
We’ve known for a while that most research data eventually gets lost. To plug this slow leak (and stem the waste of of funding and effort it represents), some journals now ask that the data associated with a paper be archived at publication. There’s a whole host of different data archiving policies out there, but which are most effective?
I was lead author on a recent study that looked at how often data got archived in journals with three different flavors of archiving policy. Our paper looked at four journals with no policy, four that recommended archiving the data in a public database but stopped short of requiring it, and four that had recently adopted a mandatory archiving policy. These latter four split into two groups, with two journals that required authors to have a “data archiving statement” in every manuscript, and two that did not.
Since archiving standards vary widely depending on the kind of data, the study focused on datasets used in a particular population genetics analysis called “Structure.” The input file for this is relatively simple, and the technique widely used in evolutionary biology. This approach held the author community roughly constant across journals, and at the same time eliminated variability due to the inclusion of different types of data.
The graph more or less speaks for itself:*
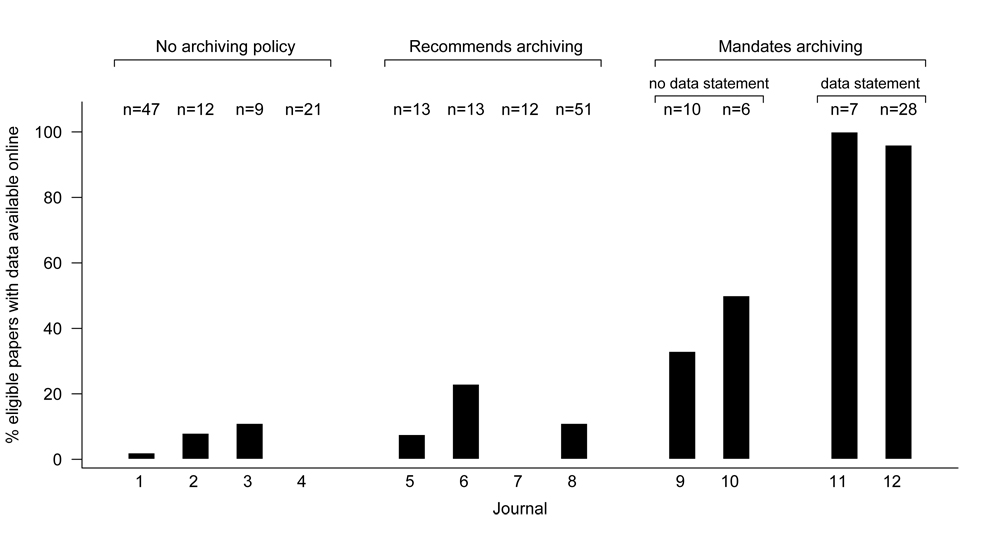
When there’s no policy, almost no data sets are archived (3 of 89 studies). Recommending archiving is barely more effective, with data from only 10 of 89 studies available online. The double whammy that really gets the job done is having a mandatory policy and requiring that all authors have a “data archiving statement” in their paper.
The study didn’t include any journals that only recommended archiving but absolutely required a data archiving statement, but it may be that making authors explicitly state “I’m not going to archive my data” in their manuscript is so unappealing that they put their data online. This approach may work well for journals that span a number of fields or in disciplines where data archiving is not yet on the radar — the journal doesn’t need to persuade the editorial board to adopt a mandatory policy straight away, but peer pressure should act to ensure that a significant proportion of data gets archived.
Lastly, the study also tried to get data from two of these journals by asking for it directly from the authors. About half of the requested datasets did arrive, which is a massive improvement over previous surveys (see here, here, and here). However, the data were requested only a year after publication, so 50% is probably the upper limit — authors leaving science and erasing their hard drives will steadily erode this proportion until, years later, only a few datasets are still available from authors. By contrast, all the data online in public archives will still be there, good as new.
Not archiving data alongside the paper makes about as much sense as not publishing the figures, so let’s hope that with the right sort of prodding we can get all these datasets out into the public domain.
(* I am also the Managing Editor for Publication #12.)


Discussion
18 Thoughts on ""I Want" Doesn’t Get — Just Recommending Data Archiving Isn’t Nearly as Effective as Requiring It"
Could not find treasuremytext on Apple App Store. Does it exist as a different name?
The image was inserted as a rhetorical device. It looks like it’s only available for Android, by the way.
The link to the paper doesn’t work…
Thanks. There was a missing “http://” in the link that had been inserted. I’ve fixed it.
Thanks!
Tim, any thoughts on the difference between fields and types of data where there are clear standards and fields and studies that are less structured or perhaps use innovative techniques? Is it enough for a journal to just require some form of archiving in general, or do we need to continue to work toward policies whereby the data will be in a consistent and readily useable form?
Also, given your 50% success rate in actually getting hold of these datasets, it would seem that fields where there are formal and independent data repositories are better off. Journals that require deposit of DNA sequence in something like GenBank don’t have to worry about recalcitrant authors or link rot as researchers move from job to job.
Right now there’s a lot of variability between fields, which is partly a reflection of differences in attitude between communities, and partly a reflection on how easy it is to archive the data underlying the papers.
For example, microarray data can easily be placed in either GEO or ArrayExpress, but researchers working with humans or on cancer are much less likely to archive it. This study (by Heather Piwowar) encompassed a wide range of different archiving policies but no journal managed to get more than 70% of the datasets.
However, while some of these journals had mandatory policies, none required that a ‘data archiving’ statement appear in every manuscript. Our paper has evidence that this extra step is very effective, and can lead to a very high proportion of datasets being made available. We suggest in our paper that a mandatory data statement combined with a ‘recommend archiving’ policy would be a good first step for fields where archiving is not yet the norm: authors are faced with a choice between saying that they refuse to share their data or saying where it can be found.
I think it should be up to the funders what data gets archived, not to the publishers. Archiving is laborious, hence detracts from research, and it creates an ongoing expense. Both the burden and the cost come out of the funder’s budget. By the same token are the publishers expected to bear the ever increasing cost of enforcing these mandates?
There may well be cases where the data is simple, well defined and easily archived so a universal archiving rule is workable, but surely these are the exception. In some fields data preparation and archiving costs are potentially huge, up to a third of the project cost. Only the most important data should be archived in such cases.
Even in simple cases imposing cumulative burden and cost on the research community should be done by the funders who pay for it not by the publishers. Publishers should not make research policies that have nothing to do with publishing. The publishers should not try to manage the scientific enterprise.
Personally, I think it should be up to the scientific community to decide what gets made available – after all, they are the end users of archived data. This idea is at the heart of something we’re working on, whereby authors have to say right at initial submission which datasets they plan to make available and where (in a data archiving statement), and the reviewers are asked to comment on the adequacy of this statement. The role of journals here is to provide a venue (peer review) where consistent standards can be developed and enforced.
More broadly, funders can mandate archiving until they’re blue in the face, but as they’ve got very little leverage to make sure it happens, these mandates have little effect. By contrast, having archiving mandates kick in when an article is being accepted for publication can be very effective (as we show), even though it does involve publishers taking a role. For the record, with respect to your point “publishers should not make research policies that have nothing to do with publishing”, the policy adopted by journals 9 to 12 in the figure above (the Joint Data Archiving Policy) was developed by senior researchers and editors-in-chiefs – these people are the scientific community and not publishers.
Lastly, I have to take issue with your assertion that it costs too much to archive some sorts of data: I agree taht it can be very expensive to prepare and store data from a big project, but these costs must be balanced against the cost of a) collecting that same dataset again should you need it and b) the cost of throwing away irreplaceable data.
For (a), compared to the cost of recollecting a portion of these very large datasets multiple times, you’d be better off just keeping the original ones. There are cases where storing some aspect of the data is more efficient than storing it all – for example, keeping a DNA molecule in a tube in a freezer and then sequencing it over and over is far easier than storing the petabytes of data produced when it gets sequenced, although this clearly can’t be accessed by the broader community.
For (b), there are some data that can never be collected again, for example climatic data from 2010 or a biodiversity survey in a field from 1901. Throwing these away might save some money, but these datasets can become extremely important in later years – they are literally invaluable.
Seems like a jurisdictional issue to me. As a funder I want to know why you are imposing costs and burden on my researchers that I have to pay for? If the publishers want to pay for archiving that might help but the burden is still taking research time away.
I did staff work for the US Interagency Working Group on Digital Data which is the data policy people from the federal funding agencies. They basically concluded that there is presently no money for extensive new archiving, beyond the present individual projects case by case approach. And now the budgets are probably getting cut. You seem to disagree so my first question is what percentage of the present research budget should be diverted into data archiving, including burden labor? Second is how much archiving will this buy and how should it be allocated? Third is where is the analysis that shows this is cost effective?
New costs have to be justified and you are proposing a massive program. I do not buy it. Vague thoughts of future benefits do not justify cutting the research budget this way.
Oh and the funders have lots of leverage. They just are not using it your way because after careful deliberation they do not think it is a good idea.
To answer your first point:
There are projects like telescopes, atom colliders and genome sequencing projects that are going to produce a huge amount of data per day, and the funding agency has to decide whether it’s going to pay extra money for that data to be kept long term. I think we agree that these projects exist and that data archiving costs are major part of the funding considerations.
For all the rest of scientific research, data archiving costs are a tiny part of the time/money equation. If funders begrudge spending money on archiving, they have no understanding of the scientific process. For example, most of the time spent doing research is spent on far more unproductive activities than data archiving. Here’s a quick walkthrough::
1) Identify a question, which involves weeks or months reading, listening and talking to people. Most of what you hear and read only tells you questions that have already been asked or are not worth asking.
2) Once you’ve got a question, work out how to test it. This involves working out what data you can find or generate, and then puzzling over whether those data actually do answer that question. Again, this takes weeks.
3) You try a pilot experiment. It gives a totally unexpected answer. Why? Spend three weeks finding that two wires weren’t plugged in/a data column was mislabelled/an undergrad put your samples in the oven
4) Repeat (3) or panic and go to (5) because your funding is running out.
5) Go ahead with the large scale experiment. Work 12-15 hours per day for six weeks collecting data.
6) Try to analyse the data. A third of the samples had something strange happen, so now your design is unbalanced. Spend a month learning how to fit zero-inflated non-linear binomial models. Spend another month realising that wasn’t the right test and start with a new approach instead.
7) If the experiment actually worked as intended, start writing the paper. This takes about two months, and normally involves repeating parts of (5) and (6) a few more times.
8) Try to get it published. If accepted, the journal asks you to put the files from (6) onto an online archive, which typically takes hours, or in some cases a few days. Celebrate.
What I’m trying to say is this: for most of science, targeting the time spent on data archiving as time that could be spent by the researcher doing something more productive is ridiculous. So much time gets ‘wasted’ through the cycle of testing your questions and finding new ones that a day here or there is trivial. Moreover, having the data publicly available means that others don’t have to repeat your wasted time.
To answer your second point, and a few others:
“There may well be cases where the data is simple, well defined and easily archived so a universal archiving rule is workable, but surely these are the exception”.
I don’t think this is true. Most science that’s not focused on analyzing previously collected ‘big data’ is based around discrete experiments or surveys, and the data underlying these are typically not more than a few GB. This is true right through the biomedical sciences, biology, chemistry and some parts of physics. These data can readily be archived when a suitable archive exists.
“what percentage of the present research budget should be diverted into data archiving, including burden labor?” and “where is the analysis that shows this is cost effective?”
This is the big question. In terms of funding to individual researchers, zero. Taking data you’ve got already and putting it online is a tiny step at the end of a long and laborious journey. You might as well start earmarking money spent doing statistics or reading science blogs.
In terms of using research funding on starting and maintaining data archives, not a lot. A study by Piwowar, Vision and Whitlock on the annual costs of maintaining the Dryad archive and adding 10,000 datasets came out to $400K. That’s in the region of 2 or 3 NSF grants, out of the hundreds they give out per year. Those 10,000 datasets would cover data archiving for all published papers in ecology and evolution. So, I’m not proposing a ‘massive program’, it’s actually very small relative to the costs of funding basic research.
“Vague thoughts of future benefits…”
The Piwowar paper also estimates that re-use of the data in the microarray archive GEO led to about 1150 extra research papers in 2007-2010. These are real benefits being accrued by archived data.
Taking data you’ve got already and putting it online is a tiny step at the end of a long and laborious journey.
There’s more to it than that, if you’re asking for that data to be reusable by others. I think back on the datasets I collected, and I know that I had my own idiosyncratic system for organizing it, and if I dug carefully back into my notes, I could figure out the exact details of any particular time lapse movie I’d made, and decipher the cryptic coding used to annotate it onscreen and in the file name. Translating that into an organized system with a set of instructions for the next user would have been a time-consuming task. Given the very specific nature of the experiments I was doing, looking at one particular cell type under one very specific set of conditions, it’s unlikely anyone else was ever going to reuse my data. The question then is whether it would have been worth several weeks of my time to get the data into a reusable state, as compared with doing several weeks of new experiments.
I agree that going back and find the right spreadsheet and annotating your code is hard if archiving comes as a surprise late in the publication process. However, once the community has the general expectation that they’ll be asked for their data, the annotation and organisation steps are just part of the analysis process, and then it takes much less time to do.
True, if required, it will be built into the process of data collection. But no matter when it happens, it still represents additional work and time spent. The question is always going to be whether this is a wise investment of effort, particularly for datasets that are addressing highly specific questions and are unlikely to see reuse.
The other thing I wanted to point out is that I know of imaging labs where every student/postdoc in the lab is churning out terabytes of data (high resolution time lapse movies of cellular movements and expression patterns). This creates a major expense and general headache for data archiving within the lab for the researcher’s own use. If you’re extending that to making a public version available, you’re talking about additional storage expense, not to mention the costs of bandwidth for serving up datasets of this size, administration and maintenance of the system, etc.
I’m not saying it’s impossible, or not worth doing. But for many fields, it’s a lot more complicated than putting a small text file up online.
I agree with everything you’ve said – some fields produce data that aren’t worth archiving. The best long term solution is to allow each community to determine what data need to be archived at publication, and have the journal enforce those standards.
We’re currently experimenting with a system whereby the authors have to say at submission which data they’re going to archive, and the reviewers are asked to comment on whether their list is adequate. It’s early days, but I’m cautiously optimistic that reviewers will get used to doing this after a few years.
I should mention that the pre-print version of the article is available on the arXiv at http://arxiv.org/abs/1301.3744


