
F1000 Research is a new initiative on the science publishing landscape – something like an article-hosting service with post-publication comments. Papers that not approved by enough commenters are rejected, in that they are no longer publicly visible. The article processing charges (APCs) vary between $250 and $1000 dollars per article, with the price depending on article length.
PubMed is sufficiently impressed that they include approved F1000 Research articles in their searches, but just how thoroughly are their papers being vetted? Here, I compare a few features of the post publication review process at F1000 Research with pre-publication peer review at four high-ranking medical journals.
Most strikingly, commenters at F1000 Research made very little effort to improve the paper — F1000 Research comments were typically short and positive, whereas pre-publication reviews at the medical journals were longer and more negative. The figure shows the average word count by recommendation for the first review in 25 recent submissions to the medical journals (total = 100), compared to 25 from F1000 Research.
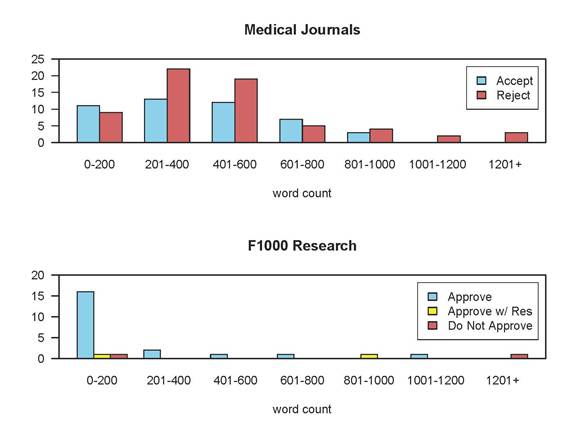
Of the 25 reviews in F1000 Research, 18 were under 200 words (four had zero words), and 21 (84%) were positive. The average length was 254 words. By contrast, the average length for the medical journals was 464 words, and only 42% were positive.
Maybe the F1000 Research commenters were inexperienced, and did not understand how to write a full-length review? Not so. The average h-index of these 25 F1000 Research commenters is 24.7, which implies a long and distinguished publication record. It appears that the journal is actively encouraging the F1000 Faculty Members to provide reviews, but even when these 12 people are excluded, the average h-index of the F1000 Research commenters is still 18.7. All of these commenters know how to review a paper in the traditional pre-publication setting.
These 25 F1000 Research papers are unlikely to be perfect, and some probably contain major flaws. These commenters would very likely have asked for more improvements had they been writing pre-publication reviews. Why did so many of them just click “Approve” and wave the paper through mostly unchanged?
First, the editorial policy of F1000 Research incentivizes short, positive comments:
Referees are asked to provide a referee status for the article (“Approved”, “Approved with Reservations” or “Not Approved”) and to provide comments to support their views for the latter two statuses (and optionally for the “Approved” status).
Approving a paper is thus the path of least resistance.
Another problem facing commenters is motivation – the article’s horse has already bolted into the public domain. Attempting to shut the stable door by detailing the flaws isn’t worthwhile, and the authors are unlikely to make any substantial changes in the light of their comments (Gøtzche et al found a similar problem for Rapid Responses at BMJ.
In addition, writing a negative report may upset the authors. Nobody would take an anonymous comment seriously, so the comments have to be signed. The choices for a flawed paper are thus be nice and give it an approval, or write up an honest evaluation and risk a fight. This design pressures commenters to keep their comments positive.
In pre-publication review, you know that your comments will be evaluated by a senior figure in your field (the editor), and their opinion about you can affect your career. There’s also real risk that a weak review will get shot down in the decision letter: “I have chosen to ignore the superficial review of referee 1, and instead have based my decision on the more comprehensive and critical comments of reviewers 2 and 3”. Ouch.
There’s no equivalent of a deciding editor at F1000 Research (three “Approvals” are all that is required), so while there’s a risk that someone will dismiss your review, the probability that it’s someone whose opinion you care about is much lower. It’s also much less likely that a short, positive assessment for F1000 Research will be the odd-one-out, as long, negative reviews are so much less common. Lastly, in pre-publication peer review, the editor will be reluctant to recommend acceptance if he doesn’t think the paper has been thoroughly examined, but this quality control step is absent at F1000 Research.
Another crucial point is how the prospect of rigorous peer review affects the motivation of authors. Knowing that their paper is likely to be scrutinized by experts in their field drives researchers to eliminate as many errors as possible. This motivation may be absent for authors preparing to submit to F1000 Research, as it is readily apparent that most comments are short and positive. The combination of a lack of care from authors and lack of scrutiny from reviewers may allow badly flawed papers to get the stamp of approval.
More broadly, does it actually matter if online commenting doesn’t replicate pre-publication review? If the papers are getting “approval” from experts in the field, does it matter that the papers still contain errors that might have otherwise been caught?
Reading and reviewing are not the same activity. Reviewers typically start with the position “this paper is flawed and should not be published” and expect the authors to convince them otherwise. Reading a paper is different, and is more focused on how the questions and conclusions relate to your own research. The time commitment involved is also very different — a quick poll around some postdocs and senior PhD students found people spend 6-10 hours reviewing a paper, but only 30-90 minutes reading an article before deciding whether to cite it in their own work.
When researchers are reading a paper, they work from the assumption that someone has gone carefully through it and helped the authors deal with a significant proportion of the problems. This last assumption cannot safely be made for F1000 Research papers, because there is no way to know whether the “Approve” recommendations mean there are no errors in the paper, or that the commenters did not look very hard.
Responsible researchers should therefore approach every paper from F1000 Research as if it has never been through peer review, and before using it in their research they should essentially review it themselves. This imposes a new burden on the community — rather than take up the time of two or three researchers to review the paper pre-publication, everyone has to spend more time evaluating it afterwards.
There may also be an irony here. Authors opting to use F1000 Research to publish as fast as possible may find that uptake comes slower while everyone else finds time to check over the article. Lingering doubts over reliability may also mean that many ignore the work altogether.
There are a few tweaks that F1000 Research could make to ease these concerns. First, their editorial board lists many exemplary researchers, so why not use their expertise in a more “editorial” rather than a “commenter” role? People giving casual approval to flawed papers would then have much more reputation at stake.
Second, the editorial policy of making “approval” the path of least resistance combined with collecting APCs for approved papers means that F1000 Research flirts with predatory OA status. This is unfortunate and unnecessary. Why not switch to a submission fee model? This makes particular sense for F1000 Research as most of their services are provided pre-approval anyway; it would crucially detach approval decisions from financial reward.
A closing thought — the progress of science does not depend on how many articles are published and how quickly. Instead, progress depends on how well each publication serves as a solid base for future work. Gratifying authors with positive comments and instant publication may be a successful business model, but we will all lose out if the ivory towers are increasingly built with sand.
* The journals contributing to this analysis were the New England Journal of Medicine, CHEST, Radiology, and the Journal of Bone & Joint Surgery. Thanks to the staffs of those journals for their help, to Kent Anderson and Elyse Mitchell for their assistance in collecting the data, and to Arianne Albert for the figure.


Discussion
46 Thoughts on "How Rigorous Is the Post-publication Review Process at F1000 Research?"
Tim, you’ve illustrated that F1000 Research is not operating peer review like top medical journals. But in their defense, they are not claiming that they are running their service like a top medical journal. What is the risk of this model? It is certainly not “predatory” as there is no deception going on.
As one solution, you propose using experts (F1000 faculty) as reviewers rather than “commenters,” but I wonder if there is an incentive issue here. Can F1000 Research really expect experts to put the same time and effort into reviewing “uninteresting” papers? If F1000 Research required that each paper received a thorough pre-publication-like peer review, I imagine that many of the papers would sit unreviewed and eventually be deleted from their system. Perhaps the people at F1000 have a realistic sense of what they can ask their reviewers to provide?
The “deception” is deeper than misleading people, and that’s what is so bothersome to me about the F1000 Research model. They claim to publish only “scientifically valid” studies, but those studies have not undergone peer-review when they are published, so how do they know? They charge an APC, but the articles they put out there may not actually stay, and may be taken down, so they don’t stand behind what they publish. They offer indexing as a carrot for “acceptance,” but what “acceptance” means isn’t clear, and the incentives for “acceptance” are a bit off.
To me, F1000 Research abuses terminology to promulgate a deception — “publish,” “review,” “acceptance,” and “scientifically valid” are all terms they’ve shifted slightly to suit their purposes, and I think the composite effect is somewhat deceptive to both readers and authors. What authors are really paying is a submission fee, the articles can’t be assumed to be scientifically valid because they have not been peer reviewed, the review is not up to normal standards we all expect and execute ourselves, and the acceptance can occur with zero feedback and is incentivized improperly.
Hi Phil,
I’m of the opinion that all papers that are ‘published’ and (for example) listed in PubMed should have been through rigorous peer review at some point. The fact that the paper isn’t very interesting does not mean that the community or journals can shirk that responsibility.
F1000 Research is using its faculty members as commenters (almost 50% of the 25 comments came from faculty members). I was suggesting that they instead give them the final say on whether a paper should be ‘approved’ – i.e. the buck would stop with them in ensuring that the paper was not deeply flawed.
A brief note about language. The post says that the “article’s horse has already bolted into the public domain.” Since “public domain” has a technical meaning under copyright law, perhaps it would be better to say that the horse is now tame and can be ridden by anyone. Or dropping the metaphor, the article is openly available. Under copyright law, such articles are not in the public domain, but they are public.
Thanks Joe – I hadn’t realised that ‘public domain’ had a very specific meaning in this instance.
Thank you for an interesting analysis and set of suggestions.
Comparing F1000Research to a small selection of medical journals isn’t really valid. We publish papers in both medicine and biology, and we also publish all scientifically sound papers, whereas the journals you’ve chosen to compare us to try to filter out all but the very top articles and their reviewers therefore have to spend time and column inches commenting on novelty, relevance, potential interest levels etc. We’d be very interested in seeing a like-to-like comparison with a similar journal; PLOS One, for example.
With regard to the APCs, I see there’s some confusion: We charge for all papers that we publish (ie – all those that pass our pre-publication check), not just those that are approved by our referees. So APCs are completely independent of the outcome of peer review. We differ here from other gold-OA journals, which only charge for those articles they decide to publish following peer review approval, and where there is therefore a clear incentive to encourage positive refereeing.
In terms of the referee reports, the fact that all our referees openly sign their names to their reviews means that they are publicly standing by their opinion of an article – and I should emphasize that these are formal referee reports, not just comments. Most referees, especially as you say, referees of the standing of those we have been working with on F1000Research, will therefore weigh their words very carefully when they submit a review to us, as our openness, while it ensures they get credit for all their hard work, also exposes them to criticism if anything is amiss.
I am not sure how the 25 articles that were assessed here were selected, but we have plenty of articles with very detailed reviewer comments (e.g. http://f1000research.com/articles/2-76/v1, http://f1000research.com/articles/2-83/v1, http://f1000research.com/articles/2-5/v1) and plenty where referees have detailed quite significant concerns about an article. I believe your suggestion that referees are not willing to be negative in open peer review is therefore completely unsubstantiated. At the same time, with some articles, there really isn’t a lot that needs saying beyond an endorsement that the paper in question is scientifically sound. However, we take your point, and although to begin with we allowed referees to simply approve articles without comment, we have recently altered our approach and now require all referees to write something.
One final comment: With traditional scholarly publishing I think most people acknowledge that most articles can get published in a ‘peer-reviewed’ journal if the authors are persistent enough; they’ll eventually find reviewers who will recommend acceptance – and then everyone can cite the article and as you say, build their ivory tower on sand. By contrast, with our model, referees can openly discuss a published article’s flaws, and the article doesn’t quietly cascade down to a series of other journals until it finds a taker. This not only saves the time of further referees for subsequent journals, but, as the referee information is included in the article citation, it prevents others unknowingly citing poor work and thus propagating bad science. Additionally, our readers can see for themselves the varying views of a range of experts on a single piece of science, which better reflects the reality that in many fields there may be firm opinions but the experts may not be in agreement as to which opinions are the right ones.
You claim that APCs are only charged for articles that pass your pre-publication checklist, so this separates incentives. Yet, your in-house people are deeply incentivized to either make a checklist that is easily passed or to edge papers beyond the checklist in order to collect the APCs. You’ve actually made the conflict more direct, because there is no third-party involved, only internal (and opaque) processes by staff paid on the basis of how many APCs you collect.
You claim that repetitive, cascading peer review is a waste, yet studies have shown that it improves papers and increases citations to those papers because 1-2 pre-publication reviews help researchers address problems with their papers and help them find the right audience. Your claim on this front is bogus and your argument is cynical. And your review process does not allow for this type of manuscript improvement or outlet filtration. That is a real flaw.
You also apparently have no mechanism to improve your peer review process, and think it’s fine as it is. I think this quick study suggests that it requires some improvements and perhaps a full reconsideration.
I agree that comparable data from PLoS One would have been useful, but I didn’t manage to get hold of any. However, I feel that the comparison with medical journals is valid:
1) 22 of the 25 F1000 Res papers were on medical topics.
2) It’s true that “reviewers therefore have to spend time and column inches commenting on novelty, relevance, potential interest levels etc”, but this is typically the first paragraph of the review and does not really use up that much space. The bulk of a normal review is spent on highlighting problems with the paper, and typically contains a line by line list of things the reviewer thought needed to be changed. It’s the absence of the latter that makes F1000 Research reviews so short.
3) The key question for me here is why these highly experienced reviewers (all but four had an h-index over 10) did not generally trouble themselves to write a standard review, and most requested very few changes. This says to me that their threshold for approving F1000 Research articles is very low. You say “with our model, referees can openly discuss a published article’s flaws”, but clearly most referees do not. I think this deserves further exploration.
With respect to your point “plenty where referees have detailed quite significant concerns about an article. I believe your suggestion that referees are not willing to be negative in open peer review is therefore completely unsubstantiated”, I’ve tried to gather some data on this (see above). I found that fewer than 30% of comments were substantial (> 200 words), and 16% were negative, which is consistent with most reviewers not wanting to be publicly critical. Substantiating this would require interviewing the commenters, which I haven’t done. Maybe this is something you should look into yourselves?
Lastly, it’s true that you are saving “the time of further referees for subsequent journals”, but this is an inevitable consequence of having a 95% acceptance rate.
More broadly, F1000 Research is an experiment in the effectiveness of post-publication peer review. The goal should therefore be to prove that it can be as rigorous and discerning as traditional pre-publication review, while providing additional benefits. The limited data above suggest that this isn’t the case: even experienced reviewers don’t make much effort to improve the paper, and most submissions get published with minimal changes.
If I understand correctly, post-publication peer review is supposed to discourage low quality submissions. I.e. the assumption is that authors know that their paper is low quality before they submit and so they are discouraged from sending that paper for post publication peer review – as that would lead to the low quality of their work being highlighted publicly. I think the intention is that this should lead to a low rejection rate. Is it possible that it also means the papers are better edited before submission and therefore less rigour is required in the peer review? I agree that a comparison with PLOS1, if possible, would be very interesting in this regard.
@F1000Research – can you say how the rejection rate of F1000Research compares with the 30% rejection rate of PLOS1?
You make an interesting comment and I think we generally probably receive fewer poor-quality submissions in the first place, possibly for that reason, although it is really too early to tell. In terms of our rejection rate following our pre-publication checks, it is around 5%. I would however point out that as I understand it, PLOS One now receive approx 50% submissions from China (which we certainly don’t get) and so they’ve told me that this has led to a significant increase in their rejection rate over the past couple of years.
Are you suggesting that authors are deliberately sending poorer quality manuscripts in to journals with higher rejection rates and more rigorous pre-publication peer review? That seems counter-intuitive.
Really, it’s absurd to suggest that authors send in anything than their best efforts to any journal. I know that for every article I published, I agonized over every word, every punctuation mark, let alone the experiments, data and presentation of each. Each and every time though, there were things that I missed, typos, suggested additional experiments or data not shown that were helpful to add. But this was never due to a deliberate lack of editing effort on my part.
I know of no author who wants to be publicly viewed as sloppy and incomplete in their efforts, regardless of where they publish their papers.
Hi Dave,
I agree that most authors currently spend months agonising over every detail of their paper, but, as I mention above, that may be because they’re anticipating a rigorous peer review process. If you’re preparing a paper for initial submission to a journal with a very high acceptance rate, are you absolutely sure you’d be as careful? It might be more productive to spend the time working on your next paper instead…
If I’m putting anything out publicly with my name on it, that’s going to determine my reputation in the research community. So I’m going to be extra careful no matter where I publish it. I don’t know of any researcher who deliberately half-asses a paper that’s going to be made publicly available. You do the best job you can.
The argument is perhaps along the same lines of wanting there to be “clutch” hitters in baseball, who do a better job when the pressure is on because they bear down and try harder. The numbers though, show that hitters do what their averages say they do and that if it was possible to bear down and try harder, then hitters would do that every single time rather than saving it for key moments late in a game.
https://en.wikipedia.org/wiki/Clutch_hitter#Does_clutch_hitting_exist.3F
The clutch hitting analogy is certainly interesting, but I’m not sure that it works. For batters, the goal is ‘hit a home run’, where you either succeed or you don’t. Preparing a paper is more like a marathon with no clear finish line: you’re trying to explain a set of observations in the context of the broader literature, but there’s lots of other reasons why you might see that particular set of observations and not others.
The lengths to which you go in eliminating those other explanations is (I suspect) the difference in effort/thoroughness between submitting to a journal with high standards and a journal with low standards. Did you double check your negative controls? Are you absolutely sure that you got the statistics right? Is there another time consuming statistical approach you need to learn and then implement, just to make sure it gives a similar result? These gremlins sometimes can be the true explanation of the results, and a proportion of papers that don’t do all they can to eliminate or control for other explanations will be misleading and wrong. Allowing these into the literature at ever higher frequencies is not in the long term interests of science.
But you’re talking about taking different approaches in experimental design, not in writing the paper. The original poster above asked, “Is it possible that it also means the papers are better edited before submission and therefore less rigour is required in the peer review?” That’s a different question to how much effort one puts into a set of experiments that aren’t going anywhere interesting.
I think you’re a better researcher than me – it’s only when I’m writing the paper that all the ifs and buts really come into focus. You always hope that you managed to deal with all the big issues when you designed the experiment, but it seems that there’s always endless extra checks and dead ends that need to be eliminated even as you’re writing it up.
At some point you have to do the last experiment otherwise you never finish and submit the paper. At that point, you’re going to do your best to present the work, no matter the significance of the results, in the best possible light. If it’s really that awful, then you don’t make it public. If it’s good enough to show to anyone else, then you want to do everything you can so it enhances your reputation, rather than tarnishes it.
You do send lesser work to lesser outlets. But I don’t know anyone who deliberately puts less effort into presenting that lesser work–it all counts toward how people perceive you. If you know people are going to be reading your work and judging it, does it matter if there are sparse accept/accept with reservations comments alongside it? Does that really make you work harder to make the paper better, and if so, why not just do that all the time anyway?
Thank you both for your replies to my comment.
@F1000Research, can you say what proportion of papers receive ‘do not approve’ reports after publication? Sorry – I think that was what I meant to ask about when I said ‘rejection rate’.
@Dave, as I say, it’s an assumption. It’s interesting to see it put to the test. I think that authors consider a number of factors in deciding where to submit their paper.
There is an old article by Ulrich Poeschl in Learned Publishing about post-publication peer review in Atmospheric Chemistry and Physics (Learned Publishing (2004)17, 105–113). I think that this model is analogous in some ways to what F1000Research are doing now. The article appears to suggest that ACP is well cited and also has a low rejection rate.
I’ve copied a relevant quote from p109 of that issue below.
“Thus the overall fraction of manuscripts submitted but not accepted for publication in ACP (~20%) was much lower than in traditional atmospheric science journals (~50%), although the quality standards of ACP are by no means lower. These results confirm that interactive peer review and
public discussion indeed deter deficient submissions and counteract the flooding of the scientific publication market.”
We don’t have those numbers yet, simply because a lot of authors are still working on revisions after their initial referee reports. Even if their first version didn’t pass peer review, that doesn’t mean their second version won’t. We’re collecting data, and will be able to have a better look at this in a few months time.
Nice post Tim. The bottom line seems to be that people only read like (pre-publication) reviewers when they’re acting as (pre-publication) reviewers. I’ve reviewed some other lines of evidence for this proposition: http://dynamicecology.wordpress.com/2012/10/11/in-praise-of-pre-publication-peer-review-because-post-publication-review-is-an-utter-failure/
It is a very bad idea to bet against Vitek Tracz. He gave us BioMed Central, which changed everything. The Faculty of 1000 may or may not succeed, but it is working in an area that has an inexorable logic about it.
There’s an interesting article in this week’s New Yorker about personality-driven reputations and how they don’t guarantee success. The JCPenney fiasco is the case in point. I don’t think anyone has brought up Vitek in these discussions, but there are ideas here that bear critical thought. I don’t like halo effects — it’s how scandals go undetected.
Nothing guarantees success. When you have an established entrepreneur like Tracz, it’s prudent to be patient. He may be seeing something that others do not. We did not know we “needed” an iPod until we held one in our hands. Neither Verizon now AT&T believe we “need” 1 gps Internet in our homes, but see what Google is doing in Kansas. We don’t “need” post-publication peer review until we do, and then it will feel inevitable.
We should apply higher standards to science publishing than we do to gadgets: the success of a business model should be judged not just on how much money it makes, but by how well it contributes to the progress of science. Some things have been successful because they offered an ‘improvement’ over the original, but nonetheless had an overall negative impact on society.
Technology is not gadgets Tim, nor is social change. The standards will be set by the market which means by the people involved, not by judges. I am reminded of the Model T, which was a piece of cheap junk compared to the hand crafted cars being built by thousands of car makers when it was introduced. People pointed this out but cheap junk turned out to be a far better deal than fine craftsmanship, and the rest is history. But then perhaps you think the car has had an overall negative impact on society?
The point is that there is no we to apply the standards you are calling for. Science will go its own way.
I see a stronger parallel between science and the practice of law than between science and products. Science and law are attempting to determine the truth about a situation. The standards in law are built on many hundreds of previous decisions, and things are slow to change. Science is the same way – new ideas that don’t offer improved explanatory power over the status quo are quickly dropped.
The same logic should apply to the mechanism by which science is evaluated, in that it should be slow to change, and only supportive of new approaches once they’ve proved their worth. Switching to post-publication review would be akin to the legal system abruptly switching from precedents to phone-in voting. Sure, we may go down that road, but we have to be fully aware of the consequences while we’re doing it.
Tim, my conjecture is that law, technology and science all change at the same rate and in the same ways. For all three are deep social processes, governed by highly distributed social reasoning (each of which I have studied at length, separately and together). The idea that technology changes rapidly is a common misconception, while conversely both the law and science can move quickly when the time comes.
Revolutions all have the same logic. Of course we have no way to measure these things at present. The science of change awaits us. My hope is that it will do in the 21st century what thermodynamics did in the 19th, namely provide a way to compare seemingly disparate systems.
There is no prospect that science will suddenly switch to post-publication review any more than we suddenly switched to cars or to the Internet. But over the next 30-50 years many things are possible.
David- thanks for this. It’s good food for thought. I guess we’ll have to wait and see what happens.
Actually Tim each of us can jump in and push or pull as we see fit. That is the beauty of the social system. What should be is a personal judgement and not to be ignored. What will be is a scientific question.
But if the evidence is that post-publication peer review is equivalent to our Zune, am I going to buy that just because Microsoft has a good track record?
I think there’s a lot of evidence — about willingness, quality, reliability, usability, and appropriateness — to suggest that post-publication peer review is not only not peer review exactly, but also an inferior offering in many ways. Zune, baby. Zune.
I am curious to hear more about this inexorable logic, Joe. It is a very strong claim. The intertwined logic of science, technology and policy is my field and it is seldom predictable, much less inexorable. What are you saying?
One thing not discussed in the above posts is what happens after comments are made and articles are green lighted (approved). The first example given by the F1000 commenter, Christofi and Apidianakis (2013), has one “approved” and three “approved with reservations”.
Will the authors update the article based on the comments to get full “approved” status from the three reviewers, or they don’t necessarily have to do this if they don’t feel like it?
What about comments from the “approved” reviewer, will they ever be taken into account, or they don’t matter because they already said approved?
It seems that if the requirement for the paper to stay online is that authors have to update their work and get full approval status, then the peer-review would actually matter and be more like the traditional way, except more open and more efficient.
Similarly, it’s unclear to me what happens to rejected papers. Can the authors revise and resubmit? Can they get it re-reviewed? Do they have to pay again for this? How many rounds can a paper go through? Or, since the paper is already published (but rejected), is it now unpublishable and permanently publicly marked as a failure?
Authors *can* leave the paper as it is if they want to, but they would probably prefer to revise it to receive the required number of “approved” reports to be indexed in external databases!
But authors may also respond to “accepted” reviews and make revisions based on that to further improve the manuscript. For each reviewer, only their latest review counts towards the paper’s overall score.
Examples:
From two revisions to two accepted: http://f1000research.com/articles/1-40/v2
Revising even with “accepted” reviews: http://f1000research.com/articles/2-33/v2
Thank you for the examples.
Thanks. Are there any details available on how this process works? How does the author solicit re-reviews?
Can the author continuously revise a paper? Could I publish an experiment, then later revise the paper to include the next experiment, and so on for years and years?
Very briefly, we’d like to correct some of the apparent misunderstandings in a few comments above:
– An article, once published on F1000Research, stays there. It’s not correct to say that it “may not actually stay, and may be taken down”. It has a DOI, it’s published, and it’s there for good.
– For the definition of “acceptance” or indexing status, please take a look at our About pages http://f1000research.com/about and our blog post about indexing: http://blog.f1000research.com/2013/02/18/points-of-clarity/ . Articles that have been approved by two peer reviewers, or approved with reservations by two and approved by one, will be indexed by PubMed and Scopus. Apologies if this is not clear. We’ll take a look at our language and tighten it up if necessary.
– Our Editorial Board is made up largely of F1000 Faculty Members who support Open Access publishing and open peer review and accepted our invitation to join us on F1000Research. Referees of papers, whether they are Faculty Members or others, are not simply commenting on papers. They are conducting full, conventional and entirely rigorous peer review, and yes, the buck does stop with them.
Should it be any surprise that Author-Pays Start-up Publisher X may want to grease the skids for its authors? I would say it’s inevitable to serve business model.
Thanks for an interesting article Tim. One thing that you touched on was the experience of the peer reviewers. Something that I’ve been (perhaps naively) surprised to discover only recently is how little formal training or support there is for new peer reviewers. Is there a risk that the F1000 model could lead to less support/education on this or might it, by its very transparency, actually help?
I don’t think that this is an issue for F1000Research at the moment, as the reviewers that contributed to the above data were all highly experienced. If post-publication peer review becomes the new normal, then I guess the online comments will become the template for beginner reviewers. Currently, though, a lot of the education about pre-publication peer review comes when the decision letter is sent around the reviewers, as then a beginner referee can directly compare their comments for the paper with the more experienced reviewers (and the editor). It seems to work quite well, as people seem to improve rapidly over the course of 2-3 reviews (this is a hunch – I have no direct data).
Alice, lack of training in peer review is a common problem. In an attempt to address lack of awareness about ethical aspects, we at COPE have just launched some ethical guidelines for peer reviewers
http://publicationethics.org/resources/guidelines .
Our hope is that as well as providing guidance for researchers and being a resource for journals and editors in helping their reviewers, they’ll be an educational resource for colleges and institutions in training their students and researchers.
Tim, I agree that letting reviewers see the other reviewer reports and editorial correspondence is very valuable to reviewers. Unfortunately, one group of reviewers may never get to see that material – those reviewing manuscripts for their PIs without their name being passed on to the journals. I don’t know how many of those PIs pass on the feedback from journals, but in the cases where large numbers of manuscripts are reviewed without acknowledgement (and not as an educational exercise), I doubt many do. In the COPE guidelines we’ve tried to address this inequality, and also provide junior researchers who don’t know how to rectify the situation with something they can show their PIs ( “… the names of any individuals who have helped them with the review should be included with the returned review so that they are associated with the manuscript in the journal’s records and can also receive due credit for their efforts.”)


