It’s no secret that the COVID-19 pandemic has led to a surge in research activity. The number of preprints and articles published has increased enormously, peer review is happening faster than ever, and readership is at all-time highs. At the same time, public trust in science appears to have soared as well. For those of us working in scholarly communications, this is welcome news in what is otherwise a time of global crisis and tragedy. At last, an opportunity for the researchers and scientists we serve to get the attention and credit they deserve!
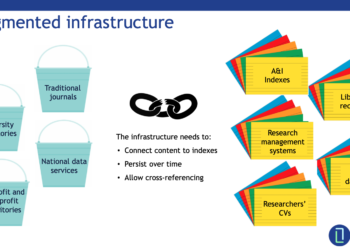
In order to publish more research, faster, without compromising on quality, it’s more important than ever to invest in a robust research infrastructure — the tools and systems that enable researchers to spend more time doing research and less time managing it. Whether they’re applying for a grant, identifying possible collaborators, searching for the right information, or submitting a manuscript, we can make their lives easier and more productive by providing them with equitable access to reliable, openly available, and user-friendly services.

Persistent identifiers (PIDs) — for people (researchers), places (their organizations), and things (their outputs and other research objects) — are essential to many of these services. Being able to correctly identify and connect a researcher with their institution(s), publications, and other works and routinely including that information in metadata improves search and discovery, facilitates credit and recognition, reduces errors, and enables other efficiencies. Open PIDs, such as DOIs (Digital Object Identifiers), ORCID iDs, and ROR (Research Organization Registry) identifiers have additional benefits. Not only are they free to end users, they are also fully interoperable, resolvable, and enable the creation of open, well-defined provenance information. Recent years have seen significant upticks in the adoption and use of these identifiers, including (as of June 24, 2020):
- PIDS for people — close to 8.9M ORCID iDs
- PIDs for places — over 91k ROR identifiers
- PIDs for “things” — over 115M Crossref DOIs and 30M DataCite DOIs
Adoption has been at the national, as well as the organizational level. For example, ORCID introduced its consortium model in 2014 and now has over 20 national consortia across six continents. However, it’s only in combination that persistent identifiers become really powerful. A DOI alone enables citation linking, but there’s no way to be sure it’s linked to the correct author or organization without the corresponding ORCID iD and organization identifier respectively.
As PID adoption has grown, there is increased awareness of the need for organizations, countries, and even regions to develop an overarching PID strategy. The recently released second version of the EOSC PID Policy is a case in point. It recognizes a wide range of PIDs and, among other things, it, “defines a set of expectations about what persistent identifiers will be used to support a functioning environment of FAIR research.” It looks to a future where: “PIDs can be used as the preferred method of referring to its assigned entity.” The Australian Research Data Commons, meanwhile, already provides a number of PID services — including DataCite DOIs, Handles, IGSNs (International Geo Sample Numbers), and their own RAiDs (Research Activity identifiers). Now the UK is getting in on the act, with a new initiative intended to support open research, including Plan S compliance, through the creation of the world’s first national PID consortium.
The UK has long been a leader in open research — from the Wellcome Trust’s 2004 report on Costs and business models in scientific research publishing and RCUK’s Position statement on open access to research outputs the following year, to UKRI’s endorsement of Coalition S. There has also been strong UK support for open research infrastructure, including the formation of a national ORCID consortium in 2015, led by Jisc, the UK’s higher education organization for digital services and solutions (98 UK universities and research institutes are now members).
More recently, UK support for open research infrastructure has included a UUK-sponsored workshop to explore the use of PIDs in open access publishing workflows, in which participants highlighted pain points and identified elements where PIDs are already being used to address them. They also modeled an ‘ideal world’ workflow, in which PIDs could be used to automate the exchange of information, improve how it flows between systems, and trigger specific actions. This was followed by additional PID workshops in Singapore, London, and Portland, OR in 2018-19, run jointly by the Australian Research Data Commons (ARDC), California Digital Library (CDL), the FREYA project, Jisc, and ORCID, where participants mapped other research workflows, identified which PIDs are already being used and where, and highlighted opportunities to expand the use of these and other PIDs in future.
Around the same time, in 2018, Professor Adam Tickell’s independent advice to the UK government on open access to research publications included a recommendation that Jisc should “lead on selecting and promoting a range of unique identifiers … in collaboration with sector leaders with relevant partner organisations.” Jisc and UKRI subsequently commissioned a report in response to Professor Tickell’s advice — Developing a persistent identifier roadmap for open access to UK research. Author Josh Brown made several recommendations for the future adoption and use of PIDs in the UK, which are now being implemented through a joint Jisc/UKRI PID project (full disclosure, Josh and I are acting as consultants on some aspects of this project).
As well as the formation of a UK PID consortium, which would both operate the UK’s ‘open research infrastructure’ and also support the use of open PID infrastructures as needed by the community, other key elements of the roadmap include:
- Increasing adoption and use of PIDs through targeted interventions to create high-value integrations with PID infrastructures that provide clear benefits to researchers — initial priorities are RAiDs, Crossref and DataCite DOIs, ORCID iDs, and ROR identifiers
- Carrying out a benefits analysis to understand and evaluate the impact of PID adoption in the UK, with a focus on supporting the transition to open access, using open infrastructure, and advocating for more open interoperability
- Establishing a governing council to oversee governance opportunities and activities in the PID systems, and to provide consortium oversight and management
- Creating a one-off sustainability task force — with an international remit — to explore, examine, and evaluate business models and pathways to sustainability for the PID organizations in the consortium
A UK stakeholder group has now been formed, with representatives from across the higher education community, as well as funders, publishers, research information experts, and the identifier providers themselves. However, in recognition that research and the open research infrastructure are international, the project will also reach out to the global community, focusing first on repositories, community infrastructures, and publishers (especially OA publishers).
If you’re interested in learning more about this initiative, you can request access to a recording of Persistent Identifiers and Open Access in the UK: The Way Forward, a recent Jisc webinar featuring Professor James Wilsdon, Digital Science Professor of Research Policy, Sheffield University, Hilda Muchando, Senior Information Policy Officer, Jisc, and Matthew Buys, Executive Director, DataCite. In addition, Jisc is carrying out a global survey on perceptions and usage of PIDs, which will be open through July 26 — The Scholarly Kitchen readers are invited to share your views and experiences. The results, together with the anonymized data set, will be published later this year.
The UK’s renewed commitment to supporting a robust and open research infrastructure would be welcome at any time. But with researchers around the world working harder than ever to tackle the COVID-19 pandemic — from lab scientists developing vaccines to social scientists highlighting the disproportionate impact of coronavirus on already underprivileged communities — it is especially timely.
July 29, 2020 update: Please note that the Jisc survey deadline has been extended to August 21

Discussion
7 Thoughts on "The UK National PID Consortium: A Pathway to Increased Adoption"
This is a useful update, but it seems strange to me to discuss persistent identifiers without any mention of some pretty effective services that have been around for quite a while. For example, Ringgold has been providing an institutional identifier service since 2003. Is this a symptom of an urge to make everything ‘open’ and ‘free’, and to dismiss effective solutions simply because they are provided by commercial organisations? Does the scholarly communications community recognise the potential for unnecessary expense in re-inventing the wheel? We should bear in mind that these committees, stakeholder groups, and consortia all consume time, salaries and direct costs, that need to be funded from somewhere, and that any new service that is established will have ongoing operating costs that also need to be covered. I’m not suggesting that commercial solutions are always ideal, or that for-profit suppliers are always noble, but we should ask ourselves whether we are at risk of spending more money to make things ‘free’, than we are currently spending for satisfactory commercial solutions.
Great article Alice, and an interesting observation by Mark.
I recently shared a brief analysis showing that the daily count of ORCID IDs associated with Crossref DOIs has climbed rapidly in the last few years (https://www.linkedin.com/pulse/who-uses-orcid-ids-anyway-richard-wynne/). This success is significantly due to the adoption of PIDs by commercial entities and platforms.
Alice – do you know if active engagement with commercial entities is part of the UK Roadmap and if commercial organizations are part of the mentioned “stakeholder group”? Thank you.
Richard Wynne
It’s less about commercial/for-profit than it is about open/available. I think one of the benefits of open standards and identifiers rather than closed, proprietary tools, is that anyone can then use them to build a new service or company. To use your example of Ringgold, if I want to build a new service for publishers or universities around their identifiers, I have to get their permission, pay them for those identifiers, and likely play by their rules, which may make my new service harder to achieve (or much less profitable for me). At any point, they can change the way their identifiers work, which may destroy my service. With an open standard, every commercial company out there can use it however they want (and profit from it as much as they can), but with a proprietary, closed standard, progress is limited to what the owner will allow.
We want competition and constant evolution which is better for the market, and that’s a lot easier to achieve with open standards. As a publisher, I’d rather have multiple options available rather than being stuck with one take-it-or-leave it choice, and I want to be able to move from system to system with ease rather than being locked-in.
Thank you for this timely article. As a technology solution vendor in the OA space, PID’s and other meta data are essential to provide accurate OA transactions, systems interoperability and transparent reporting for internal operations and external stakeholder needs.
I just wish more people would make use of ORCID. Recently, I saw a colleague excessively criticised in a snarky book review published in an academic journal by somebody who made flawed presumptions about her credentials based on social media instead of confirming the facts in her CV. This wasn’t even doxxing. It was the complete opposite.
Thanks Mark and Richard, you raise an important point and I think (hope!) we can all agree that commercial organizations do play an important role in the research infrastructure – not least through the support they provide to open organizations in terms of finance, resource, and implementation of open infrastructure elements, such as PIDs. I can’t speak for the Jisc decision as I wasn’t in any way involved in it, however, I personally agree with Geoffrey Bilder, Jennifer Li, and Cameron Neylon’s assertion that: “The underlying data that is generated by the actions of the research community should be a community resource – supporting informed decision making for the community as well as providing as base for private enterprise to provide value added services.” (Bilder G, Lin J, Neylon C (2015) Principles for Open Scholarly Infrastructure-v1, http://dx.doi.org/10.6084/m9.figshare.1314859) Their whole article is well worth a read if you’re not already familiar with it.
I was present at Frankfurt when Crossref was initiated and I have no doubt it lost a lot of money for years when it was supported by STM but it has changed its nature and governance during this period and has been a accepted (as I understand it) by all relevant stakeholders. I suggest that there is a lesson here. Some PIDs emerge.