Editor’s Note: Today’s post is by Hong Zhou, with editorial support from Megan Prosser. Hong is Atypon’s Director of AI Products and R&D, responsible for the design and delivery of artificial intelligence-driven information discovery services and technologies. Megan is Atypon’s Senior Director of Marketing, experienced at building marketing teams and strategies for high-tech startups and publishing organizations.
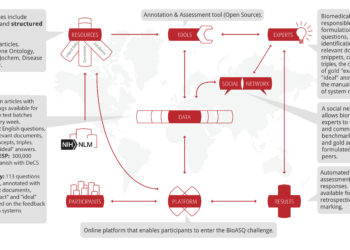
When one of the world’s most significant AI competitions invites you to speak, the answer is naturally yes, especially when it’s such a great opportunity to listen. In this case, it was a chance to learn from distinguished leaders from the National Institutes of Health (NIH) and Google, my fellow panelists Dina Demner-Fushman and Keith Hall. They both returned, along with numerous other dedicated participants for the 9th annual BioASQ workshop, hosted online this past September. Through BioASQ’s open technology challenges, we are all collectively striving to sharpen the cutting edge of biomedical information discovery systems — work that has significant value for the scholarly publishing community (and beyond!).

Our moderator and BioASQ lead organizer, Anastasia Krithara, helped make the conversation feel more like a brisk Zoom meeting with a handful of smart, thoughtful friends than a formal speaking engagement. Although it was still disappointing for COVID-19 to have kept us physically apart for another year, the valuable tradeoff is how the pandemic continues to provide an urgent real-world target with global consequences. By adding data and discovery system challenges that tackle the biomedical mission of the moment, if not the century, tech challenges like BioASQ move us faster toward systems that can not only advance biomedical content discoverability, but also increase the dissemination and readability of all scholarly content.
The shared innovation that BioASQ inspires can vastly improve a publisher’s ability to extract and deliver knowledge more quickly — from any size corpus. So, I’m happy to share some of the specifics of my panel experience with The Scholarly Kitchen readers.
Winning More by Winning Together
The title of our panel discussion was “Explicit and implicit benefits from challenges such as BioASQ.” It’s a topic I touched upon in a previous guest post, and it was encouraging to hear my fellow panelists agree that an ongoing international technology contest like BioASQ — with its open, head-to-head, competing systems format — stimulates broad collaboration that’s otherwise unlikely, if not impossible.
As Google’s Keith Hall put it, “In general, challenges are really good for rallying the research community, and this is true inside of big companies as well as at academic institutions.” Helpfully, BioASQ brings both groups together, and takes ideas outside of the institutional walls that typically contain them.
At Google, Keith is a leading research scientist who specializes in natural language processing and large-scale machine learning. One example of his work is Google’s BioMed Explorer — a tool that now includes all PubMed publications (31+ million scientific papers) as well as the content from PubMed Central. Faced with the flood of new research in response to COVID-19 and how difficult it is to follow, Keith was instrumental in launching Google’s COVID-19 Research Explorer, a semantic search interface on top of the COVID-19 Open Research Dataset (CORD-19) that includes more than 300,000 scholarly articles and counting. Keith also has interesting biomedical experience in applying AI to identify new drug compounds.
Involved in BioASQ since its inception, the NIH’s Dina Demner-Fushman, MD, PhD, leads research into artificial intelligence, natural language processing, data mining, and related disciplines that support clinical work and education at the Lister Hill National Center for Biomedical Communications at the National Library of Medicine. She works on the frontlines of technology’s role in biomedical scientific literature, designing systems capable of interpreting clinical notes and answering consumers’ health questions — basically, everything BioASQ was conceived to accelerate. (The author of more than 200 articles and book chapters in the fields of information retrieval, natural language processing, and biomedical and clinical informatics, Dina also gave this year’s invited talk, which focused on COVID-19.)
Adding to Keith’s point about the virtues of competition, Dina noted that she very much wanted to win BioASQ in earlier years, but has come to appreciate the ‘group effort factor’ as the superior prize. She eloquently emphasized the value of “exploring as a community” and how this approach can achieve so much more — so much faster — than any single research group, no matter how well funded.
The Challenge of Turning Passion Projects into Products
Ironically, in certain contexts, funding can slow down or derail progress. For example, the National Library of Medicine’s board of scientific counselors used to expect Dina and her team to turn their research directly into products, but complications outside their core capacities dragged on and on, until everyone involved realized that it’s much better to stop with successful research and leave the engineering challenges of commercial exploitation to others.
So how can both factors align towards needed breakthroughs, asked Anastasia; and how can BioASQ support that synergy?
I noted that devising an open brainstorming culture across the aisle, so to speak, can help strike a healthier, more productive balance between enterprise goals and researcher goals. After all, the content technology we’re developing in the biomedical realm can be used in publishing sectors beyond STM.
In fact, it’s not even just about publishing. Ultimately, it’s about problem solving. (Don’t get me wrong, I am still driven by the thrill of winning. Sometimes to a fault. Guilty as charged.)
Deep Learning AI versus Traditional Approaches
In discussing problem-solving innovations, Anastasia brought up the burgeoning “deep learning era” and asked how we felt about the disruption of more traditional approaches to information discovery, like basic keyword matching (which lacks semantic meaning recognition that deep learning techniques offer).
Martin Krallinger, head of the Text Mining Unit at the Barcelona Supercomputing Centre and a BioASQ organizer who co-moderated the panel, noted that more complex, sophisticated tools can sometimes obscure nuanced comprehension and clarity.
“There’s a lot of work on explainable AI and identifying rationales for the decision-making, the inferences that neural models are making,” Keith added. “It’s not exactly taking advantage of traditional discovery approaches. It’s more trying to find ways to attach functionality that we had with them, that we’re missing with super-complicated neural models that have millions of parameters and their interaction is somewhat opaque.”
In other words, an answer that is entirely detached from the process of generating it, can feel like a leap of faith. As Keith reiterated later, traditional approaches can and should supplement advanced deep learning methods—and I agree that they should remain integrated to varying degrees, depending on the user’s needs. Otherwise, deep learning risks becoming too much of a black box.
Advancing Towards More Realistic Tasks and Goals
With the pandemic as a prime example, Martin added that, by generating resources in a transparent way, challenges are more efficient than conventional R&D when it comes to engaging different communities and focusing them on rapidly-changing end user needs.
Anastasia ran with his point and suggested that the BioASQ contest can better serve those needs by adding “more realistic challenge tasks and more realistic data.”
BioASQ has already achieved quite a lot by using real data — it’s a distinct feature of the challenge that has yielded substantial accuracy improvements over the years. But we can add more! For example, content classification and semantic indexing could be based not just on abstracts, but on full-text or a combination of important sections. BioASQ could also add system challenges focused on making information retrieval more personalized to each user, as many other industries, like consumer marketing and customer service tech platforms, are focused on.
Martin and Anastasia agreed that end users should ideally play a greater role in designing future challenges, to give us more practical applications that are based on winning system challenges. And Anastasia suggested inviting end users to a workshop with the competing systems and teams behind them, almost like a participatory focus group model.
Martin was particularly frustrated that some great biomedical information discovery systems never realize their full potential. In effect, promising ideas stay on the drawing board because of a reluctance to share code. (I’m pleased to note that Atypon shared our winning code from this year’s Spanish-language content classification BioASQ challenge with Martin’s colleagues at the Barcelona Supercomputing Centre.)
As someone with a foot in both worlds, I pinpointed a core cultural divide: researchers want the most advanced and accurate innovations, while commercial enterprises want the most reliable and scalable innovations.
The Next Decade in Discovery: From Content Providers to Knowledge Providers
So, what did the panelists see ahead? Particularly with the advent of 5G, I believe that multimedia content forms like images and video will become even more common. And a key frontier coming soon will be extracting semantic information from these media to enrich the written word.
Machines will increasingly become content generators. Can we add a BioASQ challenge in which the AI system authors an original, responsive summary of the content it scans? Can we also add tasks that develop AI’s capacity for reasoning inference, an ability that comes naturally to humans and that could tap into so much valuable hidden knowledge across publishers’ corpuses if unleashed at scale?
Keith from Google hopes to see challenges that cover multiple and varied dimensions pertaining to a clinical question. Many of his customers want a streamlined search functionality, but with levels of analysis comparable to the more traditional methods they are comfortable with. “If it was easy,” he added, “there would already be a BioASQ challenge related to it.”
The greater challenge, as Keith sees it, is the balancing act between being visionary enough to explore what might be useful in the future and focusing diligently enough on the needs already being pursued in the here and now. (It’s not difficult to imagine that being a constant conversation at Google.)
Dina’s wishlist for the future includes better evaluation paradigms. As it stands, she said, “we are still relying on the individual’s subjective manual judgements in most cases.” And that’s a bottleneck to overcome, as she, for one, is always hunting for better evaluation metrics.
But First, Next Year
Officially, I was representing both Atypon and the Atypon-Fudan University team at BioASQ, but I also aimed to stand in for the broader scholarly publishing industry. By focusing on how AI-driven content discovery insights and breakthroughs can lead to powerful solutions and products for any publisher, I hope to bridge the cutting-edge work of my fellow researchers with future commercial applications. Building such bridges is good for both parties: BioASQ needs more real-world tasks based on real-world requirements and constraints; publishers need more AI-driven information discovery products to optimize their content, its accessibility, and their users’ experiences while more efficiently modernizing their operations.
BioASQ is making great strides in the biomedical realm, but all publishers should take note — and take advantage of — the emerging opportunities to transform how they serve and grow their audiences.
Exciting is an overused word, and I think it will quickly give way to essential. The powerful information discovery innovations that BioASQ is incubating today will be among the standard-issue content delivery tools of tomorrow, and that shift is moving faster than most imagine. (In fact, my next blog post should be a step-by-step primer on how all publishers can start incorporating AI content discovery tools into their programs.)
Next year, I hope to be in the same non-virtual room with my fellow panelists. Connection is a precious commodity. But, whether or not we are physically together, I know that through BioASQ and its growing community, we will continue inspiring, building, and exploring better information discovery systems, work that I want to share with the broader scholarly community to help publishers and societies become knowledge providers in their domains, rather than content providers.
This year, the Atypon-Fudan University team is excited to have won four out of four BioASQ biomedical discovery challenges.

Discussion
1 Thought on "Guest Post — Google, Atypon, NIH, and Information Discovery’s AI-Fueled Future: Notes from a BioASQ Panel"
“Can we add a BioASQ challenge in which the AI system authors an original, responsive summary of the content it scans?” Scholarcy, https://www.scholarcy.com/, does this. While I don’t support students using Scholarcy to substitute for learning to read and digest the main points of articles, it has other uses, including the generation of poster presentations for conferences.
Disclosure: I did my PhD research with 1 of the co-founders.