
All PLoS articles are published under the Creative Commons CC-BY License, a license that permits “unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.”
The issue with the two offending journals wasn’t that they republished PLoS articles — this is permitted under CC-BY — but that they did so without attribution.
Comments expressed by those who had been republished cite more concern than just republication of their work. It is not necessary to get approval from the copyright holder to reuse, remix, or republish (commercially or non-commercially) a CC-BY article. Clearly the designation of one’s work — the journal in which the article appears — is a concern, even for those who publish with PLoS.
“That is distressing, because we’ve never submitted an article to Science Reuters,” said Mark Johnson, an associate professor at Brown University. “I’m not even aware that Science Reuters is a journal.”
To me, the concerns of the authors have nothing to do with open access publishing but about the concern academics have over the context and designation of their work. If authors are willing (or required) to publish under the CC-BY license, they should not be surprised when their work shows up in surprising places.
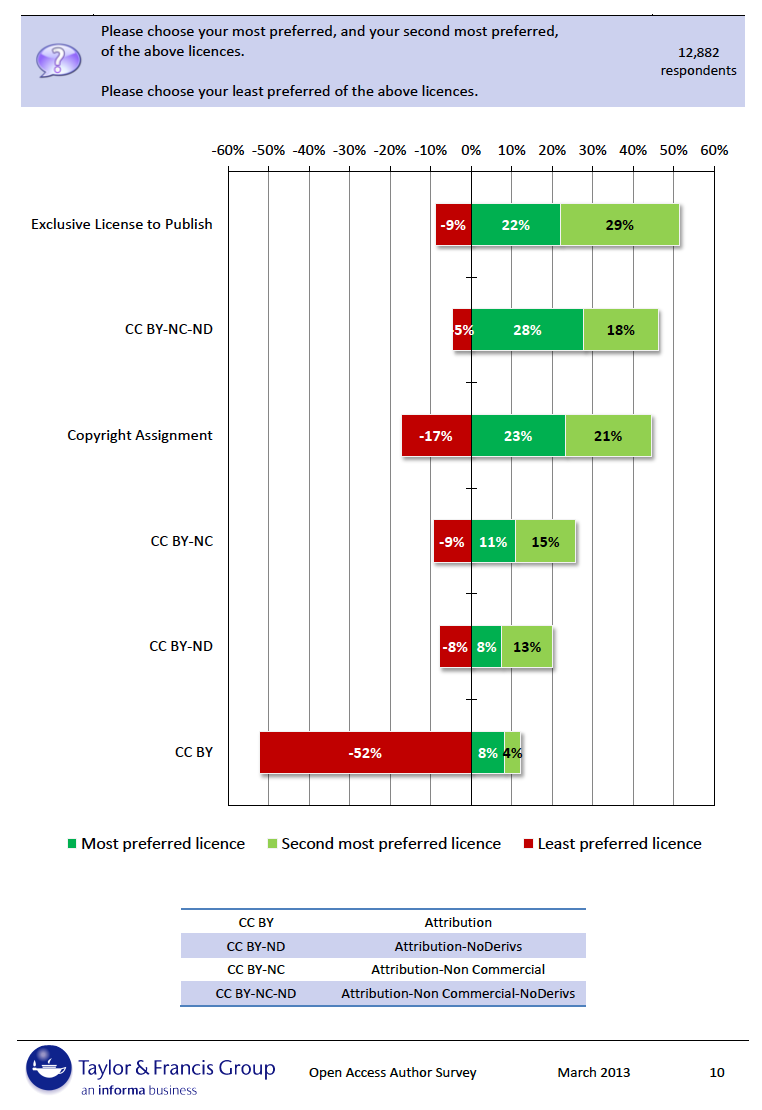
The recent Taylor & Francis open access survey of authors reveals their general hesitancy toward the CC-BY license, with most respondents selecting the most restrictive exclusive license to publish as their top choice, followed by an open access license that puts severe constraints on how the content is used.
If open access is to be embraced by the broader academic community, is free access sufficient? Or does it necessarily have to mean completely unrestricted usage?


Discussion
33 Thoughts on "CC-Bye Bye! Some Consequences of Unfettered Reproduction Rights Become Clearer"
It’s as if you need a particular licence that optimises scholarly/research reuse and further study – under the ethical and professional norms of the field including research integrity and reputation – that avoids this kind of wanton commercial republication which I can only assume is to bolster another company’s position in the market rather than aiding scholarly and scientific pursuit in and of themselves.
Probably something that builds in text and data mining, as well as other relevant and research specific reuses (even where that research may be a private company).
Is this something researchers actually want, though? That should be the critical question, if practices and culture are to evolve as many hope they will.
Is licensing really an issue for text mining and search? Google and other private companies seem to do this perfectly well under traditional copyright. I think the real issue for those who want to do these things is access. I can make it explicitly legal for you to text mine my journal, but unless I provide you a means to bulk download, spider or an API, it doesn’t mean much.
David
A recent article in Elsevier’s Connect magazine made it clear that, in their opinion, articles published under an ND licence are NOT mineable. See http://elsevierconnect.com/what-changes-when-publishing-open-access-understanding-the-fine-print/
This suggests that, contrary to your assertion, licensing **is** an issue for text mining.
I think their opinion is flat-out wrong.
If what they state is correct, then none of their ND articles could be indexed by Google or PubMed without each group specifically acquiring explicit permission for each individual article. Further, it would be illegal for me to read an article on their website and search (“control f”) in my web browser for a specific term. That is “text mining”. It would be illegal for me to make a table for my own personal use compiling gene expression data in different tissues from multiple papers. That is “data mining”.
Really I think there’s a general misunderstanding about the difference between “using” an article and “reusing” an article. These sorts of license, like copyright, apply only to redistribution and reuse of the specific words in the specific order–“Copyright does not protect facts, ideas, systems, or methods of operation.” What that means is that these licenses apply to me trying to redistribute the full text of articles or resell copies of those articles. Distributing the data from a text mining experiment is not the same thing as distributing the copyrighted papers.
They can certainly try to set terms of use that prevent me from doing these things, or set up their websites to block such activities, but that’s a different issue than the copyright terms. To quote Mike Rossner’s important article on this subject:
http://jcb.rupress.org/content/201/1/7.full
The Intellectual Property Office of the UK government recently issued a clarification of the rights afforded by existing UK copyright law “to allow non-commercial researchers to use computers to study published research results and other data without copyright law interfering”. There is legal precedent in the United States to indicate that the right to mine text and data from published research articles can fall into the category of “fair use,” and thus any entity—noncommercial or commercial—may be permitted to do so under any license.
David,
Yes, the UK government (in response to Hargreaves Review) has said it will introduce a copyright exception to allow text and data mining. These Regulations, however, have not yet been published so at the present time there is no copyright exception in the UK to allow text and data mining.
As I understand it, to undertake TDM you need to make a copy of the work — and that is what triggers the copyright issue.
This issue will be solved (in the UK) once the TDM regulations are enacted.
Robert
To read an HTML or PDF version of an article in a journal, you need to make a copy of the work. Does that trigger the copyright issue as well? Is reading an Elsevier journal article on a computer not allowed?
And again, is Google breaking the law? PubMed? Why don’t they need special licenses to text and data mine?
IANAL and all that, but I believe the length of time the copy exists for has some bearing here. I think there’s some case law out there (US law) where copies held in memory don’t count. Though we are rapidly heading down the rabbit hole at this point – what sort of memory? would a magnetic hard drive be a problem…
This raises a lot of interesting questions. First, is “plagiarism”, the word used by The Scientist, the right word here? The articles are attributed to the correct authors, no one is claiming their words as their own. This is more a licensing matter.
Second, if, as some have argued, we should judge the work solely on the paper itself, and not on the journal in which it’s published or that journal’s Impact Factor, then why does attribution matter? Shouldn’t we just read the work and judge it on its own merits?
Third, if I’m starting a new journal, it seems perfectly legal and reasonable to cherry pick the top papers from all CC-BY journals and republish them in my title, with a tiny attribution line buried somewhere in the acknowledgments. Then I can claim those papers and those authors as having published in my journal, implying their endorsement, listing them in advertisements and promotional mailings. And I don’t need their permission to do so, as they’ve already given it through accepting the CC-BY license.
And how does this affect abstracting and indexing services, things like PubMed or even the Impact Factor when there are multiple versions of an individual article out there published under different journal titles?
Revolutions are always complex critters with unexpected behavior. The kind of reprint journal you describe is probably a likely outcome of OA, not an abberation. It would be a very useful discovery tool with potentially a very high impact factor because all the papers would be highly citeable. The question is whether it would be granted an impact factor? And I suppose the papers would have to be cited via the reprint journal so it then competes with the original journals for citations. An interesting project.
But you are correct that there is no plagiarism and authors need give no permission. That is what CC-BY open means and there are lots of possibilities that will seem strange at first or even shocking. How about videos or podcasts where papers are read aloud by computers? The original authors may not like the graphics or voices used but too bad.
It might be “perfectly legal” to “cherry pick the top papers from all CC-BY journals and republish them” in another journal, but it certainly isn’t reasonable or ethical. From the ICMJE guidelines on overlapping publications:
“Redundant (or duplicate) publication is publication of a paper that overlaps substantially with one already published in print or electronic media.
Readers of primary source periodicals, whether print or electronic, deserve to be able to trust that what they are reading is original unless there is a clear statement that the author and editor are intentionally republishing an article. The bases of this position are international copyright laws [not relevant here], ethical conduct, and cost-effective use of resources. Duplicate publication of original research is particularly problematic because it can result in inadvertent double-counting or inappropriate weighting of the results of a single study, which distorts the available evidence.”
Well, the shady journal I’m proposing would have a statement that the article was republished, it just might not be in a terribly obvious place. And being ethical doesn’t seem a requirement for journal publishers of many different stripes and sizes.
Does the ICMJE statement mean that PubMed Central and institutional repositories are unethical and a waste of resources?
There is nothing shady or unethical about a reprint journal. Given the topi-free mega journals it makes good sense.
If there is some “reasonable or ethical” restriction on duplicate publication from someone other than the author, why not retain copyright to control that? One can’t have it both ways. If you want to control the republication process and control what happens to this, than retain copyright. ICMJE’s ethical guidelines are meant for instructions to authors, not publishers. One might argues (although I don’t see the point to in this case) that the republication of “top articles” falls directly under the “Acceptable Secondary Publication” section of the ICMJE’s guidelines. One could read that an author’s choice to use CC-BY is an explicit statement of their willingness to allow such secondary publication with attribution.
I wrote about this issue with CC licenses and why retaining rights might be valuable on SK, http://scholarlykitchen.sspnet.org/2012/10/01/why-restrictions-on-reuse-are-sometimes-important/ but interestingly the comments generally disagreed with my points.
So the attribution in CC-BY is only to authors and not to the originally published version (i.e. the full citation)? I assumed that it implied a full citation. If this is true your scenario with journals cherry-picking seems likely, which could lead to a potential citation/indexing mess.
No, I believe you’re supposed to give a full citation. But there’s no specific requirement for how that’s done, how prominent or obvious it is. It could very well be buried in the fine print and still meet the terms of the license.
Mega-journal systems like PLoS actually cry out for reprint journals that do what journals do best, namely sort articles by relevance and importance. Structure is valuable.
Also corrections and retractions; should a paper that was republished elsewhere then be retracted/corrected in the original journal, it seems unlikely that this will always follow through to the reproduced version.
When someone infringes an All Rights Reserved piece, someone else (publisher usually) has a money interest that is being threatened by that infringement. Courts are quite comfortable in adjudicating such questions, much more so than they are in adjudicating questions about attribution (BY), re-mixing (SA) and so on. As well, deciding whether it is cost-effective to pursue infringement is far more feasible where there is a money interest.
We simply haven’t figured out or fully invented the ‘some rights reserved’ side of the coin. We need to.
That monetary interest is worth considering–when publishing with a journal under traditional copyright (or at least a non-commercial reuse license), there’s a financial incentive for the journal to act on the author’s behalf, to put their legal staff to work shutting down questionable or disreputable reuses of the author’s work, hence protecting their reputation. These incentives go away under a CC-BY license, the publisher has nothing to gain by protecting licensing rights, and the author is left to fend on his/her own.
Does the publisher even have any remit to litigate on behalf of the author – they’ve got no rights in this situation. My reading of CC-BY is that it’s down to the author, though if they’ve been mandated to use the license then one presumes the agent who insists on the mandate should make provisions to defend breaches of the terms of the license.
An author is given the choice publish with us under a cc-by contract or go somewhere else. Once the author goes with the cc-by publisher the publisher has no obligation to protect the author.
Excellent point! If a secondary publisher can get away with removing the attribution to the original article, what else can they change? Could they distort the findings? Under these new licenses, we may find ourselves in a situation where authors have to certify their copy-of-record.
Ironically, this could be the salvation of traditional journals with established branding for integrity. If distrust of modified articles becomes so high, serious researchers may restrict themselves to reading journals they trust. (But, don’t count on this selectivity for the casual reader!)
well, they can, for example, translate it into another language. The author won’t have any control over the quality of the translation. I would bet that there are reprint translated versions of CC-BY papers in Iran and China already. We find out that our papers have been translated and republished without permission for our copyrighted material every so often.
Yes, and they could create an abridged or otherwise version also, so long as there was no purposeful distortion going on.
I think of all the “predatory” OA journals on Beall’s list that will benefit from republishing “quality” papers from other journals in an effort to give their own startups credibility and acceptance. This will give new meaning to the term “predatory.”
One could create a methods journal by topic and just pick the methods from journals and republish them. Thus, one could publish modern methods in toxicology, genetics, etc.
I would bet they would do fairly well in the marketplace.
Indeed Harvey, I wrote about this need some time ago:
http://scholarlykitchen.sspnet.org/2011/10/11/my-utopian-vision-for-communication-of-scientific-methods/
Having been the Editor in Chief of a methods journal, I can tell you the problem with this. Most journals publish very little by way of methodological detail. To provide a meaningful and useful set of methods content, you need step by step protocols, troubleshooting information, a full list of reagents and equipment, etc. Very few (any?) journals provide this sort of information in their papers.
So likely, you’re better off doing what I did, which was to use data reporting journals as scouting material, look for papers with interesting methods and then commission new, original articles that give the useful details.
David: Forgot just how skimpy the method part of an article is.
My concept is broader so requires less detail. For example semantic analysis is being explored in many disciplines, from medicine to social science, with advances scattered all over the science map. My editorial board or some such would be experts in these methods from different disciplines and they would nominate important papers for inclusion in the reprint journal. The detail that is normally provided is enough because the papers are often focused on the methods as much as the topical science. Papers that merely apply standard methods to new topics would be of no interest.
To put it another way some papers are really primarily about methods, especially where this is where the advance lies.
Or review articles? This discussion bring us back to the concept of the “overlay journal” proposed more than a decade ago as working on top of repositories like the arXiv. However, the original concept was that editors would select articles from the repository that met relevance and quality standards and provide certification through the aggregation. The overlay journal was also intended to be a collection of links back to the source of the paper, not a republication of the paper itself.
The ICMJE Uniform Requirements only apply when submitting a paper to an ICMJE signatory publication for review and publication. The ICMJE Uniform Requirements do not explicitly prohibit republication in non-signatory journals (after initial publication) because the journals would not have the power to stop such activity unless the original publishing journal owned the copyright to the work. However, the Uniform Requirements do prohibit ICMJE signatory journals from republishing articles previously published in either an ICMJE signatory or non-signatory publication – unless permission is granted by the original publishing journal and the original article is fully cited as having first been published in the original journal. I believe the Uniform Requirements also require that this activity be limited to times when there would be an academic reason to republish (such as, the second journal reaches an audience that would not likely read the first journal but would never-the-less find the content of the article useful). Since the publication in instance is not an ICMJE signatory and the authors did not submit the article for republication, this activity would not violate the ICMJE Uniform Requirements.


