A figure in Judy Luther’s recent post on the state of preprints caught my eye (and was noticed by several commenters). The figure (below), comes from the ASAPBio site, and shows the remarkable growth of preprints in the life sciences. What was interesting to me was the inclusion of several formal journals mixed in with the usual preprint servers, notably F1000 Research, Wellcome Open Research, and The Winnower. This raises significant questions about just what, exactly, we consider a “preprint”.
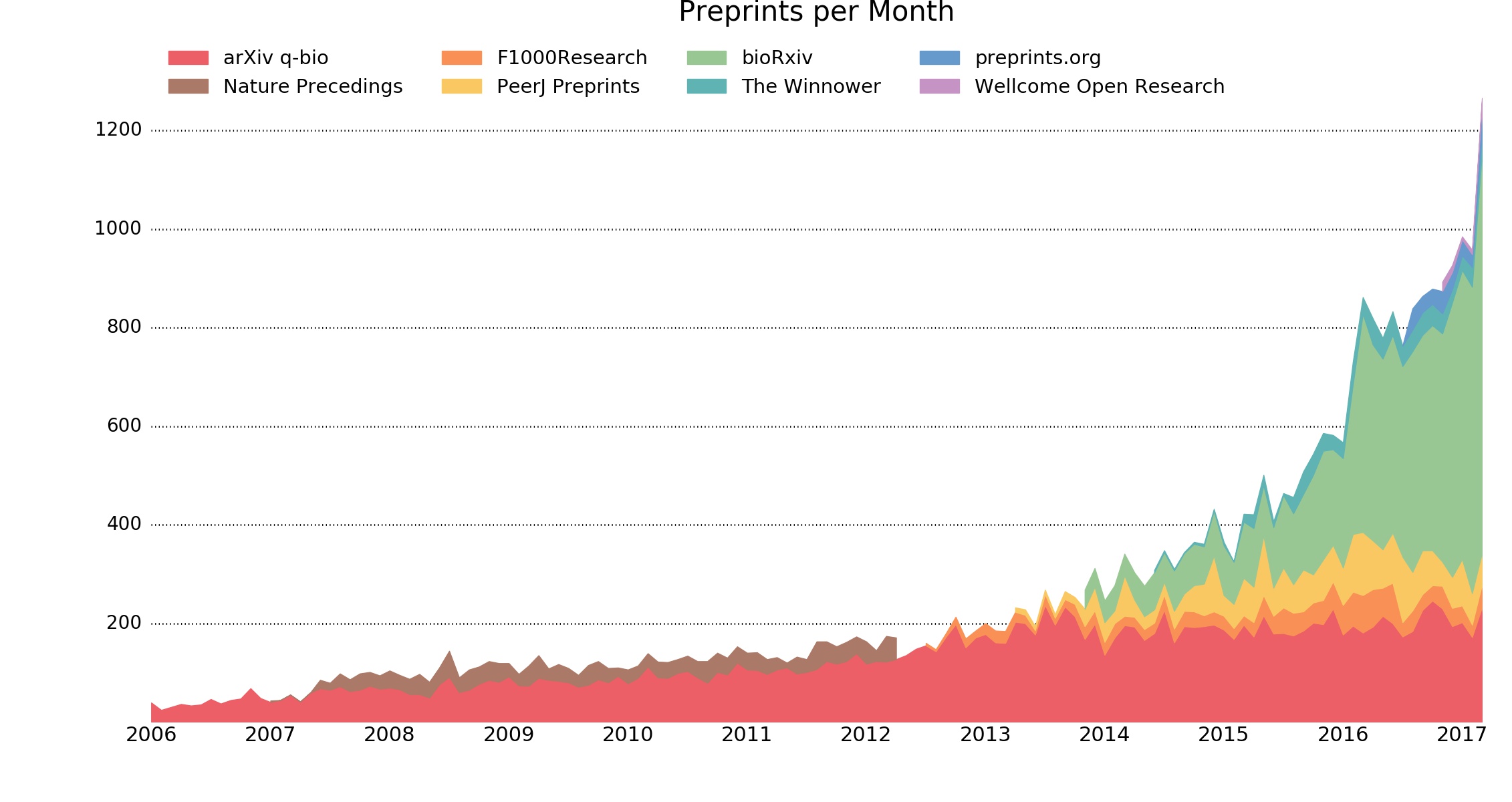
ASAPBio’s definition of a “preprint” can be found here. ASAPBio seems pretty inclusive in the different types of models they consider preprint servers. Jordan Anaya, who is credited in the figure agrees, “…that F1000Research and Wellcome Open Research are not preprint servers in the sense of bioRxiv, PeerJ Preprints, and preprints.org,” but still felt they were worth including in the PrePubMed search tool. Wikipedia offers a fairly concise definition for preprints:
In academic publishing, a preprint is a version of a scholarly or scientific paper that precedes publication in a peer-reviewed scholarly or scientific journal. The preprint may persist, often as a non-typeset version available free, after a paper is published in a journal.
The key to the definition of “preprint” is in the prefix “pre”. A preprint is the author’s original manuscript, before it has been formally published in a journal. One of the primary purposes of preprints is that they allow authors to collect feedback on their work and improve it before submitting it for formal peer review and publication.
The three journals mentioned above (and presumably the new Gates Foundation flavor of F1000 Research) all work on a post-publication peer review model. The author submits a manuscript, and after some editorial checking, it is officially published online in the journal. At this point, the peer review process begins. Regardless of whether the paper is accepted immediately, revised multiple times, or ultimately rejected, it is considered “published”. The author cannot withdraw the article and submit it to another journal.
This is “post”, not “pre”. Once the manuscript goes live, it is considered “published”, and peer review is “post-publication”. It’s worth noting that you will not find the words “publish” or “published” anywhere in bioRxiv’s documentation — they scrupulously use the words “post” and “posted” instead to differentiate what’s happening from formal publication in a journal.

If a journal like Cell or Nature posted a free copy of the author’s original submission alongside the published article, would they also be considered preprint servers? Speaking of Cell, what are we to make of Cell Press Sneak Peek? Essentially, authors who submit to Cell can have their manuscripts publicly posted on a special Mendeley group open to those willing to register. Does this make Mendeley (and Cell, for that matter) a preprint server? What about journals that practice open peer review? As part of this practice, each iteration of the article is often posted, along with reviewer comments and correspondence. Are these to be considered preprint servers as well?
The key to the definition of “preprint” is in the prefix “pre”.
As new ground is broken and new models arise, new terminologies and new definitions become necessary. Preprints are generally being presented to the research community as a way to get their work out quickly, while not hampering, in any way, one’s ability to publish the work in a journal that will provide maximum career benefits. Mixing in journals that formally publish the preprint version of an article and do not allow re-submission elsewhere muddies the water about just what a preprint is supposed to be.
Getting the terminology right has implications for how research is communicated and the trust it engenders. Already, this fuzzy terminology around preprints is sowing confusion. Take, for example, this article from a recent issue of The Economist. The Economist appears to be both muddling open access and preprints and suggesting that science move to using preprints in place of journals, eliding the fact that preprints are not peer reviewed.
Post-publication peer review models are interesting and valuable additions to the landscape, but they are, by definition, publication models, not pre-publication servers. If we want to drive the use of preprints by researchers, we need to be clear about what we are asking them to do.

Discussion
18 Thoughts on "When is a Preprint Server Not a Preprint Server?"
I had a go at defining a preprint at https://researchpreprints.com/2017/03/16/what-is-a-preprint/ and got as far as “a piece of research made publicly available before it has been validated by the research community”. This would include the examples of more restrictive services you mention above, but at the same time I haven’t added them to the list of preprint servers at https://researchpreprints.com/welcome/preprintlist/, mainly because they typically don’t identify themselves as preprint servers. For trying to say what a preprint server is, I think it it comes down to a list of desirable functions, of which most don’t tick all the boxes. More discussion about topic this is certainly needed! For disclosure, I am Director of preprints.org.
The work of Jordan Anaya is admirable but he (and in fact, the research and publishing community) clearly needs to get his definition straight. As a result, his graph is misleading in that includes post-prints and other publications that are not really preprints (blog-like posts), and is incomplete as he excludes preprint servers which should not be excluded. For example, http://preprints.jmir.org (which he currently does not include) hosts preprints of papers for open peer-review purposes (which is one of the original ideas behind preprints, see http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.143.3045&rep=rep1&type=pdf), but for accountability purposes only abstracts are displayed, to download a preprint and comment/peer-review on it a (free) user login is required (see https://jmir.zendesk.com/hc/en-us/articles/115001350367). We found that authors are less nervous about having their work “stolen” when they know that we track who accessed it. Does this still meet the NIH guideline that preprints should be “publicly available”? We think so, as a simple login/email authentication is not really a “barrier” for access. I agree with the definition by Martyn Rittman at https://researchpreprints.com/2017/03/16/what-is-a-preprint/ regarding availability. What is “public” and constitutes “publication” is often a grey area, as I mused about 17 years ago (http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.143.3045&rep=rep1&type=pdf)…
I did not intend for my graph to suggest what is and is not considered a preprint. I simply graphed what articles I had indexed. When I was contacted to update the graph I could have removed servers which are not really preprint servers if that was desired.
The goal of PrePubMed was/is to index biology articles which are not yet indexed by PubMed, hence the name. This includes both actual preprints, and other articles such as those at F1000Research which only get indexed by PubMed after peer review. With that said, the librarians at the University of Pittsburgh also developed a tool to search for preprints and also decided to include F1000Research: http://www.hsls.pitt.edu/resources/preprint, suggesting there are at least some scholars who might classify these articles as preprints.
Preprint confusion has a long history. In the mid-2000’s, NISO assembled a working group to attempt to standardize the terms used by publishers, librarians, and researcher (see: http://www.niso.org/publications/rp/RP-8-2008.pdf). I should note that the group recommended against using the ambiguous term “preprint,” settling on clearer and more descriptive terms, like “Author’s Original”, “Submitted Manuscript Under Review”, “Accepted Manuscript” and others.
Fuzzy terminology is indeed a problem, especially when it is based on concepts that we surely left decades ago. Pre -“prints” when print has essentially disappeared? Accepted “manuscript” when journals will certainly not accept any submission written by hand?
I think the language is less the problem here than a clearer conceptual framework. Language evolves, for example we still “dial” a phone even though I can’t remember the last time I saw a phone that featured a dial.
On that note, I particularly enjoyed this video of children trying to figure out the first iteration of the iPod:
https://scholarlykitchen.sspnet.org/2015/07/31/the-evolution-of-language-when-is-a-phone-not-a-phone/
Despite the iPod not having any communication functions, every single child in the video refers to it as a “phone”, which appears to be evolving into a term meaning “the small computer I carry around in my pocket.”
Great posts today and yesterday. We offer some information on our (Center for Open Science) efforts in preprints with a blog post today: https://cos.io/blog/public-goods-infrastructure-preprints-and-innovation-scholarly-communication/ . In addition to the services that Judy mentioned, we announce new preprint service partnerships for law, marine science, contemplative sciences, ultrasound, paleontology, and with SciELO for Latin America and other regions they serve.
You touch on it a little bit here, but it would be great to see a post solely devoted to open peer review, the advantages of which seem to be more idealistic than practical, and the problems it causes for authors who can’t resubmit rejected work much more apparent. Things get very fuzzy here, too–for example, when is a rejected manuscript to an open peer reviewed journal revised “enough” to be considered a “new” paper, thus eligible for submission elsewhere? Should journals consider changing their policies around this and how we define “published,” or is what’s currently in place already fair? I hear these conversations happening more and more lately.
I think it’s important to differentiate between open peer review and post-publication peer review. Here we are talking about the latter, where journal like F1000 Research posts the manuscript and then (hopefully) at some point someone will peer review it and accept/reject it. Open peer review simply means that the reviewers sign their names to the reviews and these are published alongside the accepted and published paper (articles that are rejected do not have their reviews made public). There are lots of journals that do this as part of the traditional pre-publication peer review process. It is also possible (and I think F1000 Research does this) to do both — the post-publication peer reviews are signed and made public.
Each model has its strengths and weaknesses. Open peer review usually results in more polite, better-written reviews. If you know what you’re saying is going to be made public, people put more effort into it. It’s also great to be able to read reviews on a paper where you’re wondering “how the heck did this get through peer review?” and to get to see who approved it. On the downside, it can have a chilling effect on reviewers — if you know your review is to be made public, and it’s for a paper by someone powerful in your field, how free will you feel to criticize their work? Are you damaging your career by publicly calling out someone in a position of power (or someone who may rise to power while holding a grudge against you)? For this reason, many reviewers shy away from open peer review, preferring instead the ability to speak truth to power conveyed by anonymity.
The post-publication model has its advantages in getting the work out and discoverable immediately, and allowing for continued versioning to fix any flaws in the paper as it receives review. It can be problematic as there doesn’t seem to be the same level of editorial drive to find reviewers as one sees for a pre-publication process. The journal has already been paid, so there’s little financial impetus to dig out reviewers. One sees papers sitting for years in these journals unreviewed or only partially reviewed. The other issue is what happens when a paper is rejected. It cannot be submitted elsewhere, and sits publicly announcing a failure on the author’s part, not something they can put on their CV or use to move their career forward. When a paper gets rejected, the author can revise and then try to get it reviewed again, but you end up in the same position as above, where it may sit for a long time (or forever) before anyone comes back to it for more review.
“Open peer-review” is another ill defined term, and different people may mean different things. Some possible meanings of “openness” are a) “transparent” peer-review, where peer-reviewers don’t stay anonymous (what David Crotty alludes to), b) “participatory” peer-review, where papers/submissions/preprints are “open” for everybody to review or comment on. It is hard to implement b) without a), but a) can be done without b). See also https://jmir.zendesk.com/hc/en-us/articles/115001908868
David, thanks for pointing out the clarity in terminology. I was referring to post-publication peer review (as in your example with F1000 and your last paragraph), but perhaps using the wrong term. I’d be interested to see a post dedicated to this in the future, to discuss more fully some of the implications that you mention.
We looked at this model a while back:
https://scholarlykitchen.sspnet.org/2013/03/27/how-rigorous-is-the-post-publication-review-process-at-f1000-research/
As well as some of the issues around their relationship with PubMed and several funding agencies:
https://scholarlykitchen.sspnet.org/2013/01/15/pubmed-and-f1000-research-unclear-standards-applied-unevenly/
https://scholarlykitchen.sspnet.org/2013/04/25/seeking-acceptance-at-f1000-research-early-problems-with-identity-and-outsourced-authority/
https://scholarlykitchen.sspnet.org/2013/05/13/redundant-and-expensive-how-f1000-researchs-model-reveals-the-root-problems-of-pubmed-central/
https://scholarlykitchen.sspnet.org/2016/07/20/wellcome-money-involvement-with-f1000-opens-door-on-sketchy-peer-review-cois-and-spending-decisions/
David, thanks for this thoughtful article. I fully agree that F1000Research and Wellcome Open Research are not preprint servers, but from the perspective of a researcher looking for new scientific work, restrictions on where a paper may be subsequently peer reviewed are largely irrelevant. Therefore, Jordan’s decision to index these papers along with those on bioRxiv, arXiv, etc serves the needs of readers who simply want to find work before it appears on PubMed. In this light, I’d argue that accessibility, preservation, and screening protocols are more relevant for deciding what should be indexed than commitment to a particular peer review venue.
More broadly, I completely agree with you about the necessity of more thoughtful discussion about the meaning of the term “preprint,” ideally in a way that doesn’t stifle new experiments while offering some clarity for authors and those making and enforcing policies. This is the type of conversation ASAPbio hopes to foster with the creation a community governing body for our planned aggregation service (http://asapbio.org/benefits-of-a-cs).
Disclosure: I’m director of ASAPbio.
Hi Jessica,
I do understand why ASAPBio’s inclusive approach here makes sense — there are preprints to be found available through these journals. But as someone who spends way too much time explaining the very basics of what Open Access is to research societies (yes, nearly 20 years later), I can see a similar sea of confusion on the horizon for preprints, despite their obvious utility and benefits. I think there may be something in the idea of separating out the concepts of distribution from verification which get muddled in the post-publication peer review model.
Interesting to come across this post, right after finishing an article titled “Why the ArXiv of the future will look like Authorea” (https://www.authorea.com/users/3/articles/168733-why-the-arxiv-of-the-future-will-look-like-authorea). I am a recovering astrophysicist and I used the ArXiv extensively throughout my career. I think that the biggest challenge and opportunity for the growing pre-print movement is not around terminology (the line between pre- and post- is blurry and will become invisible eventually) but around formats. At Authorea, we are working hard to bring preprints beyond the static data-less PDF.
Another concept that would deserve clarification is “being peer reviewed”. Because what you, we, mean by that is more accurately “accepted by an editor of a journal recognized by the community as legitimate”, rather than the act or content of evaluation by peers itself.
That might bring into discussion the enormous role we yield to editor’s prerogative, and journal prestige, though. Especially when the peer reviews are opaquely solicited, read, and used by a single person.


