineer it.
Open – if Thomson definitively said that any article with factors X and Y will be counted as citable and everything else won’t be then there will be a change in what is published to meet these classifications. Although Impact Factors are far more important metric than they should be, they are a long way from the only factor used in deciding how to structure a journal. If the criteria for to be non-citable are strict enough and consistently applied then this is probably the best method.
Just to expand on the open suggestion.
The criteria need to be strict enough to remove the incentive to try and game the system. I would suggest something like: no more than 2 pages, 3 references, no abstract and either none or very limited author information. Therefore allowing things like news items, short perspectives etc but preventing editors from trying to turn full length articles in to non-citable content. There would be some gaming in edge case such as dropping a 4th reference or tighter editing to keep within these limits.
I agree. While ultimately arbitrary on where you draw the line, the criteria need to be explicit and rule-based, not guideline-based. The rules also need to be applied to every article, not on a section-level authority file that may have not been revised since it was first created. This line of thinking ultimately leads us to using a machine system, not a human one.
I thought that any article with more than 100 references was labeled a “review”, That would mean that classification doesn’t just follow journal sections.
David, can you point to any public document with that rule? Part of the issue I see is that there are no rules–at least I can’t find a public document that states them–only guidelines. As a result, it appears that those guidelines lead to inconsistent classification between journals and over time.
The JCR help file contains information on how the split between Reviews are Articles are made:
“Journal Source Data
The Source Data Table shows the number of citable items in the the JCR year. Citable items are further divided into articles (that is, research articles) and reviews.
An item is classified as a review if it meets any of the following criteria:
it cites more than 100 references
it appears in a review publication or a review section of a journal
the word review or overview appears in its title
the abstract states that it is a review or survey
Other items include editorials, letters, news items, and meeting abstracts. These items are not counted in JCR calculations because they are not generally cited. Data in this column are available only in JCR 2012 and subsequent years.”
Isn’t the numerator somewhat arbitrary too? It usually changes only gradually (see Phil’s previous posts on JIF “inflation).
If you compare citations counted by TR to those counted by other citation counting services, you can see the decision on what sources to include is a decision that each counting agent is making. And these decisions are made in different ways, and at different times.
Presumably the decision to include PLOS One as a citation source must have driven up the number of citations in the ecosystem. (40,000 papers/year, 50 cites/paper, added about 2M citations to the system in each JCR citation year?) That’s like a gravitational wave in the citation universe…
John
Good point. Over the years, Thomson Reuters has been indexing more journals (especially between 2008-2010, see Figure 1, page 7 from http://arxiv.org/pdf/1504.07479v2.pdf ) and this will naturally have an effect on inflating journal Impact Factors. The distribution of citations, however, is not normally distributed and adding more marginal journals tends to have a larger effect on the elite journals, echoing the Matthew Effect.



