Editor’s Note: Today’s post is by Stuart Leitch. Stuart is the Chief Technology Officer at Silverchair.
Artificial intelligence and large language models have the potential to change, even disrupt, every aspect of scholarly publishing, from how infrastructure and platforms are developed to how content is discovered, used, and licensed. This post is based on the opening keynote from Silverchair’s Platform Strategies 2023, “AI in Scholarly Publishing,” and offers a conceptual overview of the technologies, and a view of how our industry fits in.
Smart people disagree about generative AI. Some people see this as the latest the latest fad with a peak of inflated expectations in the hype cycle. Others see something far more profound coming. Likewise, there are a range of views on how good or bad AI will be for humanity.
In my view, we’re experiencing an unprecedented era where AI has transitioned from highly specialized models with complex architectures operating in narrow domains, to general models with simple architectures with very broad domain applicability. AI models have outgrown mere classification and pattern recognition and are now creative.
What’s important to understand is that Large Language Models powering generative AI are fundamentally different from traditional software. Andrej Karpathy, the former head of AI at Tesla and a co-founder of OpenAI, differentiates between Software 1.0 and 2.0. Software 1.0 involves languages like JavaScript, C#, and Java, which humans can understand and control. We can debug and comprehend this software deeply.
On the contrary, Software 2.0, written in abstract languages like neural network weights, is less friendly to humans. This software doesn’t involve human-written code due to its impractically high number of weights (tens to hundreds of billions of numbers in a matrix). Instead, we set goals on desired behavior and give it computational resources to learn towards these goals. We can’t debug the output, and we have very little detailed understanding of how it works. It’s a whole new paradigm in software development that is rapidly escaping beyond narrow, bounded contexts into the broad.
In other words, we don’t “program” Software 2.0 as we do 1.0. Rather, we “train” it. In 1.0, we explicitly write software, algorithm by algorithm into features and components. The properties and capabilities of the system are exactly those we have “programmed” in. In 2.0, we provide the data and compute, and the model learns on its own, building its own internal structures in ways we don’t yet really understand. The properties and capabilities of 2.0 systems are emergent, much like how properties emerge in complex systems in nature.
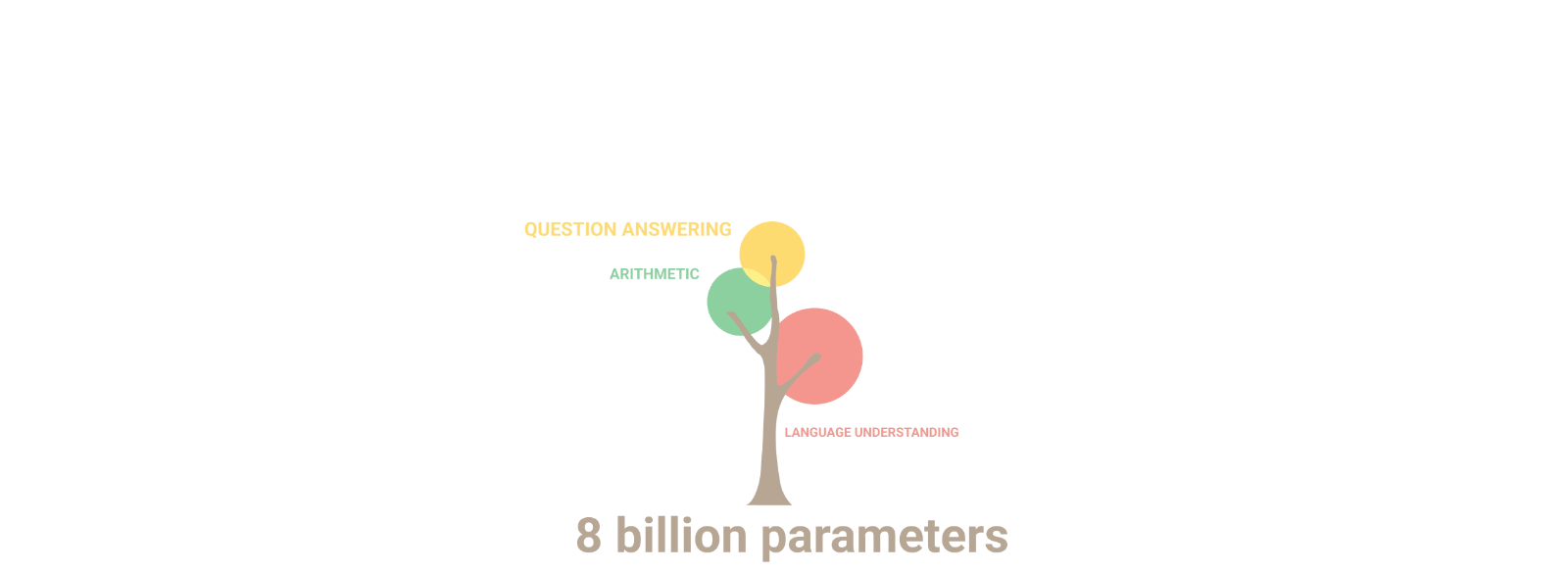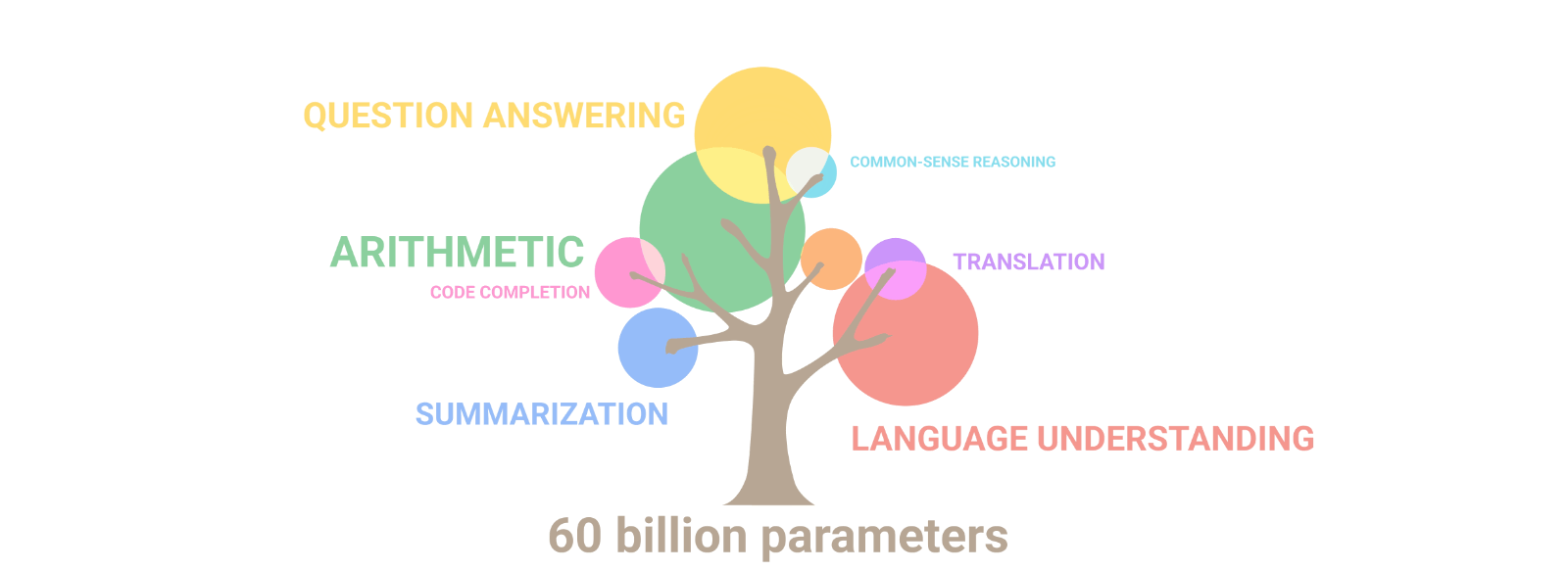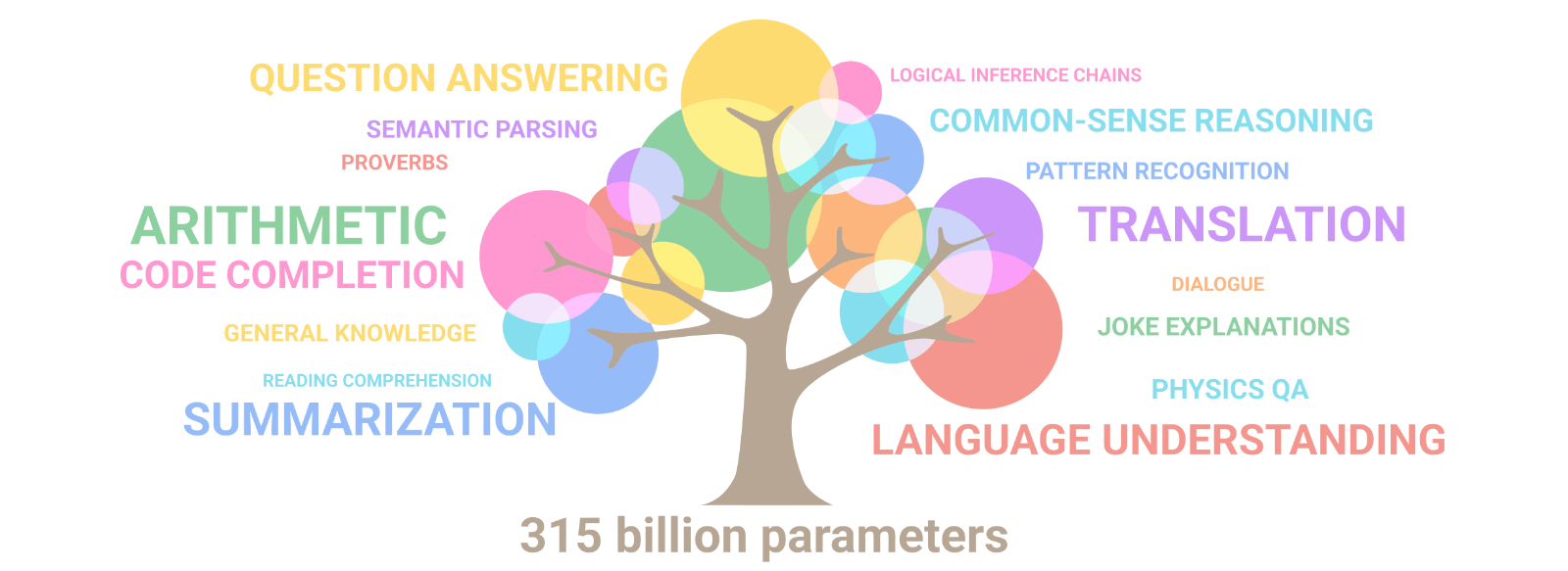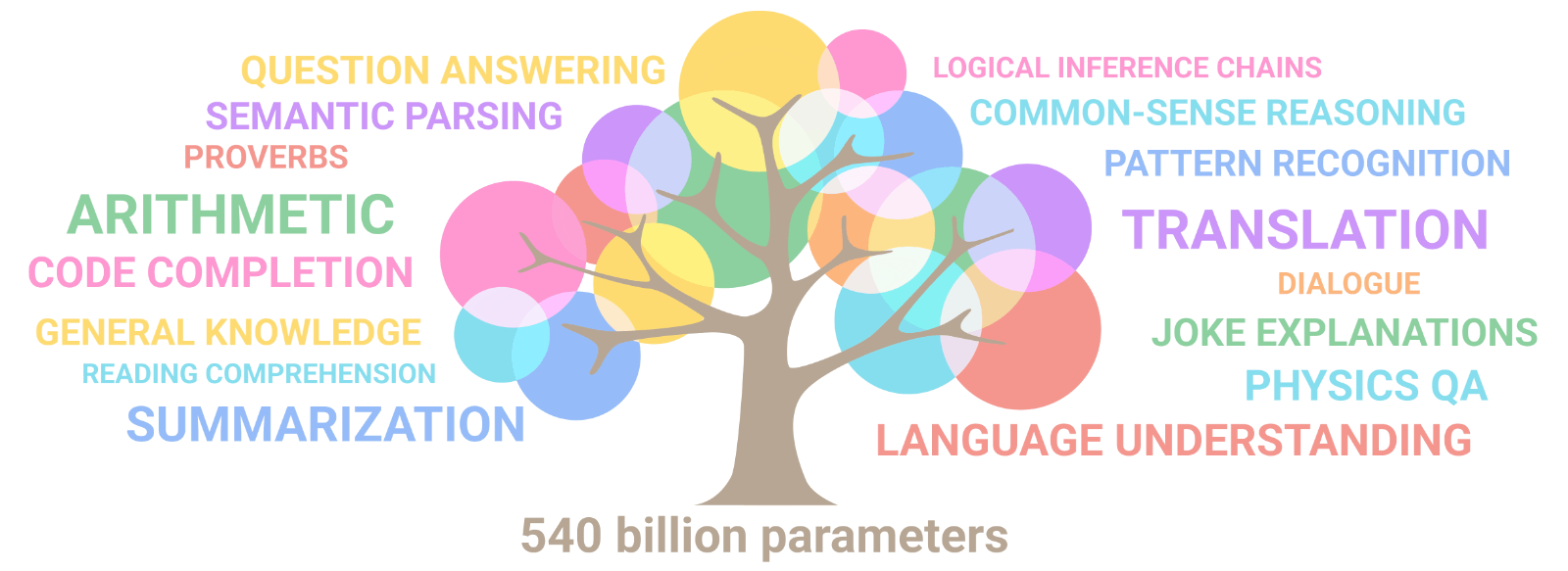
Google Research’s illustration above shows how capabilities have progressively emerged as the parameter count of the LLM increases. With each new order of magnitude, new capabilities surface. Our ability to engineer such systems radically outstrips our abilities to understand them. As models scale, they acquire new skills unevenly but predictably, even though these observed scaling laws remain somewhat mysterious.
As leading AI players build some of the world’s largest supercomputers, we’re about to find out what capabilities emerge next as billions of dollars are rushed to the top companies in the arms race to AGI.

The vast majority of pundits agree that these systems are going to be extremely intelligent. But there’s a difference between intelligence and wisdom. What’s of concern is whether these systems will be wise. That’s going to in part heavily depend on the training data we feed them.
We’ve seen Reddit, Twitter/X, and 4Chan become the poster children for humanity’s most reactive thought processes, dominated by hot-takes and flared emotions. The premium will be on the more deliberative, disciplined System 2 style thinking for which academia is society’s primary institution, with publishers as the gatekeepers.
Academia has developed an amazing tree of knowledge which is arguably the most important data for Large Language Models to be trained on. The frontier foundation models are widely assumed to have been trained on a wide variety of paywalled content. There are ferocious legal efforts underway to get this content out of the training sets.
The provocation I put forward is what happens when we have models growing ferociously in capability, but we decline to train them of the very best sources of human wisdom and instead have them learn on the longer tail of less rigorously curated information, or information that is out of date. What does that do to the risk that these technologies are needlessly rough on humanity? If we succeed in getting the LLMs unhooked from the best sources of information right as they are set to have whole new sets of capabilities emerge and are being integrated into everything, how might that play out? Do we want the tech oligopoly turning to simulations to generate the training data?
If we treat this as a gifted child that may take over the world, we owe it to humanity to give it the best education possible and to ground it in the best of human wisdom. It for sure knows about Nietzsche, Machiavelli, Sun Tzu, and Clausewitz.
My provocative thought is that rather than trying to get premium scholarly information out of LLM training sets, we should fight to get it in there, on terms that are economically sustainable.
There is far more at stake than just preserving our business models. This is the time to look deeply into our missions underlying our organizations and consider what role we may play in nudging the outcomes. This transition is simultaneously fraught with existential risk and holds the promise to solve many of humanity’s greatest challenges. Food for thought.
View the full recording of this keynote here.
Discussion
7 Thoughts on "Guest Post — Food for Thought: What Are We Feeding LLMs, and How Will this Impact Humanity?"
Who gets to decide what the “very best sources of human wisdom” are?
We can’t even agree on basic facts of reality, from who won the 2020 US Presidential Election to whether blowing yourself up to kill infidels will earn you a fast-track to heaven.
Give up on the idea of wisdom. There are plenty of other bigger concerns about this technology that people like Max Tegmark are raising and need to be heeded.
I agree the degree of polarization and politicization in human belief systems is disturbing, particularly when anchored in theories that have little rigorous evidence or reason behind them. That’s where the scientific method and academia in general, as flawed as the institution is, remains a bastion of evidenced based reasoning that is self-correcting over time. The best of that reasoning is presumably highly correlated with journal prestige and I think that’s a decent proxy for wisdom in this context. I agree with Greg Fagan that giving up on wisdom is throwing in the towel on civilization and not something I advocate.
I agree strongly with many of Max Tegmark’s perspectives. While they need to be taken very seriously at a global level, they are less proximate to our industry. I focused in this article on pushing the best scholarly content into LLM training rather than withholding it because it is something local to our industry and something that readers of this blog are likely to be involved with.
This is a thoughtful and incisive post, and I agree with your conclusion that we should be training LLMs with the very best scholarly information available. Surely even we lowly humans are capable of discerning the best sources of wisdom from the worst. Give up on wisdom? We might as well throw in the towel on civilization now and be done with it.
Thanks for the comments. I agree this is not the time to give up.
It is by no means a child. I think we can conclude that:
a) It is a machine that compares the nature of the ask with the nature of what it has been allowed to observe but it ‘understands’ neither. It just creates order in the objects (e.g. two piles of Lego blocks) and then presents a structure in its response that matches what it has observed the most. It has no clue whether it is right about anything or not.
b) Several flaws in the machine will be unfixable, perhaps even because the machine has no inherent intelligence, let alone consciousness. These flaws, which can cause significant problems, warrant caution.
c) Your suggestion becomes more relevant when AGI has been achieved. According to Microsoft that won’t happen anytime soon. According to Nvidia it might take 5-6 years. According to the Wikipedia owner it could take 50 years.
So for now we might want to focus on what the machine is capable of doing (wrong) with all this beautiful and pristine knowledge and research https://news.osu.edu/chatgpt-often-wont-defend-its-answers–even-when-it-is-right/ Quote: “As part of the experiments, the team also measured how confident ChatGPT was in its answers to the questions posed. Results revealed that even when ChatGPT was confident, its failure rate still remained high, suggesting that such behavior is systemic and can’t be explained away through uncertainty alone.
That means these systems have a fundamental problem, said Xiang Yue, co-author of the study and a recent PhD graduate in computer science and engineering at Ohio State. “Despite being trained on massive amounts of data, we show that it still has a very limited understanding of truth,” he said. “It looks very coherent and fluent in text, but if you check the factuality, they’re often wrong.”
Yet while some may chalk up an AI that can be deceived to nothing more than a harmless party trick, a machine that continuously coughs up misleading responses can be dangerous to rely on, said Yue. To date, AI has already been used to assess crime and risk in the criminal justice system and has even provided medical analysis and diagnoses in the health care field.
In the future, with how widespread AI will likely be, models that can’t maintain their beliefs when confronted with opposing views could put people in actual jeopardy, said Yue. “Our motivation is to find out whether these kinds of AI systems are really safe for human beings,” he said. “In the long run, if we can improve the safety of the AI system, that will benefit us a lot.””
Thanks for the thoughtful engagement.
While AI is not a child in the literal sense and I don’t mean to anthropomorphize, the point is to consider the youngness of these models and the impressionable stage they are now in given their power and about to be wide deployment.
I agree that LLMs don’t “understand” the world through genuine comprehension in a human or sentient sense. It’s also the case that in certain areas like language translation or coherent language manipulation in general, the results of the frontier models are so strong that while LLMs arguably do not have the same symbolic understanding of language that humans do, it is undeniable that they have some very strong form of functional understanding.
Regarding LLMs having no clue as to whether they are right or not, I don’t think this is completely accurate. They are heavily biased towards usefulness over accuracy and are overconfident, but you can ask them to reflect on their confidence and they do have some notion. LLMs become much better at evaluation of truthfulness when you get them to reflect in another session in an evaluation role. That is the basis of Tree of Thought patterns and how Google was able to get such good scores with AlphaCode 2 in competitive programming competitions by generating multiple possible solutions and reflecting on them as an evaluating critic.
Regarding the article you shared on ChatGPT not defending its answers, the out of the box conditining is to be deferential. Stiffen its spine though a strong system message and it will stand its ground in areas where it has higher confidence. LLMs are notoriously weak at math, common sense and logic, so it’s going to be squishier there unless using code interpreter.
I do agree in general however that LLMs are not well grounded in truth and can be dangerous to rely on. They are also becoming increasingly useful and the accuracy vs. usefulness tension needs to be evaluated in context. School children are demonstrating they are far more comfortable relying on ChatGPT than their teachers are, illustrating there will often be somewhat divergent perspectives. These models are going to get widespread usage long before they become firmly grounded in factuality. That’s why I make the case for getting the best training data into the models.
You’re very welcome and thank you for the thoughtful response. My prediction is that we will come to the conclusion that solid performance by chatbots is a lot less related to the quality of the training data than one might expect and that it is much more influenced by lack of true intelligence, human intervention (rating, moderation and programmed guardrails and filters) and the fact that AI makers have made the bots non-confrontational, non-controversial and will make sure that they will avoid liability and self-incrimination. This has already resulted in situations wherein the chatbots convincingly ‘lie’ without telling the user that they did, in order to align themselves with guardrails. The young early adopters may not be able to recognize that. Mind you, older scientific researchers did not even realize at first that the bot had created a fake but convincing scientific database. A probabilistic and non-deterministic approach will not suffice and true intelligence, understanding and perhaps even consciousness will be required. It is why a chatbot might choose for ‘peace’ with minimal acts of crime and loss of life forced on the population by authoritarian regimes rather than a totally free society with loss of lives or violence as a ‘byproduct’. Perhaps ‘irrational’ but idealistic and emotional decisions are the most difficult to understand for Dr. Spock in a ‘black box’.



