Large Language Models (LLMs) are the powerhouse behind today’s most prevalent AI applications. However, a deeper dive is necessary to grasp their varied roles in scholarly publishing.
There are two primary LLM branches: generative AI (like OpenAI’s GPTs and models from Anthropic, Google, and Facebook) known for crafting text, and the less-heralded interpretive AI (exemplified by BERT—Bidirectional Encoder Representations from Transformers) designed to understand text.

ChatGPT has popularized generative AI, sparking immense interest. BERT has quietly remained in the shadows. Interpretive AI offers profound insights into content and audience engagement, a critical tool for publishers aiming to harness the full potential of AI.
This article aims to shed light on interpretive AI – its significance as a standalone technology, and its role in complementing and enhancing our understanding and application of generative AI. To start, let’s explore why generative AI alone isn’t the solution to every problem.
Understanding Current Limits of Generative AI
Limitation #1: LLMs Have a Narrow Short-Term Memory
One of the primary limitations of Large Language Models (LLMs) lies in their “context window” — essentially, their working memory. Unlike human memory, which is flexible and expansive, LLMs rely on a fixed number of “tokens” (averaging 1.3 tokens per word) to process information.
Consider using GPT-4-Turbo’s full capacity: a 128k-token window translates to roughly 100k words, or about 20 average-length journal articles. This may seem substantial, but it’s tiny compared to the millions or billions of tokens in a publisher’s entire corpus. Tasks like searching a full content set, conducting meta-analyses, identifying research gaps, or comparing books become impossible with a standalone GPT model, even with the latest technology.
Limitations #2, #3, and 4: Slow Speed, High Cost, Low Rate Limits
Larger generative models offer more capabilities but come with increased costs and slower processing speeds. GPT-4, currently the most advanced public LLM, can be likened to a highly intelligent yet resource-intensive colleague.
Let’s consider a practical scenario: a large society publisher with 1 million pieces of content, each requiring lay summaries or research highlights. If we assume an average input of 4,000 words per article into GPT-4 (equivalent to 5,200 tokens) and a 100-word summary output, the cost and time required for such a project are daunting.
Using GPT-4-Turbo, this task would demand around $55,900 and approximately six months. The full version of GPT-4 would increase the cost to $327,600, with an unclear completion timeline.
Why so expensive and time-consuming? Processing capacity and spending limits.
Processing capacity: even with OpenAI’s top-tier account, the maximum processing rate is 300k tokens/minute. At full capacity, this translates to about 55 articles per minute, theoretically completing the task in 12.5 days. However, achieving this theoretical capacity is unlikely (the real world is messy and APIs time out).
Spending limits are the biggest issue. With OpenAI’s highest public tier, spending is capped at $10k/month due to capacity limitations and overwhelming demand, making large-scale projects like this a significant challenge.
Interpretive AI: BERTs for Understanding and Text Embeddings
BERTs, like GPTs, undergo extensive pre-training on vast text corpuses. This ‘schooling’ phase involves predicting hidden words within sentences by reading the sentence in both directions (hence, bi-directional). This is very similar to solving trillions of fill-in-the-blank puzzles. By learning to solve these puzzles, the models build up a deep understanding of language and knowledge of how the world works.
BERTs function by generating “text embeddings” from input content. These embeddings are high-dimensional numeric representations capturing the essence of text — everything from the main point made by the author to tone, format, and style. These text embeddings, represented with 768 or more dimensions, form a rich landscape for encoding human writing.
They are especially useful when comparing one text with many others – for example, comparing a new paper submission to existing published papers to find corroborating research or missing citations.
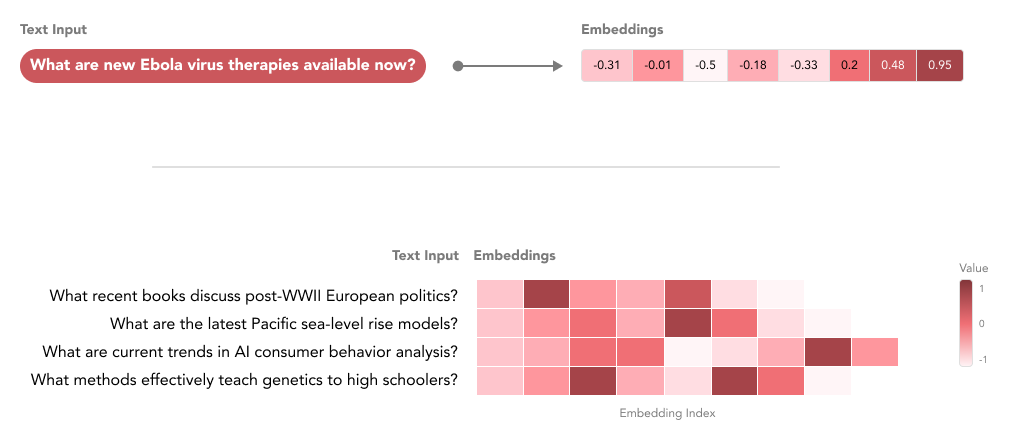
Applications include:
- Semantic Search: Locating content matching a search query’s meaning.
- Similar Content Finder: Identifying content closest in the embeddings space, useful for suggestions.
- Journal Recommender: Matching journal or article ‘fingerprints’ to research ideas or abstracts.
Interpretive AI: Funneling People in the Embeddings Space
A frontier application of embeddings is representing people in the embeddings space. It works on the principle of “you are what you eat.” With the proper systems in place to capture behavioral data (e.g., a Customer Data Platform), you can observe how people travel within the same embedding space as the content they’re consuming. Just as text embeddings allow you to connect the content from a proposal to existing content within your journal, you can take the description of a new special topic section and find people whose content consumption suggests they’d be interested in reading or even submitting to it.
Applications include:
- People Search: Identifying people matching descriptions from products, papers, or events.
- Predictive Interests: Anticipating an individual’s future actions or interests based on audience trends.
- Content Recommendations: Suggesting future content based on past consumption.
- Personalization: Driving site search, ads, etc. with a deep understanding of which historical content consumption that leads to engagement.
- Live Adaptation: developing models and web features that adapt as new content is added to your corpus – without expensive retraining.
Interpretive & Generative AI: Bringing BERTs and GPTs Together for Conversational Search
Let’s consider a practical example of using BERTs and GPTs together: Imagine you wanted to build “Conversational Search” for your publishing site. Something like the offerings found from Scite, Consensus, Digital Science, and Scopus.
You need to rely both on the breadth of BERTs to understand your full content corpus (and get around GPTs’ context window limitations), and on the creativity of GPTs to generate an informed response. Here’s the approach:
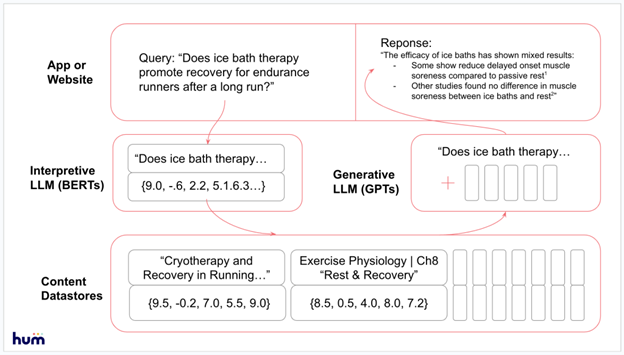
Interpretive Layer:
First, you’ll need to translate your content corpus into embeddings format. At Hum we use Lodestone, an open-source embeddings model we created that is optimized for long sequences. You can also use OpenAI’s ada embeddings, Allen Institute’s SciBERT, or many others.
Next, you’ll translate the user query into embeddings format — the query is a phrase or sentence that can be matched to other phrases, sentences, paragraphs, and documents within your corpus.
The best matching chunks will then be fed into the generative LLM, along with the original prompt.
Generative Layer:
For this to work, you’ll pass three things to the LLM:
- The initial user query — e.g. “Does ice bath therapy promote recovery for endurance runners after a long run?”
- The retrieved chunks of context (reference points to use in addition to the LLM’s own training data)
- An explanation of what the chunks are and how to use them.
What you’re then able to output is a response that’s grounded by your content corpus, potentially enhanced with citations from individual pieces of content.
Here’s an example output using the example query above using Perplexity.AI, which uses either Claude2 or GPT-4 (which was used here) as its generative LLM under the hood and has internet access (it will pull chunks from various internet sources).

Overview
Ice baths, also known as cold water immersion or cryotherapy, involve submerging the body in cold water for short periods of time, usually 5-15 minutes. This practice has become popular among endurance athletes like runners as a recovery modality after intense training sessions.
The proposed benefits of ice baths for runners include:
- Reducing inflammation and muscle soreness12
- Flushing out metabolic waste products like lactic acid1
- Constricting blood vessels and decreasing swelling3
- Increasing blood flow and delivering nutrients upon rewarming4
- Improving perceptions of recovery and reducing fatigue2
However, research on the efficacy of ice baths has shown mixed results:
- Some studies show ice baths reduce delayed onset muscle soreness compared to passive rest2
- Other studies found no difference in muscle soreness between ice baths and rest5
- A few studies suggest ice baths may hinder muscle growth and strength gains67
Overall, the evidence on ice bath benefits is inconclusive but many runners still use them believing they facilitate recovery. More high-quality research is needed.
When To Use Ice Baths
Experts recommend ice baths on harder training days when muscle soreness tends to be higher: 8
- After long runs
- High-intensity interval sessions
- Tempo/threshold runs
- Races
Ice baths are likely less useful on easier training days.
How To Take An Ice Bath
- Fill tub with cold water and ice, 50-59°F (10-15°C) 9
- Immerse body up to neck for 5-15 minutes max8
- Some alternate with hot water (contrast water therapy) 10
Safety Considerations
Consult a doctor before ice baths if you have: 11
- Heart disease – cold stress on the heart
- Circulation issues – potential for frostbite
- Diabetes – skin sensitivity and nerve damage
- High or low blood pressure
Do not exceed 15 minutes to avoid hypothermia.
Conclusion
- Evidence for ice bath benefits is mixed but many runners believe it aids recovery
- Best used after intense sessions when soreness is high
- Take safety precautions and consult a doctor if you have certain conditions
- Limit time in ice baths to 5-15 minutes
- More research is still needed on ideal protocols
References
1 Ferreira-Junior et al. Front Physiol. 2014.
2 Bleakley et al. Cochrane Database Syst Rev. 2012.
3 Costello et al. Int J Sports Med. 2014.
4 Gregson et al. Am J Sports Med. 2011.
5 Sellwood et al. Br J Sports Med. 2007.
6 Roberts et al. J Physiol. 2015.
7 Yamane et al. J Appl Physiol. 2006.
8 Wilson, 2022.
9 Hame, 2022.
10 Fonseca et al. PLOS One. 2013.
11 Kelly, 2021
Where Publishers Go From Here
If you want to seriously start experimenting with AI or building AI products, you need your content in AI-native (embeddings) format.
Embeddings are essential to build products that rely entirely on interpretive AI (e.g., article and journal recommenders) but also to unlock the true potential of generative AI (question answering, conversational search, summaries for multiple audiences, content gap identification, and so on). On the horizon is faster and cheaper access to key capabilities like summarization, evaluation, and insight extraction. This will help publishers infuse AI throughout their products (end-user experience), internal operations, and the peer review process.
Some publishers will have the engineering talent internally to manage this new, AI-native infrastructure. Others will turn to AI partners and vendors. Just like the shift from print to digital brought a new wave of tech providers servicing scholarly publishing, so will the shift to data and AI.
Discussion
2 Thoughts on "Guest Post — Beyond Generative AI: The Indispensable Role of BERT in Scholarly Publishing"
Dustin, thanks for this article. Whilst in 2023 the large focus from publishers (and other industries has been on Generative AI), your definition of Interpretive or transactional AI, along with Workplace AI (referring to use of AI or machine learning to support employees & managers) 2024 is shaping up to be a “yeAIr” 🙂 of innovation.
My first response to anyone asking about AI is “which kind?”
The use of Bert the Muppet in the DALL-E generated image above strikes me as the very thing that is wrong with the use of AI in the wild. I don’t see any reference to permission to use a copyrighted/trademarked character… granted I am no lawyer, but my hunch is that this is a no-no.