 The publishing community itself is currently focused on building platforms, creating knowledge graphs from their assemblages of linked data and building a variety of software workflow options in support of the research process. At library conferences, one hears of collaborative processes between researchers and librarians as they build new tools or databases for purposes of investigation and inquiry. But we don’t hear as much discussion of what the scholarly record itself is becoming.
The publishing community itself is currently focused on building platforms, creating knowledge graphs from their assemblages of linked data and building a variety of software workflow options in support of the research process. At library conferences, one hears of collaborative processes between researchers and librarians as they build new tools or databases for purposes of investigation and inquiry. But we don’t hear as much discussion of what the scholarly record itself is becoming.
It’s too early to dismiss the concept of the monograph or the journal. Those are the descriptive packages most easily recognized by scholars and (let’s be honest here) the forms of output still most broadly acceptable to committees in charge of tenure and promotion. While we know that the scholarly record is “morphing”, we aren’t really sure what it looks like or how rapidly the final form of that record may emerge.
Being a Jane-ite, allow me to begin with a digital humanities project that has captured my heart. Professor of English at University of Texas – Austin, Dr. Janine Barchas has spearheaded a digital heritage project known as What Jane Saw. The project examines the concept of celebrity in Georgian England as documented in two significant London art exhibitions visited by Jane Austen in the years, 1796 and 1813. The project has resulted in a variety of traditional and non-traditional outputs conveying the substance of Dr. Barchas’ studies – a website, two virtual reconstructions of historical exhibit spaces as well as digital replication of artwork, embedded videos, two journal articles, and a full-length monograph produced over the course of a five-year time span. The content is accessible via multiple platforms – disseminated via the Web as well as being accessible via a searchable institutional repository. What Jane Saw has received coverage in the New York Times (thereby adding to the prestige of the University of Texas) and will undoubtedly receive more media attention when a related, curated exhibit at the Folger Shakespeare Library opens in the fall of this year. It is, in my view, an immediately accessible example of the evolving scholarly record. There are others of course — extensive collaborative efforts, such as the William Blake Archive.
In the context of STM publishing, the record of scholarship is equally diverse. The Journal of Video Experiments has enjoyed singular success, proudly displaying its impact factor of 1.325 on its home page. The publication is entirely focused on the use of video in presenting experimental research.
There is the recently launched overlay publication, Discrete Analysis, which provides an easy mechanism for discovery of and access to papers in the field of mathematics housed on the pre-print server, arXiv. Don’t forget the Research Ideas and Outcomes (RIO) Journal which “publishes all outputs of the research cycle, including project proposals, data, methods, workflows, software, project reports and research articles together on a single collaborative platform.”
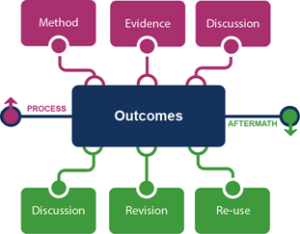
These trends were summarized in the recent OCLC Research report The Evolving Scholarly Record, which sketches out the broad contours of a scholarly record evolving in parallel with changing scholarly publication practices. As the picture above suggests, the boundaries of today’s scholarly record are stretching to incorporate a diverse array of materials generated during the process of scholarly inquiry – materials relating to methodology (e.g., computer models, algorithms, electronic lab notebooks); evidence (e.g., data sets, survey results, new primary source documents); and pre-publication discussion (e.g., blog posts, preprints, grant proposals reviews) – as well as materials produced in the aftermath of publication: post-publication discussion (e.g., blog posts, commentaries, reviews); revisions (e.g., enhancement/clarification of findings, corrections); and reuse (e.g., conference presentations and posters, versions for non-scholarly audiences). These and other byproducts of research activity are forming a constellation of ancillary materials around more traditional published scholarly outcomes like journal articles and monographs. Very little of it is in library collections: instead, it is scattered around the network in data archives, institutional repositories, commercial digital repository services, and elsewhere.
Of course, the scholarly outputs represented in the image above are not new; they have always been part of scholarly practice, in one form or another. Until recently, many of them were for all intents and purposes inaccessible, if they were kept at all, forming a “shadow” scholarly record existing in personal file cabinets, desk drawers, (and more recently) laptops, flash drives, and private servers. But today, many of these same materials are now entering the “permanent” scholarly record, through systematic efforts to gather and curate them, as well as make them persistently reference-able, discoverable, and accessible. The result is a scholarly record that is a much deeper documentation of scholarly inquiry than anything we have seen in the past.
New roads have had to be cut in order to get here. In recent years, particularly in the realm of the humanities, Ph.D. candidates have been counseled about the need to include (as part of their publication plan) articles that outline the workflow and team processes for creating the final digital output presenting their findings. (For example, see the 2012 article describing the process used by Barchas and her team in building What Jane Saw. ) We are progressing beyond the point where that explanation of the mechanics of digital scholarship may be needed, but we’ve not completely arrived. The most serious imperative for scholars themselves continues to be identifying and enabling the forms of presentation that enable a swift grasp of what their scholarship accomplishes and enables re-use by those who choose to build upon it. The three or four examples provided earlier would seem to suggest that the scholarly community is moving in the right direction.
At the risk of boring industry experts who read the Scholarly Kitchen, allow me to recap recent history for newer participants and lay some of the groundwork for future discussions.
What is the purpose of scholarly publication? From the perspective of the researcher, the primary purpose is (1) to document current investigations; (2) broaden awareness of new findings through dissemination; (3) to enable re-use and/or corroboration and finally, (4) to suggest possible directions for future research undertaken by a rising population of scholars. Yes, there are rewards tied to various degrees of contribution associated with this process, but fundamentally, the practice of scholarship is about thinking through to conclusion a series of investigative behaviors.
Centuries of publication practices in the print environment established short forms that made researchers more efficient. Abstracts, literature reviews, methodologies, conclusions and cited references broke out the segments that might need to be most frequently reviewed by scholars in their exploratory reading of the scholarly record as it appeared in journals. The book had its own conventional structural elements – front matter, table of contents, index etc. Those elements emerged as a means of standardizing presentation of the narrative. That standardization improved use of the scholar’s time in navigating lengthy texts and in determining relevancy and application to on-going work.
As the needs for efficient distribution of scholarship became more and more expensive, particularly over the course of recent decades, researchers and their libraries became adept at breaking apart the physical artifact into more immediately transferable content chunks. (Publishers for years muttered over the rise in inter-library loan distribution of more convenient content chunks — chapters, single articles, etc.) When the PDF arrived, it quickly became popular with many research communities because it mimicked print structures, but was valued as well for the protected convenience it provided for transferal of knowledge from researcher to researcher, sending email attachments. Even that form of transfer however was quickly and effectively replaced in some fields by widespread acceptance of the preprint server. (As a point of historical reference, the pioneering Los Alamos National Laboratory (LANL) preprint archive was initially launched in the early ‘90’s with responsibility for its on-going maintenance and preservation being transferred over to Cornell University in 1999. Subsequently, the repository was renamed arXiv and financial support broadened across multiple institutions as the value of the platform for STM fields was recognized.) But the arrival of the digital era solidified the recognition by researchers that transferring PDF files back and forth was insufficient. The static form couldn’t serve the communities’ needs, because the requirements of dissemination trumped the more immediate needs for re-use and manipulability. The discussion at conferences was lively
Hearing community complaints, publishers moved to adapt. Depending upon their particular field, researchers quickly saw an emerging series of prototypes for publication outputs that matched the functionality of the print.
As recently as 2013, the National Information Standards Organization (NISO) and the National Federation of Advanced Information Services (NFAIS) published their Recommended Practices for Online Supplemental Journal Article Materials. Publishers were taking what had been deemed ancillary work product and attempting to make it more readily available for examination and re-use. That ancillary material included (but was not limited to) such output as data sets, figures, movies, images, audio, code, software, etc. Again, feedback from various disciplines and communities made it clear that the emphasis of these efforts was in the wrong place. Ancillary or supplementary materials were actually much more central to the workflow of on-going scholarship than the final narrative text.
Again, publishers listened. It’s worth noting that the technology trends discussed during the Spring 2015 STM Association meeting (and documented in this Scholarly Kitchen post) noted as the most significant trend the need to view data as a first class research object, key to ensuring the ongoing reproducibility and reusability of scientific research and scholarship.
In 2016, we are seeing initiatives like ResearchObject.org, an effort that aims (in its own words) to “map the landscape of initiatives and activity in the development of Research Objects, an emerging approach to the publication, and exchange of scholarly information on the Web.”
Let me return to those initial examples provided of emerging forms of output. Based on even the most cursory exploration of the supplied links and recognizing that narrative form is clearly dominant, it is clear that the requirements behind publication – the effective and efficient display and explanation of investigative research findings – are being re-thought by the researchers themselves. Output must be re-thought, re-envisioned, in order to best satisfy the needs of those working in any given discipline.
Recent presentations at publishing workshops and conferences have made the point that content providers are aware that it’s not worthwhile to preserve digital output in isolation. The context of that output – the particular operating system, the software version, even the hardware – must be preserved as well if a scholar’s data (and I use that word in its broadest possible meaning) is to be properly understood. Again, the OCLC Research Division has already been thinking about this, working with the University of Michigan to establish a context-based approach to data curation.
Listening to the various voices of stakeholders in this niche community of publishers and libraries, it becomes clear that we won’t get to any quick or easy answers. Some next steps are fairly obvious. Standards are useful in building interoperable systems across institutions and geographically scattered research communities. Publishers are (as stated earlier) trying to build the next generation of information products and services.
But how does this play out? I am sure that my colleagues here in the Scholarly Kitchen are aware of the ground movement below their feet as well. My conversations with OCLC Research colleagues, Constance Malpas and Brian Lavoie, have given me a good deal to think about in considering the forms of publication that current inventors – researchers, libraries and content providers – are designing, tinkering with and banging on. (Construction areas are never entirely quiet.) There is awareness when it comes to certain obvious areas; research data is just one area of innovation. Others will emerge.
But in those discussions with Constance and Brian, still more questions have occurred to me and to them. What of the potential for fragmentation of the scholarly record if output from related fields diverges in some way? What issues of operating at scale still face content providers (and libraries are increasingly themselves in that class when they assume responsibility for university presses and publication of traditional forms like the monograph)? There’s a huge interest in collaboration between stakeholders in order to alleviate potential strains on the system, but is that interest only for those working in some disciplines or in certain types of institutions? Are there areas where knowledge is at risk because scholarship by definition resides in the long and narrow tail?
Most importantly, what outputs will emerge that display and illuminate most successfully the findings from on-going research? Which forms will further engage students and scholars, driving them in turn to create new knowledge? Because that’s why we’re here as a community. That’s the point of scholarly communication.

Discussion
6 Thoughts on "Watching and Documenting An Evolving Scholarly Record"
This excellent post raises questions about who will take responsibility for developing and sustaining the various parts of the scholarly enterprise broadly construed, as here? The more upstream the process of documenting and preserving the entire scholarly process of knowledge production goes, the more uncertain it becomes what entity should be in charge of what. Libraries, publishers, societies, computer support services have all come to play certain reasonably well-defined roles over time, but the scenario depicted in this post casts all these roles into question as libraries morph into publishers, publishers become service providers rather than content providers, etc. I have witnessed the evolution of one player in the system at close hand as a member of the board of the CCC, which began as a licensor of photocopying but has now evolved into a far more complex organization providing multiple services across a range of needs, as with its new text and data-mining initiative. With so much change under way, the times are exciting for any of the players, but also very challenging as everyone tries to figure out what new roles will become one’s responsibilities in the future. I have to say I’m glad I’m retired so that I can watch all this drama from the sidelines without having to worry about what my own job will look like and where my pay check will be coming from in the future.
This is an excellent review of the continuum of scholarly output. I am very excited about the possibilities of connecting outputs. What I mean is to provide a reader of a journal article with pointers to all related outputs. Seeing the evolution of an idea through experiment and well into practice is, to me, the future of scholarly communication. This was discussed at length with the OSI workgroup on peer review. Here comes the catch…what level of peer review should there be at the different stages of output dissemination? Some peer review is already built in and can be formal (proposals, grant applications, publication review, etc.). Other stages will certainly see less formal review (an early figure shared on FigShare, a conference presentation, discussing different outputs with colleagues). Then we have something in the middle–preprints.
While this outputs continuum is gaining momentum, we can’t forget what levels of peer review are expected and at what stages. This is not for me to decide. It’s up to the communities affected to determine what is acceptable but it is part of the process.
SHARE is working toward collecting and connecting these things, which they call “research events,” to help universities know what their researchers are doing. Their collection system — Notify — is well underway and they are starting work on the connection system. See http://www.share-research.org/. I track their evolution which is now quite promising.
Researchers as well should want their progress to be visible. This is a grand challenge. Even just making Awards–>Conferences–>Journals visible would be a big step forward. The science mapping community should get involved here. The paths may be complex, as ideas often both converge and diverge.
Sandy, I too am now in the soft chair and am glad my plate is not too full. As one looks across the sprectrum of just what is being done and who is doing it and for whom I tend to look back as a young college book rep who upon a visit to NY mentioned to the publisher of the college division that we need to publish solution’s manuals for our math books. He replied: What! They are college professors, they have PhDs and they should know how to solve the problems!
But, your question is a good one. Just who will inherit these interesting and worthwhile publishing endeavors and maintain them.
As I look at What Jane Saw I wonder at what point a curator will say: You need permission and this is the cost!
When the PDF arrived, it quickly became popular with many research communities because it mimicked print structures, but was valued as well for the protected convenience it provided for transferal of knowledge from researcher to researcher, sending email attachments. Even that form of transfer however was quickly and effectively replaced in some fields by widespread acceptance of the preprint server.
If one is going to bring up the arXiv, PDF was really a minor player; if I recall correctly, it was seen by many as an irritating, binary substitute for PostScript (and yes, I still have a Color NeXTstation; it used Display PostScript rather than Display PDF, which eventually was adopted for OS X). PDF was even less transferrable, because true PS (and the actual coin of the arXiv realm, LaTeX), being text based, can be heavily compressed for E-mail purposes.
PDF was mainly driven by Microsoft dominance, as far as my memory goes, the point having been to offload the RIP to the computer, but most consumer-grade printers nowadays are actually PostScript based all the same. The timeline described is simply off; the LANL archive preceded PDF. (Some 1995 comments from Paul Ginsparg can be found here.)
* I’m also not sure how PDF “mimic[s] print structures,” as all of my prepress software feeds directly to different PDF standards.
I have not seen such a comprehensive identification of the ways technology is changing our global epistemology. It reminds me of the excitement I felt when, fifty years ago, I learned about bibliographies of bibliographies. And even earlier when Teilhard theorized about something mysteriously named the ‘noosphere’ I personally experienced its glory when, in retirement and wanting to weave the various threads of a very interesting career into something tangible, I began studying the origins of writing. Academia.edu and the Ancient World Online are an absolute goldmine of ongoing research and discovery.



