Editor’s note: Today’s post is by Michelle Urberg and Chris Bendall. Michelle is Head of Data at LibLynx, a provider of identity, access, and analytics services. Chris is a strategy and corporate development leader at Research Solutions, Inc., the provider of Article Galaxy, Scite.ai, and more. Reviewer credit to Chefs Avi Staiman and Todd Carpenter.
Did you know that widely used metrics only measure first-party usage (the publisher platform) and only the usage generated by humans? This excludes a rapidly growing body of content usage generated by AI (artificial intelligence) tools, both first‑party AI tools embedded in publisher platforms (e.g., Wiley) and especially by third-party agentic platforms (e.g., Claude, ChatGPT).
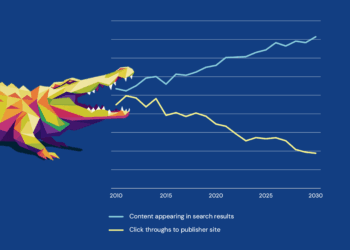
That means, there’s an elephant-sized gap in most usage reports.

Third-Party Agentic Usage is the Direction of Travel
We are all feeling the ground shift underneath our feet in libraries and publishing. We don’t yet know the full extent of how agentic tools will change our industry. But we do know OpenAI’s “low-key research project” (aka, ChatGPT) has fundamentally uprooted research and teaching practices. Since 2023, this has been widely discussed, including in an Inside Higher Ed Op Ed and many subsequent opinion pieces.
Third-party agentic tools like ChatGPT, Claude, Gemini, and Perplexity, as well as scholarly content-specific tools like Consensus, Elicit, Scite, and others, can quickly fetch, sort, and organize information that would otherwise take humans weeks or months to collate. In some cases, this means users bypass traditional abstract databases, library catalogs, and full-text content platforms. AI outputs, including summaries, snippets, and citations, are deemed “good enough” — so much so that users are increasingly satisfied with the AI output and do not seek out a publisher platform for the full-text content.
The result is a dramatic drop in referrer traffic to full-text platforms and a dramatic rise in the “zero-click search,” leading to the “zero-click result.” A zero-click search happens when a user gets what they need from an AI-generated output and does not need to visit a content platform for more information. A zero-click result is the content of that search, which could include a full-text snippet, an abstract, or other bibliographic information about a resource.
Unsurprisingly, then, academic publishers are alternately panicking or fighting against the “zero-click search” and “zero-click result,” as well as their impacts on usage reporting (zero usage logged). Zero usage leaves both publishers and librarians in the dark about what content is valuable to their customers and patrons. In teaching and research contexts, this means that it is that much harder to make data-driven purchasing decisions and therefore harder to decide what books, journals, and other content to buy. This is a publisher’s worst nightmare and a librarian’s headache.
But there is good news! Usage has not vanished! Rather, it has been displaced. It has been rerouted to agentic platforms and transformed into different kinds of searches and content engagement. Wiley, Scite (full disclosure, one author of this post is associated with Scite), and Cashmere (as an infrastructure and rights-management provider rather than a discovery platform) have developed infrastructure to address such “zero-click searches” and the associated loss of usage metrics. In each case, they are leveraging API endpoints and especially the Model Context Protocol (MCP), developed by Anthropic in 2024, which rapidly emerged as an open standard for enabling agentic AI tools to interact with third-party tools, content repositories, and datasets in a structured, replicable, and auditable manner.
The “chunked” and indexed content is retrieved and assessed, via MCP, by the AI tool to determine its relevance for a query. How content is chunked can differ; for instance, Scite focuses on citations and their context, while Cashmere is oriented around concepts and their context. In addition, the business models for the services are rapidly evolving in relation to both publishers and customers, and we can expect different approaches to appear and be tested in the next few months.
These “chunks” of content are the future of usage tracking. Steve Smith argues that as AI shifts discovery from documents to answers, usage measurement (including COUNTER) will need to evolve beyond PDF downloads toward tracking machine-consumable “knowledge objects” with explicit context and provenance as the new unit of scholarly use. This is the moment to be proactive about managing this change. Our task now is to find where that usage has gone and reclaim it, so that libraries and publishers can continue to demonstrate value to patrons and customers. Collaboration with service providers developing agentic tools is the key, as they are now intermediaries between users and the libraries and publishers who provide them with content.
The Basics: How Do AI Tools Interact with Scholarly Content?
When a user queries an agentic AI tool (described also here Discovery #1: How AI agents transform researcher inputs), which is leveraging a source of indexed scholarly content or citations (either via API or MCP), it typically expands the query into several additional search strategies to ensure it finds the most relevant sources. The LLM then refines the number of sources by relevance to the human query and its expanded search strategies and provides a summary for the user.
Two key usage points come out of the generative AI search strategies:
- AI Reads: Automated AI search related usage driven by the AI as it acts upon the expanded search strategies it has defined as a result of a single human query.
- AI Citations: The refined list of sources upon which the summaries are based, ideally with links back to the Version of Record or other source document.
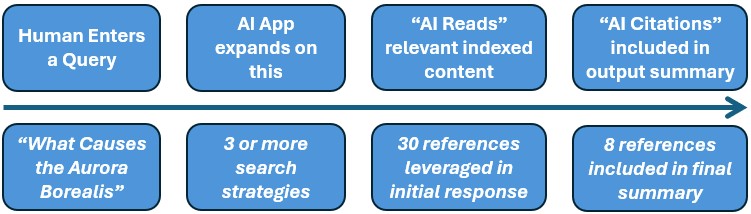
While generative and agentic AI searches are important for understanding the use of a given tool, the publications consulted (through abstracts and bibliographic information), and summaries of the cited sources are the content engagement points that libraries and publishers need most for tracking usage. As more publishers are indexed by platforms and initiatives, like Scite or Wiley’s Scholar Gateway, the more items can be counted and useful metrics generated.
The Challenge with Existing Metrics
In scholarly publishing, existing metrics for recording content usage are derived using the COUNTER Code of Practice, which presumes that the user is engaging directly with a first-party content platform (including library discovery services and content aggregators), not a third-party content provider or an agentic tool. COUNTER excels at defining content usage in first-party content providers by standardizing the types of user interactions, controlling vocabulary for naming content types, access types, and access methods. Because everyone uses the same metrics, usage can be compared across platforms. Without standard metrics and vocabularies, comparable usage is impossible to generate.
COUNTER has developed long-tested metrics, which are assigned to one of four types of interactions: searches, views of content info (investigations), views of full content (requests), and turnaways (denials). Imagine your own engagement with finding electronic books, journals, or media. You likely begin with a search, follow with clicks on desired items, and then conclude by playing a video or reading the full text (assuming you have access and aren’t turned away). This pattern — search, discovery, view — is repeated over and over again as users engage directly with a platform and its content.
So, What About COUNTER and Third-party Agentic Usage?
Usage generated in third-party platforms like ChatGPT, Claude, Scite, and others is currently out of scope for COUNTER reporting because the standard presumes a user is engaging directly with a first-party content provider. Since AI tools are starting to provide the same basic experience for human users as traditional content and discovery platforms — namely, search, investigate, view/denial — why not extend COUNTER metrics to measure third-party agentic-generated usage?
As a first step, COUNTER is exploring the addition of a new access method to the Code of Practice to accommodate first-party agentic usage (usage generated by AI tools inside of a publisher platform). We think usage tracking must be extended even further to count usage generated by third-party agentic tools.
Let’s Help Usage Metrics Catch Up to Current Technology
We know that researchers are using AI tools for more and more pieces of the research life cycle and that they want tools to provide credible results. Reliable third-party agentic platforms are not a passing trend; they are the direction of travel. One of the ways to increase credibility for researchers and libraries is to develop standard, auditable metrics to track usage generated in these platforms.
In order to make steps toward a future with standardized third-party usage metrics, we recommend that publishers and libraries take the following steps toward a future with standardized third-party usage metrics:
- Track what we can: investigations, requests, and denials
The standard metadata collected for abstract and summary views (investigations), full-content views (the request), and denials (as defined in the Code of Practice) can immediately be used to measure agentic-generated usage. If the agentic tool is providing a citation or a full-text view of the content, these can be identified as an investigation or a request, respectively. If the agentic platform has full-text availability, but the user does not have licensed access, the denial should also be available for reporting.
- Define what constitutes a search generated by a human vs an agent
Tracking searches generated by agentic tools is hard. As AI-assisted search becomes more prevalent across library discovery services and in publisher-owned platforms, fewer and fewer searches will be characterized as what COUNTER calls “searches regular” or “searches platform” (i.e., searches generated by a human user). AI-assisted searches set up multiple queries for each question posed to an agentic tool. Should we only count those human queries and not the AI-assisted ones? Or should we count both?
- Accommodate knowledge objects by augmenting existing COUNTER metrics
The extraction of knowledge objects in the form of text chunks (snippets and/or individual pages) and agentic writing of summaries needs to be defined. COUNTER metrics can be extended to accommodate these usage points. Knowledge objects are a kind of full-text, but not the whole text. And a user could be presented with a portion of an article without seeing the full text or having access to it. These textual “sound bites” should be given some recognition, not unlike a quotation with citation in a paper. Publishers, at the very least, will want to get this usage counted to track how an agentic tool bolsters their content usage.
- Count AI content usage that is leveraged to generate AI output
AI-generated outputs, such as summaries, are ephemeral, typically lacking a standard and persistent identifier. However, the indexed references analysed by an AI tool in answer to an initial human query (“AI Reads”) and the subset subsequently included in a summary (“AI Citations”) can and should be measured. This represents the rapidly growing source of usage (and a measure of the value and impact of the content) currently missed by “zero-click searches.”
Conclusion
We do not have all of the solutions today, but we can see the direction of travel: agentic tools are not going away for libraries and publishing. The sooner we come together to figure out how to harness the elephant of third-party agentic usage, the better we will be able to demonstrate the value of content for both libraries and publishers.
Post-Script on COUNTER Metrics
As indicated above, third-party usage sits at the edge of COUNTER metrics at present. However, we would like to highlight a couple of exceptions. These mechanisms for tracking usage are less commonly used, but are part of an auditable standard.
- Usage generated by text and data mining (TDM) is one type of usage not generated by humans. TDM is a specific harvesting mechanism agreed upon by an organization and a library to download large amounts of content for research purposes. It requires setting up specific rules around harvesting data (see the COUNTER CoP Section 7.10).
- Distributed usage logging (DUL) is the other provision for tracking third-party usage, but it still relies on humans generating the usage and not agentic systems. This model has had little uptake in the industry, suggesting that we need to find another way to bring third-party usage into analytics reporting. For more on DUL see COUNTER CoP Section 6.3).


Discussion
15 Thoughts on "Guest Post — There’s an Elephant in the Room, but Not in Your Usage Reports"
Thanks for the shout out for COUNTER – we absolutely see the Code of Practice as a foundation, not the final answer to usage tracking. Our AI metrics working group has been plugging away at this challenge for a while, and we’ve currently got an open consultation about our first phase of work (first party AI usage). We’d love readers of this post to have their say on that! https://www.countermetrics.org/ai-consultation/
Third party usage is somewhat covered by our syndicated usage best practice guidelines, which supersede the old DUL system that, as you correctly identify, has had little uptake. However, the AI working group does plan to tackle the third-party puzzle once we’ve got the first-party work wrapped up.
I wholeheartedly support your arguments here. At risk of stating the obvious, the absence of non-syndicated off-publisher-platform engagement from usage metrics isn’t entirely new or unique to AI workflows, since OA and non OA content has been read in spaces away from publisher platforms for some time. I do think it’s a shame that DUL didn’t get more traction as it might have paved the way to solving some of these problems in an AI world, but it’s good to see the steps COUNTER is taking.
Apparently I can’t type my own name. Trying again!
This is an excellent articulation of the “missing usage” problem as agentic tools become a primary interface for discovery and decision-making. Thanks also for the shout-out and for the insightful framing of “AI Reads” and “AI Citations” as measurable touchpoints. The standards question is now unavoidable: do we extend existing usage frameworks for agentic activity, or do we need a parallel, privacy-preserving schema for chunk-level reads and object-level citations? Either way, the measurement gap you’re describing makes this increasingly urgent.
This is an excellent explanation and detailed review of the challenges publishers and database providers face with respect to usage. Should be read by all reliant on how counter stats interprete product utility and therefore value within the library market.
My take in thinking about other examples. https://personanondata.blogspot.com/2025/07/do-ai-tools-harken-death-of-academic.html?m=1
This is an important piece and an important moment.
One clarification that I think actually strengthens your case: in the opening paragraph, Wiley is cited as an example of “first‑party AI tools embedded in publisher platforms.” In practice, Wiley’s AI Gateway is an MCP connector that exposes content to third‑party agents (e.g., Claude). That makes it a live example of the third‑party agentic usage you describe later in the post, and of the kind of structured, controllable channel where AI Reads / AI Citations‑style metrics will emerge.
I’d also suggest explicitly naming the browser‑side pathway you gesture toward with “zero‑click search.” If MCP/API‑based integrations give us one family of agentic AI Reads, there’s a parallel class of browser‑mediated interactions where assistants generate synthesized answers from content loaded in the user’s browser. Those synthesized responses are still built from specific articles and full‑text views, and there is emerging work on treating them as a normalized usage path—what we might call mediated reads—so that they can be logged alongside traditional reading/downloading events rather than disappearing into a black box.
The risk, of course, is that if agents don’t get robust gateway/API/MCP paths, they will simply fall back to the browser whether publishers like it or not. That makes it doubly important to (a) have compliant mechanisms on the browser vector for mediated reads, and (b) bring far more publishers into the gateway/API ecosystem that agents should prefer anyway, because those channels are faster, cleaner, and easier to instrument.
Your framework feels like the right foundation for treating both sides—agentic AI Reads via MCP and mediated reads via the browser—as real usage that deserves consistent schemas and reporting.
…I’m a bit more torn on tracking chunk‑level citations as a metric of institutional value and wonder if it isn’t a simpler matter of tracking tokens flowing over the AI pipes to subscribed content collections vs. a complex attribution regime to mix‑and‑matched semantically chunked content — at least as a first step, a clean “how much work did the model actually do over our licensed corpus?” signal may be more intelligible to libraries than a highly granular, provenance‑heavy citation layer that risks looking like glorified indexing rather than recognizable usage.
Thank you all for these thoughtful contributions and especially in broadening the scope of the discussion. I think the great thing about the current moment is that we don’t have to choose one approach over the other right now, nor wait for perfect standards.
Between Wiley’s Scholar Gateway, Scite, Cashmere, the emerging MCP ecosystem and other initiatives, we now actually have real usage data flowing through different models, so that we can already start to pilot the different approaches with libraries and publishers. Testing which metrics are most useful for renewal decisions, how different tracking methods compare for demonstrating institutional value, what privacy-preserving approaches work at different granularity levels etc, and how these findings could inform COUNTER’s third-party usage standards development.
Thoughts on organizing some coordinated/collaborative pilots?
Chris, strong support for coordinated pilots. The ecosystem is mature enough now that we can test real questions rather than debate hypotheticals. Neutral convening (NISO? Library consortia?) might be good here. Happy to contribute if helpful.
Is it allowed to include image from this post to my own presentation on related topic? Sorry, I did not find any information on rights.
Our images are licensed through istockphoto.com and you would have to contact them for reuse rights.
Did you mean the AI search flowchart figure Natalia?
If so, then the author of the post can grant any permissions needed.
I mean AI flowchart figure. Can I use it?
Email me at scholarlykitchen@sspnet.org and I will put you in touch with the authors to secure permission.
Thank you. I just compose a flowchart like that myself.