Editor’s Note: Today’s post is by Chris Houghton. Chris is Head of Academic Partnerships at Gale.
There has been a sea of change in humanities studies in recent years. As part of the first wave, librarians and researchers have sought to harness the newfound power of digital archives to not only collect, but just as importantly, to curate, clean and analyze large sets of data.
Before we dive into the three challenges — and solutions — of expanding the influence of digital humanities, let’s first consider the possibilities available in this relatively new area.
Consider the case of a researcher wishing to analyze a large set of eighteenth-century gothic fiction. Thanks to mass digitalization, material related to this topic and time period are now electronically available in a wide variety of databases. Until recently, analyzing these sources at scale meant that the scholar had to explore and cross-check these various sources, extracting works in machine readable formats before writing code to configure cleaning algorithms that would correct any imperfections. Only then would the researcher have a ‘clean’ set of data to act as the dataset for their analysis project.
Experience has shown that the overlap in a Venn diagram of: a) students interested in eighteenth-century gothic fiction and; b) those with the coding skills to collect and standardize this disparate set of data for analysis, is quite small.
With today’s digital archives putting more primary material within reach of students, the first part of this problem has been mostly solved. It’s the second part, the ability to extract the necessary information while discarding the chaff, that is rapidly advancing. Instead of running a search through one database, getting back incomplete answers, then refining the search multiple times before moving to another database, the ability to run searches through multiple databases gives today’s students unprecedented research potential. With little training, they can develop a research question, create a query to test it, before refining it multiple times through multiple databases, all in a short period of time.
These advances mean that our researcher no longer needs to spend half of their time acquiring information but instead can rapidly move on to the work of testing research questions and critically evaluating concepts.
This is the promise of digital humanities.
Digital humanities is a way to incorporate new media and new methods into the tradition of humanistic inquiry and to ask new questions. We should, however, never think of digital humanities as a replacement for traditional methods of enquiry, but instead as a way of enhancing them and uncovering new possibilities.
So how can libraries and students take advantage of this evolution? By recognizing and solving three universal challenges of digital humanities:
1. Big Data Analysis Needs Data
Many digital humanities projects require a lot of data in order to generate statistically significant conclusions. The more databases and sources available to the scholar, the more power they will have to ask new questions, discover previously unknown trends, or simply strengthen an argument by adding more proof.
As we have seen, this presents a challenge to the researcher and the library they rely on. An academic who runs a large digital humanities research group explained to me recently, “You can spend 80 percent of your time curating and cleaning the data, and another 80 percent of your time creating exploratory tools to understand it.” Notwithstanding the (slight) exaggeration, the struggle is real — the more data sources and data formats there are, the more complex this process becomes.
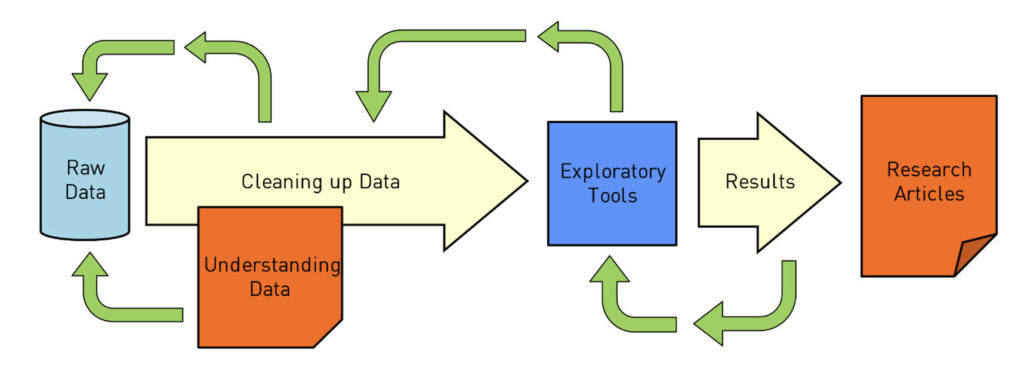
One answer for college libraries is to make sure their digital archives are up-to-date. Today’s students should be able to delve not only into wide-ranging databases, but also specialized ones that focus on topics or time periods of interest, such as political extremism or the eighteenth-century. Increasing numbers of university libraries are now developing archive collections that rival the top schools around the globe and enable world-class research. Making sure your library has a robust collection of databases available for students to search is step one.
Ultimately, this data availability combined with the ubiquity of increased computing power, means the possibility of digital humanities for all has never been larger.
2. Hosting and Maintaining Large Data Sets in an Institutional Setting
One aspect of having access to such large sets of data today is that libraries and colleges have to plan how to store this information. A school might subscribe to the Times Digital Archive, giving them cloud-hosted access to over 230 years of the world’s newspaper of record. It may then transpire that a researcher wants to use this resource for a text mining project, requiring the material to be in a machine-readable format as opposed to in facsimile form, as it is in the digital archive. This requirement would be met by purchasing a text and data mining (TDM) drive with all of the underlying text and metadata on it, which for an archive of this size would run to several terabytes in size.

The school would need servers to store this information, and someone to manage the information on them. The data should be protected so that it is only available to those who have access, while also making sure that a single errant keystroke doesn’t erase an entire database. Servers need shielding from floods, power outages, fires, and other natural disasters, and regular maintenance to keep them compatible with the latest software.
None of this should be a surprise to a librarian or a university, but this relatively costly and time-consuming process can often act as a barrier to contemplating digital humanities research.
3. Developing the Technical Skills to Perform Analysis
The technical skills necessary for a digital humanities project can be sophisticated, and often provide an obstacle for the humanities researcher looking to leverage the power of these methods.
Consider again a researcher with access to the Times Digital Archive, but this time with access to the underlying data through a TDM drive. The first pre-processing step would be to eliminate material in which they have no interest, perhaps advertisements, sports news or weather stories – these might be considered unwelcome ‘noise’ when constructing their dataset. Identifying and excluding these newspaper sections leaves the researcher with news and editorials, both of which could be valuable to their project.
There is still a lot of work left to refine the dataset. Our scholar would need to critically evaluate the remaining material for data quality and relevance to their project, excluding or correcting material that might skew their research. As well as being time consuming, these processes require technical skill alongside existing subject knowledge.
Gale and a number of other providers, including HathiTrust Digital Library, Google Books and ProQuest are now providing environments that enable this work to be done quickly and at scale. Previously, where researchers might have needed coding skills to complete these tasks, they now have the option of user-friendly interfaces, accessible to all.
Tools like these can seriously streamline the workflow of collecting, curating, cleaning, and analyzing huge sets of data. Instead of researchers spending 80 percent of their time on pre-processing tasks, using these tools radically reduces the time spent on them, bringing it down from months to days, if not hours.
The excitement around these tools is that they also open up this type of research to a much wider range of students and professors. If it doesn’t take months to create a clean data set from which to start, many more students, including undergraduates, will be able to do this work in the future – just as many are starting to do it now.
Digital humanities has enormous potential to not only uncover new research pathways, but also to encourage the development of transferable technical skills at universities. New solutions are making this exciting area more accessible than it has ever been, giving every institution the opportunity to generate better humanities research and teaching.

