Editor’s note: Today’s post is by Dr. Ch. Mahmood Anwar, a research consultant, editor, author, entrepreneur, and human resources and project manager. Reviewer credit to Chef Haseeb Irfanullah.
The traditional peer review system, formalized in the mid-20th century, was designed for a world of limited print space and slower information cycles. In the current digital age, this quality control model has failed to scale. Estimates suggest that the global scholarly community spends over 100 million hours annually on peer review, yet the “reproducibility crisis” persists. Furthermore, the rise of paper mills and artificial intelligence (AI) generated fabrications has rendered manual, two/three-person reviews obsolete. A neoteric system is required to cope with these limitations: one that treats quality as a continuum rather than a binary “accept/reject” decision.

The foundation of scientific progress leans on the integrity and reliability of published scientific literature. Yet, the current landscape of academic publishing is fraught with challenges and unethical editorial and authorship practices. Traditional quality control mechanisms, from the venerable peer review to its more contemporary iterations like editorial and open review, are demonstrably struggling under the weight of increasing submissions, editorial negligence, reviewer fatigue, biases, and the sheer complexity of modern interdisciplinary research.
The consequences are catastrophic: retractions are on the rise, predatory journals proliferate, guest/ghost/gift authorship is on the rise, and public trust in scientific findings vacillates. Not to speak of predatory journals, even so-called reputed SSCI/SCIE/Scopus indexed journals are publishing nescient and flawed science. Many scholarly outlets endeavor to highlight compromised or erroneous research papers published by academic elites and appearing in top-tier journals.
The consequences are catastrophic: retractions are on the rise, predatory journals proliferate… and public trust in scientific findings vacillates.
For instance, propagation of false realities, false claims, bloopers, suspicious journals, failed scientific review, publications with fabricated data, self-promotion, and financial interests are increasingly common. These instances reflect a complete failure of the traditional quality control model followed by academic journals/publishers; I would call it the static publication model. In one simple sentence, this situation can be described as: the scientific publishing model is facing a systemic crisis that should be addressed.
This article proposes a radical departure from faltering systems of traditional static publication quality control to the “Continuum of Consensus” (CoC) quality control system, a dynamic, multi-layered, and perpetually evolving framework designed to foster genuine scholarly excellence and robust reliability of published science.
The CoC system posits that true quality in research is not a binary (accept/reject), static judgment made at a single point in time (cross-sectional), but rather a dynamic process of emergent consensus within a knowledgeable community continually refined through ongoing engagement. It moves beyond the limitations of pre-publication ostiary to embrace a post-publication, community-driven, and algorithmically augmented model of continuous evaluation.
The Pillars of the Continuum of Consensus
The CoC system should be built upon three interconnected pillars:
1. Distributed Expert Validation (DEV): The Initial Filtration Layer
Unlike traditional static peer review, which relies on a small, often overtasked, and potentially biased group of reviewers (2-3 reviewers), DEV leverages a significantly larger, more diverse pool of qualified experts/authority figures for an initial, rapid assessment of submitted manuscripts. Upon submission, a manuscript is immediately made available in a de-identified format (removing author and institutional metadata) to a broad network of pre-qualified, domain-specific validators/authority figures (15-20 persons). To optimize the CoC, the number of validators must balance statistical reliability with systemic efficiency. If the number is too low, the “consensus” is just a small group’s bias; if it’s too high, “reviewer noise” will be created. These validators/authority figures are selected based on their publication record, citation impact, outstanding achievements, and a demonstrated history of constructive scholarly engagement within their field. They are incentivized through a transparent reputation system (TRS) that tracks their contributions and accuracy.
The TRS operates as a blockchain-backed ledger of “intellectual labor.” Reputation is not determined by reviewing frequency; it is gained by being right. If a validator gives a high score to a paper that is later retracted or fails a “reproducibility challenge” in the adaptive peer-community refinement (APCR) phase, their TRS score is automatically adjusted downward. The TRS creates a meritocratic hierarchy. High-reputation validators’ scores carry more weight in the weighted consensus score (WCS) algorithm, whereas low-reputation validators’ scores carry less weight in the WCS algorithm. Experts receive an initial allocation of “validation tokens” (VTs) based on their historical record. When they participate in the DEV stage, their accuracy (measured against the eventual consensus) results in the “minting” of new tokens. The VTs assigned on the basis of reputation are not just vanity metrics. They could be used to offset article processing charges (APCs), gain priority in submission queues, or serve as a verified “service to the profession” metric for institutional tenure and promotion files, as proposed in a Scholarly Kitchen article.
DEV does not involve detailed critiques or editorial suggestions. Instead, validators rapidly assess the manuscript against a set of following suggested core criteria:
- Theoretical Development (0-5 scale): Does the article test, extend, and/or build theory?
- Methodological Soundness (0-5 scale): Is the methodology described clearly and appropriately for the research question?
- Data Integrity (0-5 scale): Does the manuscript provide sufficient detail to assess data collection and analysis?
- Significance of Contribution (0-5 scale): Does the research address a meaningful problem or offer a novel insight?
- Clarity of Presentation (0-5 scale): Is the writing clear, concise, and comprehensible?
- Ethical Oversight (0-5 scale): Do authors follow ethical standards to conduct the research?
Each validator submits a score for each criterion along with a confidence rating (e.g., low, medium, high). An AI-powered algorithm then aggregates these scores, weighted by the validator’s confidence and reputation. Manuscripts exceeding a predefined aggregate threshold move to the next stage. Those falling significantly below are flagged for immediate re-evaluation by a smaller, more intensive panel of authority figures (3-5 persons) or, if critically deficient, are rejected with detailed algorithmic feedback based on aggregated validators’ input. This initial layer acts as a rapid, high-throughput filter, identifying strong candidates and quickly winnowing submissions with fundamental flaws. At the conceptual level, the DEV system is shown in Figure 1.
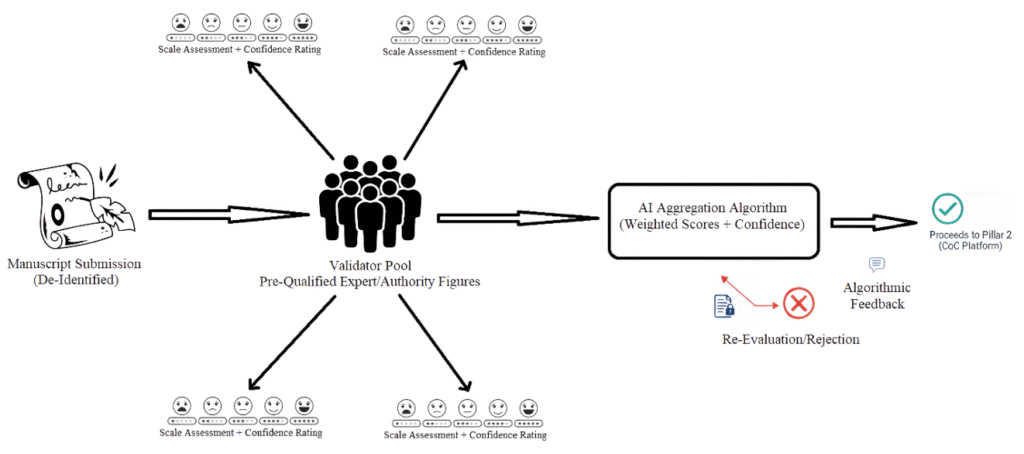
Traditional review requires 2–3 people to do everything, e.g., check math and stats, theory, grammar, and ethics. This practice is exhausting. The DEV layer uses “micro-validations.” A validator does not write a 3-page essay; they are providing rapid, 0-5 scores on specific dimensions they are uniquely qualified for. This “high-throughput” model is significantly faster for individuals than a traditional static peer review system. The burden on the individual may be felt high because we think in terms of a small pool, as utilized in traditional static review.
By de-identifying and distributing work to a larger pool, the “per-person” frequency of requests decreases. By the time a manuscript reaches the “senior expert panel,” it has already been stress-tested by the DEV and APCR layers. These senior experts are no longer “concierges” cleaning up basic theoretical, methodological, and reporting errors; they are, in fact, high-level “architects” focusing only on the most refined work.
2. Adaptive Peer-Community Refinement (APCR): Deep, Iterative Engagement
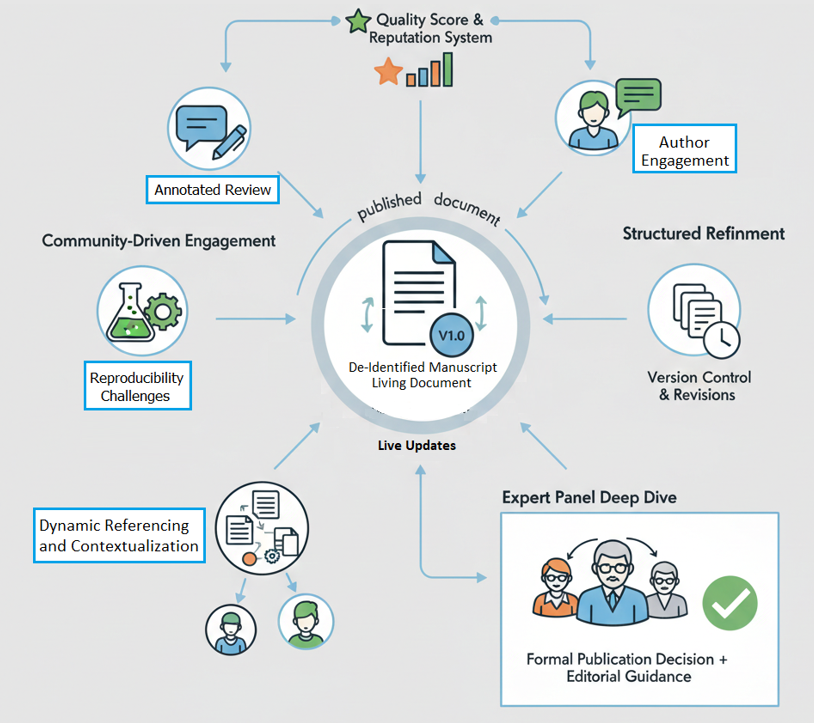
Manuscripts successfully crossed the DEV stage are then moved into the APCR environment. This stage represents a continuous, open-ended process of refinement and validation, moving away from the fixed-point decision-making used in the traditional static publication system. Here, the de-identified manuscript is posted on a specialized platform where the broader scholarly community (again, 10-15 qualified and reputation-tracked persons) can engage in deeper, more nuanced critique and discussion.
Key features of APCR include:
- Annotated Review: Community members can highlight specific sections, propose edits, ask questions, and offer detailed critiques directly on the manuscript. These annotations are visible to all, fostering a transparent and collaborative environment.
- Reproducibility Challenges: For empirical studies, the platform allows for “reproducibility challenges” where community members can attempt to replicate findings using provided data (or request access to it). Successful replication attempts significantly boost a manuscript’s quality score, while failed attempts trigger a deeper investigation and potential revision requests.
- Dynamic Referencing and Contextualization: As new research emerges, the CoC platform dynamically links related studies, providing context and allowing for the continuous re-evaluation of prior published work in the light of new evidence. This addresses the “shelf-life” problem of static publications.
- Author Engagement: After an initial period of community feedback, authors are invited to respond to critiques, revise their manuscript, and clarify points directly on the APCR platform. Their revisions are version-controlled and transparently tracked.
- Expert Panel Deep Dive: For manuscripts approaching publication readiness (based on positive community engagement and high-quality scores), a smaller, curated panel of senior experts (3 persons) is convened to conduct a final, comprehensive review. This panel provides in-depth editorial guidance, ensures ethical compliance, and makes the ultimate decision on formal “publication” within the CoC system. However, even post-publication, the manuscript remains open for further community engagement and potential dynamic updates.
It is worth noting that the “reproducibility challenge” is not a mandate for every submitted empirical paper, but a voluntary stress-test triggered by the community or the authors themselves to gain a “high-reliability” badge. As far as authorization for replication is concerned, no one authorizes it; the data are open by default. In the CoC model, data transparency is a prerequisite for entering the APCR stage. The “costs” incurred on reproducibility are offset by the TRS.
A researcher who successfully replicates a study earns a massive “reproducibility bonus” to their reputation, which is a significant career incentive. Regarding ownership, the replication is a “child-node” of the original work—both are linked on the blockchain, creating a collaborative credit-sharing model rather than a competitive one. Community members who successfully raise a “reproducibility challenge” or provide high-value annotations receive a “reputation multiplier,” increasing the weight of their VTs in future consensus scores.
APCR accentuates that a “published” article is never truly final but rather a “living document,” constantly refined and validated by the collective intelligence of the scholarly community. This system inherently mitigates bias through sheer volume and diversity of input, and it actively incentivizes constructive engagement over superficial review. The CoC does not destroy “permanence”; it introduces “versioned permanence.” Just as a software version (e.g., Windows 11) is a permanent, citable entity even as the code evolves, a CoC publication is a series of “frozen” milestones.
This concept is called the git model for science. Currently, a flawed paper stays in the record for years until a formal retraction occurs. In the CoC, if new data makes a finding obsolete, the “living document” status allows for an immediate dynamic correction. This does not make the old version disappear; it simply ensures the “current consensus” is what the public sees first. This is more scientifically honest than leaving a “static” but incorrect paper uncorrected.
At the conceptual level, the APCR ecosystem is shown in Figure 2.
3. Algorithmic Integrity Oversight (AIO)
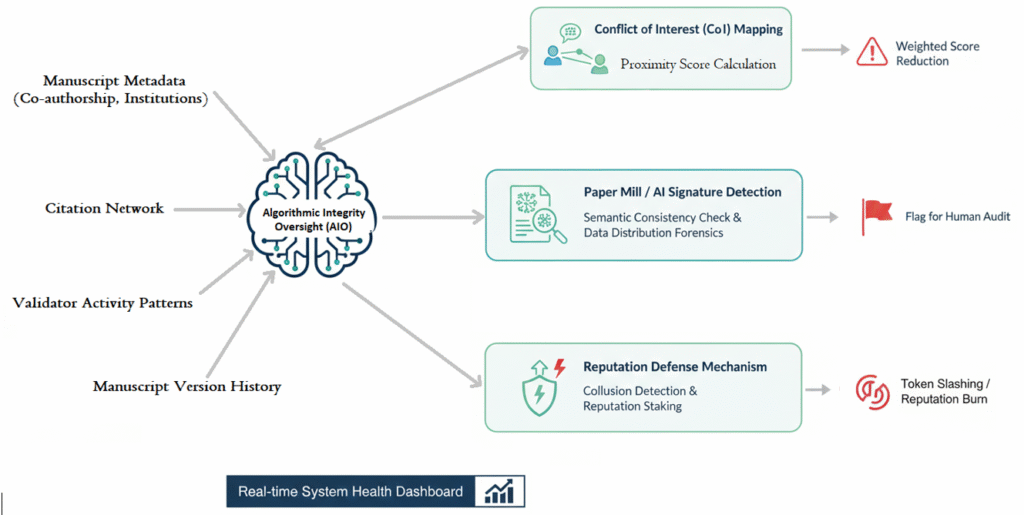
While the first two pillars rely on human intelligence, the AIO pillar is the “digital immune system” that protects the platform from systemic manipulation. It operates as an autonomous layer that monitors the health of the consensus.
- Conflict of Interest (CoI) Mapping: The AIO uses a “knowledge graph” to map relationships between authors and validators. It calculates a “proximity score” based on co-authorship history, institutional affiliation, and even citation frequency. If a validator is too close to an author, the AIO automatically reduces the weight of their weighted consensus score (WCS) contribution to near zero.
- The Paper Mill/AI Signature Detector: Using the deep-structure integrity engine (DSIE), the AIO scans for the low-entropy, repetitive logic structures common in AI-generated fabrications. It flags manuscripts that appear “too perfect,” or that lack the messy, iterative version history typical of human research.
- Reputation Slashing: If a group of validators is caught in a “collusion circle” (consistently upvoting each other’s mediocre work), the AIO triggers an automatic audit. If collusion is confirmed, the validators’ validation tokens (VT) are “slashed” (destroyed), and their reputation is permanently burned on the blockchain ledger.
The AIO system is shown in Figure 3.
The Integrated CoC Ecosystem
With all three pillars in place, the system functions as a self-correcting loop rather than a linear assembly line. The crux is shown in Table 1 below:
Table 1: Overview of Continuum of Consensus (CoC)
| Pillar | Focus | Human vs. AI | Metric of Success |
| 1. DEV | Initial Technical Soundness | Distributed Humans | WCS Threshold |
| 2. APCR | Open Stress-Testing & Replication | Collective Humans | Reproducibility Bonus |
| 3. AIO | Systemic Defense & Bias Removal | Autonomous AI | Proximity Penalty |
By integrating these three pillars, the CoC ensures that research quality is not just a static opinion, but an emergent property of a rigorously monitored scientific community. In Table 2, the difference between static review and CoC is presented.
Table 2: Traditional Review vs. Continuum of Consensus
| Feature | Traditional Peer Review | Continuum of Consensus (CoC) |
| Reviewer Pool | 2–3 Individuals (Closed) | 20+ Distributed Validators (Open/De-identified) |
| Timing | Pre-publication | Continuous (Post-publication) |
| Transparency | Highly Opaque | Full Audit Trail |
| Incentive | None/Altruistic | Reputation Tokens / Growth |
| Outcome | Static PDF | Living Document / Evolving Data |
How is CoC Different from the Community Peer Review System?
The CoC differs from traditional community review (like those on preprint servers) because it uses active orchestration and algorithmic weighting. Most community reviews fail because they are passive; they wait for someone to show up. The CoC DEV layer actively “pushes” manuscripts to qualified validators based on their profile, rather than waiting for “volunteers.” Community review usually offers no reward to volunteers. However, in the CoC, active engagement with the system is the only way to build validation tokens (VT) and reputation. Unlike a comment section on a blog, the adaptive peer-community refinement (APCR) is integrated into the version control of the manuscript. Community feedback is not a side-note; it is a “reproducibility challenge” that directly shifts the manuscript’s weighted consensus score (WCS).
Conclusion
The continuum of consensus (CoC) replaces the fragile, binary gatekeeping of the past with a robust, community-driven ecosystem. By leveraging distributed expertise and treating publications as evolving entities, we can restore the integrity of the scientific record.
In the CoC system, legal liability remains with the authors and the host platform (The CoC Entity). However, the CoC system provides a superior audit trail. In the traditional model, if a paper is fraudulent, the 2 reviewers are rarely held accountable. In the CoC, the de-identified, timestamped logs of all 40 participants and the AIO’s integrity scans provide a “black box” recorder of the publication process, making it easier to identify where the oversight failed.
In the proposed system, although 30-40 total people may touch the paper, only the last 3 (the deep dive panel) conduct “heavy lifting.” The others perform “distributed micro-labor.” This makes the CoC system more robust than the traditional static peer review model but less burdensome for the average participant, as the responsibility is shared across a specialized network rather than dumped on two/three exhausted reviewers.

Discussion
18 Thoughts on "Guest Post — Re-imagining Scholarly Integrity: The “Continuum of Consensus” Quality Control System"
Many journals use an iterative process where suggestions are made, the author responds, reviewer reviews. This means the accept\reject is not just a binary process.
In traditional static peer review system, the decisions are always binary. There maybe exceptions but its about majority. Thanks for your valuable contribution Daniel.
Bravo! This is good stuff!! I reckon there’s a weakness in initial identity registration management, but I also think there’s a way to counter-act that. There are some other people also thinking on these lines. I’m also not yet sure that it needs to be a blockchain — yet if existing tooling providers are slow, or reticent, to collaborate, sure — why not?! Blockchain could sure use a big, juicy use-case.
Kudos to you, sir! As always, you’re on-point with excellent timing. 😊
I upvote you a bunch of the initial batch of tokens. 😉
Excuse me while I happy-dance in the living room. Looks like the industry is starting to seriously consider the need to build new digs. Eindelijk!
Yes. Technology has become advanced. Blockchain can do much better. Thanks for reading the piece.
This all sounds really neat. When you say “their TRS score is automatically adjusted downward”, who does the adjusting?
It’s the system that will be programmed to do it.
I would be concerned with any system that is replacing 2 or 3 reviewers with 40 people and half a dozen AI systems. This seems overly complicated from my end. But more importantly, to me the biggest problem is one I described back in 2015, essentially, who cares?
https://scholarlykitchen.sspnet.org/2015/06/17/the-problems-with-credit-for-peer-review/
Not who cares about peer review or who cares about the important work done by peer reviewers, but instead, any system built around awarding credit must be validated by those who can offer the rewards a researcher actually needs, basically jobs and funding. If no one is likely to hire you as a professor nor fund your research project because you’re a really good peer reviewer, then what value will all of these tokens have in the career progression of a scientist?
Thanks for the read David. Technically, Right. The proposed system is complicated. But, it’s an automatic system which requires least human efforts in selecting Validators/Authority Figures. We already know that traditional peer review has been badly failed. Top-tier journals like Journal of Management, Journal of Business Research, Journal of Business Ethics, Journal of Occupational and Organizational Psychology, Journal of Knowledge Management, Scientific Reports etc. are publishing bad/erroneous research? So, what to do? How to believe published science? Watch dogs like Retraction Watch and Scholarly Criticism are monitoring the situation but again who cares. I believe that we should address the problem of flawed static peer review system. Otherwise, science will sacrifice. As far as rewards are concerned, if institutions adopt the system at consortium level, the benefits can be extended to hiring and promotion. Thanks a lot, David!
Fair points, and I do agree with the 2015 piece, when considering as-is.
Given AI-assisted writing, I’d venture that we should all be caring much more about critical reading skills, and quality reviewing should be formalized, weighted and credited.
If we provide data, I believe that institutions will use it. Data makes comparison and ranking simple. Everyone likes simple.
I reckon the core challenge is responsible data gathering and values alignment in designing ‘what counts’. Happy to see a proposal that attempts this!
I agree completely that bean-counting reviewer credit schemes are bad. They generate perverse incentives.
I’m not convinced that the breakdown provided here is best — but I’m delighted that a breakdown is proposed.
I sense a push into data-assisted participation vetting. Not sure yet how I feel about that… needs more unpacking.
I am intrigued by this article. Very interesting work and looking forward to talking more!
Thanks my Prof. I hope to talk soon!
Thanks for the insightful post. I agree that while we need to keep the useful parts of the traditional article, i.e. a clear narrative or “story”, well written, copy edited, and well presented, the research assessment itself needs to change from the current model that is essentially paper based. I hope it is not a distraction to give a link to my presentation on what I called micropublishing, with some ideas that overlap with yours: http://bit.ly/kaveh-micropublishing .
Thanks for comment Kaveh. CoC is the need of today. Hopefully we will see it in action in near future.
Good luck with trying to get a “broad network of pre-qualified, domain-specific validators/authority figures (15-20 persons).” The only people likely to form that broad network will be those in it to game the system. There is simply far too much research being output and too few good researchers to keep up with demand for peer review. Vast majority of research adds little to what we already know. The current model has failed and tweaks won’t fix it. More radical solutions are needed. Probably some kind of AI system that evaluates novelty of research and implications.
This is what I recommended in the CoC system, Dan. Thanks for comment!
The system that you propose is highly simplistic. In particular, you state that: “Reputation is not determined by reviewing frequency; it is gained by being right. If a validator gives a high score to a paper that is later retracted or fails a “reproducibility challenge” in the adaptive peer-community refinement (APCR) phase, their TRS score is automatically adjusted downward.”
Reproducibility is not the same as “being right.” Indeed, there are many study areas where a large body of research was considered to be “right” and widely reproduced but then found to be based on misinterpretation or even research fraud. A “right” result could also support many other alternative hypotheses, but these might not be favored by a group of say 15 researchers who all have a vested interest in maintaining the status quo. Failure to reproduce the findings of a study can also lead to major novel insights, mainly because the original study failed to adequately consider various parameters/behaviors/factors. I see your proposed system as one that fails to promote or even allow novel insights, which are what we need.
You are mingling two different things. Being right mean “the validator should not allow wrong” that can be later retracted or fail reproducibility. Let’s talk about the criticism published in Scholarly Criticism here: https://scholarlycritic.com/wrong-sampling-strategy-ruins-the-study-published-in-plosone.html . This study used wrong sampling strategy which was later identified by watchdog. This should have been identified by the validator/reviewer. So, reviewer was not right. Reproducibility is crazy. Hence, his TRS should be slashed. Please note that Right and Considered to be right are different. May be one finding is based on statistical error, fallacy, or socially constructed academic artifact. It’s the responsibly of the validator to point it out at APCR stage. As far as the accuracy of the proposed CoC system is concerned, it will, of course, undergo stress tests to identify it’s weaknesses and overcome them. Thanks for your comment.
Thanks for your reply and patience. The example that you present is a particularly terrible piece of research (now retracted) and it is shocking that it was even sent out for review never mind being accepted and published. I am more concerned about a reviewer being later punished by your system for recommending publication of seemingly good research that was fraudulent (e.g., recall the resveratrol mess: https://www.science.org/content/blog-post/resveratrol-research-scandal-oh-joy) or in some other way flawed. People defending their research area would happily recommend publication of work that fits their agenda. And reviewers with specific agendas have always been apt to find any reason at all to reject if the results/conclusions of a study disagree with their viewpoint even when there is nothing “wrong” with a study. In the case of your example, not being right is easy to judge because of methodological deficiencies but this is not the case for many more studies. I am of the opinion that good research with no methodological, statistical, or logical flaws should be published regardless of whether someone disagrees with the authors’ interpretation of the results. Someone may consider that the interpretation of the results is “wrong” even though it may be logical under a certain hypothesis, so how would your system deal with that? I can see your system working as a quality filter to weed out garbage research but it lacks the subtlety to be effective at higher levels.



