Editor’s note: Today’s guest post is by Anita Bandrowski, who runs the RRID initiative and is the creator of SciScoreTM and Martijn Roelandse, who works as a consultant for SciScore.TM
Much time has been spent thinking about honing the results published in scientific papers toward the interesting. Studies with short titles get more newspapers interested; studies about coffee or wine are the superstars of Twitter. But in reality, most science is not so flashy. Studies frequently take years to complete and represent careful work by scientists, which, when well considered, provides us with very important insights about the world we live in, as well as solutions to global problems from climate change to disease.
There are multiple ways to measure how much attention is being paid to a study. For example, the number of times that a study is cited, and by extension the average citation rate of a journal is a common metric. Various alternative measures of “popularity” (altmetrics), such as the number of times that it is tweeted have been devised. However, until now there has never been an easy way to measure any aspect of the quality of a scientific study.

Looking broadly across the literature in various meta-analyses, scientists have determined that some methods do impact study quality. For example, MacLeod and colleagues have been studying which factors are associated with overinflation of results for several decades. The short version of their findings is that factors that reduce investigator bias, such as experimenter blinding and randomizing subjects properly, are associated with about a 50% change in effect size.
So let’s just underline this — the effect size of a poorly controlled study is about 50% bigger than the effect size of a well controlled study. Let’s let that sink in while we discuss the 90% failure rate in clinical trials in some areas of medicine. Like the recent exemplar in Science, is it possible that poorly controlled studies are repeated using proper controls in patients and fail because the effects were never significant to begin with?
And, if so, what in the world can we do about this conundrum?
Standards to the Rescue
The National Institutes of Health (NIH), in the US, has outlined these same factors as critical aspects of all newly funded grants as of 2016. The NIH also identified reagents like antibodies, and resources like cell lines and transgenic organisms, as additional causes of reproducibility woes.
Many journals have now joined the chorus of “we must do better for the sake of science,” as exemplified by the MDAR pan-journal group, which recently released their documentation of the “MDAR (Materials, Design, Analysis, Reporting) framework and checklist for the reporting of experimental studies in the life sciences”. This is a comprehensive checklist and incorporates many elements of known standards such as ARRIVE, CONSORT and RRIDs for reagents.
We need to be able to answer questions like: Do authors read the rigor and reproducibility guidelines from the NIH and immediately change their publishing behavior? Do some journals publish better papers overall because they got more compliance from checklists? Do some biomedical fields perform better overall than other fields?
To help, we have developed SciScore, a tool that can evaluate whether the authors have addressed blinding, sex, and randomization of subjects into groups, power analysis, as well as key resources. These are all difficult and tedious things for humans to check, but critical if we want to measure — and ultimately improve — the quality of the science being conducted and published.
The corpus at PubMed Central gave us a great starting point for trying to answer some of these questions. We ran SciScore on 1.6 million papers last month and we made some interesting discoveries.
For example, the simplest thing to check is whether authors define the sex of the animals they use. In early papers (before 2000), about one quarter of the papers did so; in 2019 that has grown to over half. But, to put that differently, about half of animal studies still don’t include the sex of the experimental subjects.
Defining how groups are selected (i.e., randomization of subjects) is covered in more than 30% of the papers, but for blinding and power analysis, the 2019 numbers are in the anemic single digits to low teens. So the rigor criteria that are absolutely required in every clinical trial are being ignored in the preclinical animal literature.

Similarly, looking at antibodies, one of the more serious culprits of the reproducibility epidemic, we find that in 2019, nearly 50% are identifiable. This is great progress compared to just 10% in the 1990s, but it still means that half of the antibodies being used can’t be unambiguously identified in the papers reporting on results. What is the point of reading a paper if you have to contact the authors for all of the details that you would actually need to reproduce their original study?
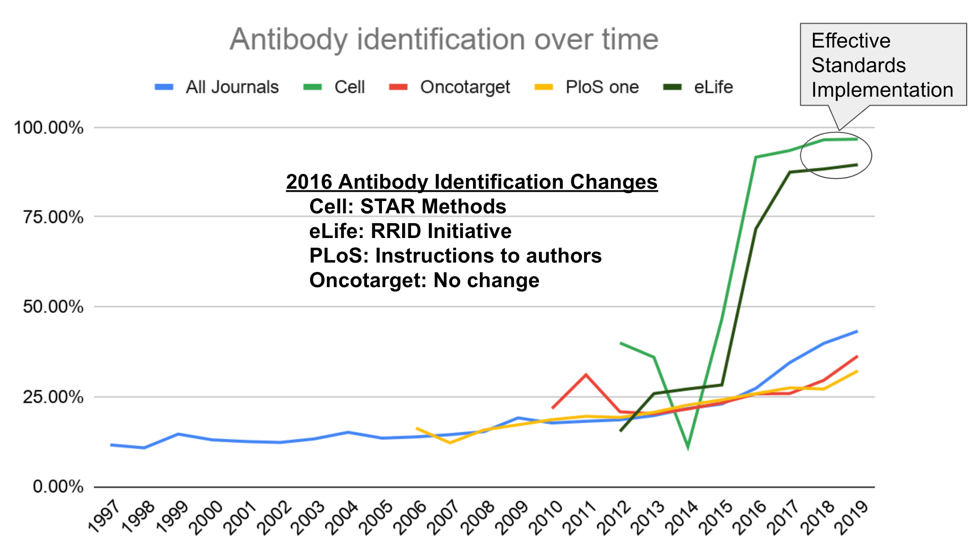
However, the news is not universally bad. For example, the graph of antibody identifiability shows a dramatic increase in journals like eLife and Cell since 2015/2016.
So what happened? Did authors submitting to eLife and Cell read the NIH guidelines and spontaneously decide to follow them? In short, no. Instead, both journals, and an increasing number of others changed their guidelines to make them more visible, and backed this up by proactively enforcing them. In contrast, PLOS ONE also changed their instructions to ask authors to improve how they describe antibodies, but without the same level of active enforcement, and there has been much less impact.
We also looked at whether there is any correlation between a journal’s Impact Factor and the research quality of the articles it publishes based on its SciScore. SciScore scoring ranges from 1 to 10, where a score of 5 means that authors addressed 50% of the expected rigor criteria. Based on a comparison of the 2018 JIF with the average SciScore from the same journals over the same time, as shown below, we were surprised to find that the two measures are completely uncorrelated.

So, while we can’t say that “interesting” science, as measured by the impact factor, is more or less true than “average” science, we can say that it is about time to start looking a little deeper at the actual quality of science in the papers and a little less at the “X-factor”.
Discussion
5 Thoughts on "Guest Post: Interesting Versus True? Measuring Transparency and Reproducibility of Biomedical Articles"
Is this post based on a paper? How can we reproduce your results?
Dear Scott, the preprint is coming in early January with data for 4000+ journals. For any given paper, you can run sciscore.com (use ORCID to log in so you get in for free).
his is very interesting. From a personal perspective, I do struggle with randomizing. We do many studies with genetic mouse models, where we use litter mates as the control group. Mice are greatly inbred, reducing intrinsic variability, and we have thought that litter mates were the best controls. Sort of like a paired study. I assume that this would appear to be non randomized using these criteria. Additionally, when we do an intervention on a group, we kind of choose ‘at random’ mice from a cage and treat them with whatever. We don’t call this ‘randomization’ because we don’t tag the mice ahead of time and do a formal randomization, but it may be functionally as good. For blinding, we probably can and should do better, but we already tend to do that when we do, for example, scoring fibrosis where there is subjectivity involved. For telemetric bp recording, which is pretty much user independent, we don’t ‘blind, although I am not necessarily opposed. Very interesting and we have really pushed ourselves with regard to sex and antibodies. Interestingly, they don’t mention mouse strain.
Thanks for your comments.
What we are still struggle with, in the manuscript that we are preparing for this, is exactly what you are describing. When are which criteria useful and when are they superfluous. From the tool perspective you may state “I did not blind or randomize my study” and that will count as a +1 for blinding, +1 for randomization. It is not ideal, but solving the problem under which circumstances is it appropriate to randomize may be beyond the ability of at least our tools. Randomization and blinding are both investigator bias reduction strategies, so while I have no good advice for using littermate controls, figuring out a way to meet the same goal in the absence of one of these “pillars” for a particular experiment may be tricky, but is arguably quite worth it.
In animal toxicity studies, academics (often randomized & blinded) regularly find a toxic effect; while industry’s OECD Test Guideline methods (TG, also relied on by US EPA, but called EPA Test Methods) methods (which do not require blinding) often report null findings.
One complication is that academics usually test the hypothesis of effects of low, realistic exposures; while the TG *invariably* test much higher doses (non-monotonicity; common in biology, may explain part of that).