A few months ago, we shared our thoughts on “Making the Case for a PID-Optimized World“, including a high-level PID-optimized workflow. But, to make this world a reality, we need to look in more detail at how persistent identifiers are, or could be, used in all research workflows — from grant application to publication. A number of PID experts from around the world have been working on exactly this for several years, starting with a series of meetings in Singapore, London, and Portland, OR. Now, as part of the Jisc PID roadmap project, we expect to publish PID-optimized workflows for funding, content publication, and data publication later this year, all of which have been reviewed by community volunteers.
In the meantime, in honor of this year’s Peer Review Week, we are pleased to share a draft PID-optimized peer review workflow — a nice tie-in with the theme of Identifiers in Peer Review!
This is very much a work in progress, and we’d welcome your feedback and comments. We’ve focused here on traditional peer review for journal articles, so we know that more detail is needed about other forms of peer review, but what else is missing? For example, should we include the underlying research data (which may already have a PID) that is submitted along with the article and, if so, how and when? What about other forms of content associated with an article that have their own PIDs, such as Registered Reports? Is the workflow itself clear enough? Should we include the Publons workflow?
You can add comments in the workflow itself and/or share your feedback here. Either way, we look forward to hearing your thoughts!
A big thank you to Kath Burton of Routledge/Tayor & Francis for her help with the workflow.
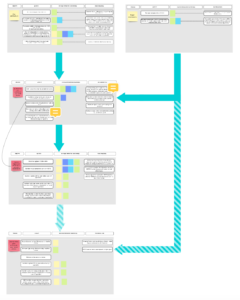


Discussion
6 Thoughts on "PIDs for Peer Review!"
Use PIDs not only for peer review, but to also project manage research workflows i.e. track AOM to AAM to VoR?
Would it be possible to add race/ethnicity/gender information into the PID so we could track diversity of authors, reviewers, and editors? This might help make us more knowledgeable about diversity and inclusion in research and publishing in general.
Thanks both!
Lucy, it’s not quite the same thing but there is a NISO initiative underway to revise our Journal Article Versions Recommended Practice, in part to address PID-related issues like whether there should be a single DOI for an article, regardless of version, or different DOIs for each version – a step in the right direction at least (see: https://www.niso.org/standards-committees/jav-revision).
Ginny – I’ll leave the ORCID people to reply to your comment if they wish but, from my time there, I know there was strong resistance to the idea of collecting any kind of personal demographic information (largely because of privacy issues). However, you’re quite right that we do need to find ways of collecting this information if we want to address DEIA issues in our community…
Thanks, Alice. I figured the privacy concerns would make this challenging, but until we come up with a way to gather data, it seems as though we’re going to make less progress in terms of representation and inclusion than we should. Right now it takes so much effort to compile race/ethnicity/gender information that we don’t really have effective ways of tracking trends. Anyway, many thanks to you for all your work on PIDs.
Dear Alice and David,
This is a great start and I am happy to participate in this project if you look for volunteers. Below I share my learnings from the pilot of publishing peer review with DOIs that I ran from 2016 to 2018 with 5 Elsevier jnls.
– Anonymized or signed: DOIs should be applicable for both signed and unsigned peer review reports. Reviewers who decided not to disclose their names should still benefit from this. Back then it wasn’t easy to arrange for this but we manged to find a way (see example of an anonymized published peer review with a DOI here: https://www.sciencedirect.com/science/article/pii/S2214581815001676)
– Revision 0 and higher: our solution was that all peer review reports of the same manuscript in different revision rounds need to be collated in one document so that per manuscript, reviewer reports receive one DOI (see example here: https://www.sciencedirect.com/science/article/pii/S1743919115001958)
-Process transparency: to avoid surprises, sharing peer review reports with DOIs on any platform need to be transparent. Our solution was to inform authors at the submission stage that if accepted the peer review reports would be published alongside their article (signed if reviewers give consent). Reviewers were informed at the invitation stage, and after accepting the invite during the instruction, and in the submission system at the point of submitting their review report, that their peer review report would be published-upon the acceptance of the paper- with a separate DOI that they can add to their ORCID account.
I think if you want to go back retrospectively to assign DOIs to Publons data you might need to consider risks as that might reveal parts of the identities authors/reviewers might not want to share.
Thanks Bahar, this is really helpful. We initially tried to include the Publons workflow, but quickly realized that we don’t know enough about it (including, as you say, the risk of retrospectively assigning DOIs). It would be great if someone from Publons could help with this



