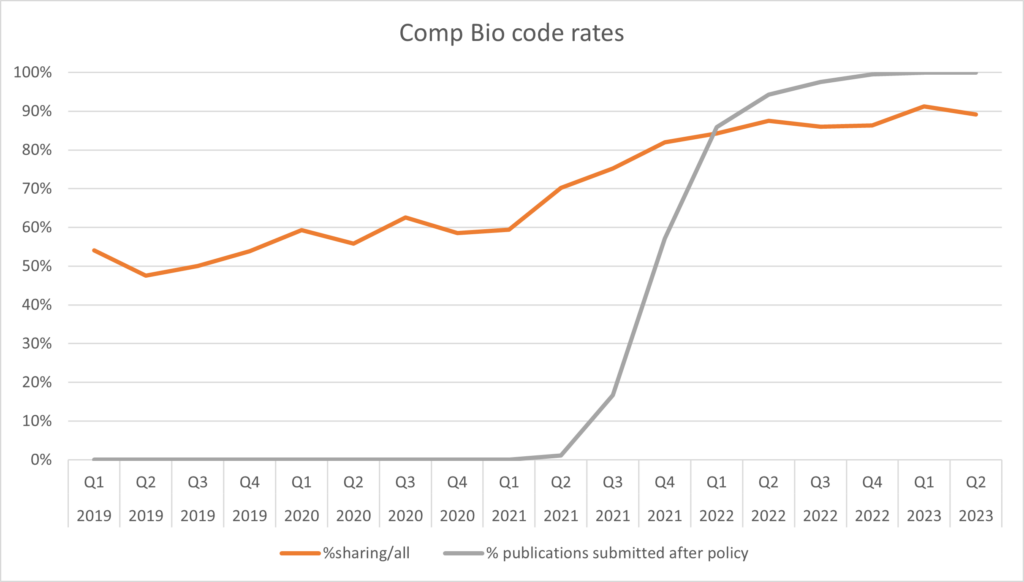
Continuing our week of posts to celebrate Peer Review Week 2023, today we will be looking at peer review of non-traditional outputs — specifically code — a topic that ties in well with this year’s theme of peer review and the future of publishing. In March 2021 PLOS Computational Biology introduced mandated code sharing. If the research process included the creation of custom code, the authors were required to make it available during the peer review assessment, and to make it public upon the publication of their research article. At the end of the year-long trial period, code sharing had risen from 53% in 2019 to 87% for 2021 articles submitted after the policy went into effect, and code sharing is now a permanent feature of the journal, with a current sharing rate of 96%.
In today’s guest post, Joe Pold, Journal Development Manager at PLOS, talks to the senior editorial team, Editors-in-Chief Feilim Mac Gabhann and Jason Papin, and Deputy Editor-in-Chief Virginia Pitzer to get their thoughts on the experience, and on the changes they’ve observed at the journal since the introduction of the policy.*
Please tell us a bit about PLOS Computational Biology and your roles there.
Feilim: PLOS Computational Biology is a leading journal in the field of Computational Biology, both for sharing new research results and for describing and disseminating novel methods and software tools. In addition, our journal continues to be a leader in open science (OS), driven by our mission and by our community to, for example, increase the sharing of code used in the studies we publish. As Editors-in-Chief, we provide support and guidance for the editors, reviewers, and authors that make our journal possible. One of our roles is to nurture and broaden the best practices in our field so that the studies we publish can have the highest likelihood of re-use and reproducibility.
Why is OS/code sharing important to your journal specifically?
Jason: Code is an integral part of the research process for all those who publish in our journal and I would say increasingly integral to all research in biology. For research to truly be “open” and reproducible, we need to know how scientists arrive at the conclusions that are drawn, and where code is a necessary part of that research process, it becomes imperative that the code be shared to evaluate the results and subsequent conclusions.
Feilim: That’s right, code is every bit as much a key research reagent as an antibody or plasmid would be for experimental work — and as a research reagent, it should be available for sharing, validation, and reuse. Other researchers should be able to trust it and be able to build upon it in future studies.
What are the implications of code sharing to the future of peer review?
Jason: Peer review will need to account for code as it does for all reported methods in a paper. Where reported research does not have proper experimental controls or an experimental design does not properly account for the key characteristics of a method, peer review becomes a necessary part of a process of correction and refinement. Similarly, as the code is evaluated during peer review, it can be corrected and refined in a way that improves the scientific contribution.
Feilim: Sharing can also potentially shorten the cycles of review — for example, where previously a reviewer might have to ask particular questions to probe methods, algorithms, parameters and more, now they can go directly to the code to find what they need and potentially even run the code themselves.
Virginia: As code sharing becomes a standard part of the peer review process, it will enhance the reproducibility of computational biology research. If a reviewer finds they cannot understand or run the code underlying an analysis, it will compel the authors to be clearer in their approach and sharing of necessary resources.
Have you noticed any changes to how editors or reviewers handle peer review since code policies have been introduced? For example, has there been an increase in desk rejects?
Jason: Reviewers certainly are much more deliberate in judging whether there is sufficient code with the submission to reproduce the reported results, and editors will desk-reject papers when code is not provided. But most of the time when an editor or reviewer notes the absence of code, the authors are notified and can readily provide the requested code. I believe the code sharing policy is very much in the ethos of the journal and consequently rarely is the request a surprise to the authors.
Feilim: There has not been an increase in desk rejects, but rather an increased ability of the editors to require that code be shared before a manuscript moves forward; and an increased likelihood that authors think about this code sharing before submission. Most of our authors, as members of our Computational Biology community, are in favor of increased sharing and intend to share their code; having the requirement up front helps the authors to get this done earlier instead of relying on post-publication sharing.
Have you seen changes in behavior to the definition of authorship as a result, such as lab technicians or programmers who assist in cleaning up code receiving credit? Would you like to?
Feilim: We certainly encourage authorship to include all those who contributed to the study that is being published. We see the sharing of code, and improving code to increase re-use and reproducibility, as central to a good computational process and study.
Virginia: I think at this point, most code is written by one of the lead authors, since it is integral to the analysis. But that may change as it becomes more common for labs to hire people who specialize in programming, and as increasingly diverse or complex datasets come into common use — this is particularly true for my own work in epidemiology.
What were the top lessons or surprises each of you learned in implementation among stakeholders?
Feilim: I think that the response to implementation shows that the requirement for code sharing really reflected the goals and interests of the authors, and that instituting the requirement just encouraged or facilitated the authors to follow through on what they already wanted and intended to do. The outcome has been a continued increase in code sharing, even above the already-high baseline of code sharing in our field.
Jason: I think reviewers and editors have been nearly universally supportive of the policy. Authors have occasionally questioned aspects of the policy, but there are usually simple clarifications that assuage any concerns. For example, the journal helps authors navigate concerns around code sharing and protected intellectual property or code that involves protected health information.
Virginia: I think there is still quite a bit of variation in how in-depth reviewers will go in reviewing the code. But now at least most reviewers will check that the code is provided, whereas others may do a more thorough review and actually try to run the code.
Do you think Computational Biology’s policy has influenced data/code sharing outside of PLOS? What would wider adoption of the policy look like to you?
Virginia: As an author, I have become more conscientious about sharing my code regardless of what journal I am submitting to and whether or not they have a code-sharing requirement. I think others are also seeing this as a standard part of the publication process.
Feilim: While code has always been a key component of our journal’s papers, in recent years we can see that codes, whether for data analysis, complex visualization, or other uses, has become a much more common part of papers in all areas of biology and other sciences. There is no reason that the policy would not benefit all fields just as it has ours. The hard part — writing the code — has already been done by the authors; and sharing code is now so easy through free publicly available websites. So wider adoption of this policy would benefit the reproducibility and reuse of code throughout science, without imposing substantial additional effort.
What changes in a manuscript submission system (MSS) would facilitate better code sharing, and how might this be a barrier with our current publishing tools?
Virginia: It would be helpful if the MSS could have a required field in which authors provide the link to the code depository, rather than having this only included within the manuscript itself.
As an evolving policy, where would you like code sharing to go — what are the next steps, or dream next steps, both for your journal and more widely?.
Feilim: The policy empowers the editors and reviewers to do what they already wanted to do, which is review code and encourage sharing of code. Moving the requirement up front in the review process is essential for adoption; a post-review requirement is simply too difficult and time consuming, and doesn’t reflect the realities of our busy scientific lives.
* Note, this is a version of a post that was previously published on the PLOS blog for Peer Review Week 2023



