Since the release of ChatGPT, I’ve been asked to contribute to discussions about Generative AI, Large Language Models (LLMs), and GPT itself, both in webinars and to support internal strategic discussions, particularly at small publishers and learned societies (See this free webinar from STM, and this one from EASE).
Plenty of attention has been paid to Generative AI and LLMs on the Scholarly Kitchen this year. Back in January, Todd Carpenter interviewed ChatGPT itself on a range of controversial topics relating to AI, and got what I think is fair to say a series of human-sounding, if unimaginative and non-committal, answers. Also in January, Phil Davis pointed out that ChatGPT makes stuff up, a phenomenon that’s since become well known as ‘hallucinations’. Our first guest post on the subject, from Curtis Kendrick of Binghamton University Library concluded that ChatGPT was about as good at summarizing a topic as an average Wikipedia entry, but that it cannot cite its sources.
Excitement about LLMs was widespread in the first half of 2023. ChatGPT set the record for the fastest growing userbase in internet history, reaching 100 million monthly active users by February, just two months after launch. This remarkable success invigorated an AI arms race, focused on LLMs, that had been trundling along for a few years involving Google, Meta, and of course Microsoft, thanks to its partnership with OpenAI, the company behind GPT.
An inevitable course of events soon started to unfold… Faster than you can say Gartner Hype Cycle, a truly bizarre open letter calling for a six-month pause on AI research, co-authored by Elon Musk and seemingly designed to stoke techno-panic (as opposed to rational, sensible debate about technology regulation), was signed by nearly 30,000 people by mid May. Articles about wild overhyping and its threat to business became more frequent, and ChatGPT lost users in July. Unsurprisingly, we started to see articles about the end of the AI craze.

What does Gartner say?
The technology consultancy Gartner, conduct an annual analysis of emerging technologies based on a model that when a new technology is created, there is significant hype associated with overblown expectations, followed by a lull or even crash in expectations before the true value of the technology emerges later. The terms that appear on the hype cycle graphs are not only technologies, but also the names and buzzwords that get associated with technologies.
The 2022 emerging technology hype cycle, featured in this August 2022 blog post doesn’t mention Generative AI or LLMs specifically, but it does mention foundation models, which include LLMs. Even before ChatGPT, Gartner thought these models were near the top of the so-called ‘peak of inflated expectation’. Interestingly, code generation and generative design, two important use cases of LLMs, were shown right at the bottom of the curve.
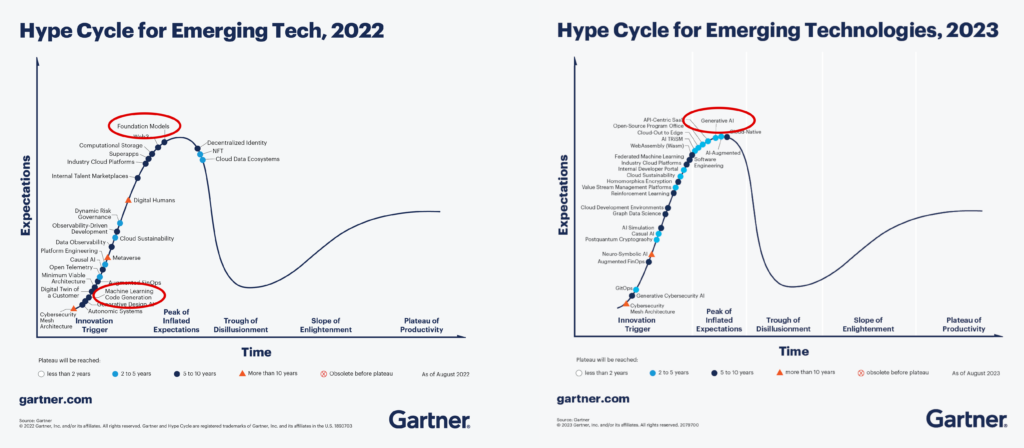
The same analysis in 2023 gives generative AI its own dot on the curve (as I mentioned above, it’s not just about the tech, but the words we use to describe the tech). Generative AI is almost at the precipice, a little further along towards the big, rollercoaster-like drop into the ‘trough of disillusionment’, although lagging slightly behind buzzwords ‘Cloud-Native’, and ‘AI-augmented’. Gartner are clearly expecting the crash in expectations soon, but seem to be hedging their bets slightly on exactly when that’s going to happen.
Seeing to the other side of the trough
One way to think about what the hype cycle tries to show us is that, as a whole, humans tend to overestimate the short-term impact of technological advances and underestimate the long-term consequences. When it comes to Generative AI, there are quite a few consequences to be considered, including copyright issues, authorship and plagiarism, when or whether information from generative AI could be trusted, and further control of information and, ultimately, money by tech giants.
Is it possible to guess what real drivers of value for LLMs will emerge as we slog back up the ‘slope of enlightenment’ in the months and years to come? Perhaps the best place to start is to look at what people are already successfully doing with LLMs and with AI more generally. I’ve spoken to a number of people recently, both in our industry and elsewhere, who have been using ChatGPT to help with a variety of tasks. Blog posts, text for marketing collateral, and helping to compose business emails are the most common uses people have told me about. While these are important functions, they’re notably not part of the core business of creating journals, books, or other information products.
Looking at the use of AI in other sectors, in journalism, LLMs are now routinely used to translate stories, summarize them for different audiences, and create digests. If we look at marketing, AI is even more widespread. As well as the use of LLMs to create, translate, and enhance copy, various forms of AI have been in wide use to improve customer journeys, build strategies, and engage with customers since before the great ChatGPT hype took hold. According to this Salesforce blog post, the use of AI by marketing leaders jumped from 29% in 2018 to 84% in 2020.
It’s important to point out that marketing content, and even journalism, are different from scholarly literature in that they’re not held to the same high standards. Peer-reviewed literature is intended to have a much higher level of authority, which is why so many publishers have banned using ChatGPT as an ‘author’ on papers. Perhaps it’s therefore helpful to look at what we’ve actually trusted AI to do in our industry in the past; primarily summarization, discovery, research assessment, and integrity.
One good example of summarization is Elsevier’s topic pages, which distill entire research topics down to bite-size primers based on information from dozens or hundreds of research papers. I don’t know if Elsevier uses LLMs to create this content, but they have been creating these pages since at least 2018 (according to the Wayback Machine), when they were described as using ‘innovative automated approaches for information extraction and relevancy ranking’. Elsevier isn’t the only organization to have been doing this sort of thing since before ChatGPT. Scholarcy, a finalist in the Karger Vesalius awards in 2020, is an AI-powered article summarizer. Companies like Zapier, SciSummary, Petal, and dozens of other startups are also trying to get in on that particular act, often enabled by GPT or one its technological stablemates.
This brings us to discovery, which thanks to AI has increasing overlap with summarization. In fact Scholarcy, which I mentioned above, is often billed as a discovery tool. Discovery has always been an important value proposition for startups in scholarly publishing, so it’s no surprise a plethora of companies like Scite, ScholarAI, Keenious, and Scispace are all combining AI and discovery in some form.
Microsoft Bing (which vehemently denies being based on GPT if you ask it) and Google Bard both now incorporate language models into web search, so would something similar be useful for scholarly search and discovery? Both Digital Science and Elsevier clearly think so, with their rollouts of Dimensions AI Assistant and Scopus AI respectively. As I’m sure Joe Esposito would remind us, It’s worth noting that these are both features of existing products, rather than products themselves, but nevertheless they’re very interesting. As discovery solutions with a Chatbot component, they begin to bridge the gap between summarization and discovery to create a pseudo-conversational interface, which will likely feel more intuitive to both non-experts and students who haven’t yet developed rigorous skills around systematic literature searching.
AI is also making an impact on approaches to analysis and assessment. Digital Science took a lead in this area by publishing open reports that used machine learning techniques such as topic modeling and natural language processing, like this one analyzing grants applications received by the Arts and Humanities Research Council, and their work on the 2014 REF, analyzing case studies to identify networks of ideas. Their portfolio company, Ripeta, uses AI to assess research integrity indicators in research article text. Another important effort here is the STM Integrity Hub, which is working with startups like ImageTwin, Proofig, FigCheck, and Imacheck to develop automated image checking tools. The Integrity Hub is also working on approaches to identify paper mill content. Of course, AI-based assessment is not without its own potential drawbacks and, like other similar use cases for AI, it should be thought of as an aid to decision-making, rather than a way to entirely automate it.
It seems clear that GPT and LLMs in general are at or near the peak of the hype cycle. Fears that ChatGPT is intelligent and may plot against humankind are premature; hopes that LLMs alone could radically change how our and other industries work are similarly overblown. The transformer models that underlie the LLMs that have made headlines over the last 12 months are an important step forward in language generation, and will play a part in the future of AI, but they’re only one part of a broader range of technologies. Major technology players in the scholarly communications space are already finding ways to make use of Generative AI and are experimenting with options. What remains to be seen is the mechanisms by which the resultant tools and features will be made available to smaller and independent publishers, institutions, and funders.

Discussion
6 Thoughts on "GPT, Large Language Models, and the Trough of Disillusionment"
“It’s important to point out that marketing content, and even journalism, are different from scholarly literature in that they’re not held to the same high standards.”
This is probably the understatement of the year.
I reckon that LLMs are to the scholarly (and even mainstream) literature what soft drinks/sodas are to human nutrition–lots of empty calories (i.e., content that seems eloquent, persuasive, and exciting but doesn’t withstand much scrutiny) that show their harmful effects further down the line.
Gartner have gone to even greater hype cycles lengths, which seems special for 2023 and created a specific “Hype cycle for Generative AI” which really helps break out and organise all the different parts/types of generative AI.
Gartner have kept the detail behind their generative AI hype cycle behind their paywall, but you can ask Bing Chat Enterprise to summarise each of the points on the cycle. Open source LLMs are going through their own focus right now especially with their impact off web scraping to train them.
Standard AI arms race warfare tactics to use their tools for your own good!!
As a non-member, though occasional, reader on your Scholarly site here, I would like to express my appreciation, Phil, for your report. I was a 1970’s English major who has since explored, successfully, several strains of modern employment.
Our High Country Writers group in Boone, North Carolina have been wondering–and occasionally talking about, this mysterious AI cropping up in the midst of our writerly reverie.
Thank you, Phil, for publishing this informative report on the Scholarly Kitchen. Keep up the good work.
Every scholarly publisher wants a piece of the action when it comes to AI. Yet, they are still at the experimental stage in many cases.
As this article eloquently illustrates, LLM-based AI technology is not mature yet.
And publishers will need to experiment for a long time to come before firmly implementing these LLMs as a means to improve the performance in delivery for their own products–let alone develop new products powered by LLMs.
However, I am surprised this article does not spend more of its focus on observing how more mature AI technologies, such as Natural Language Processing (NLP), are increasingly being implemented to power the needs of our industry, among others, for contextual and summarised information.
The author mentions that the current applications of generative AI including “marketing content, and even journalism, are different from scholarly literature”. Yet the piece does not account for the fact that journals from the scholarly literature themselves need to orchestrate their own content marketing campaigns to attract the next submissions.
Content marketing for science publishers can simply consist of reliable AI-summaries showcasing the latest research papers, to demonstrate the exciting work published in their journals. In this context, LLM-driven content generation fails to come up with content that does not hallucinate. Therefore NLP-driven content generation is much more reliable as it does not present such shortcomings. NLP is therefore much better suited to create reliable AI summaries of scientific studies. That’s because the extractive NLP summarisation approach extracts actual sentences from the source document, thus preventing the occurrence of hallucinations. These solutions are available. At SciencePOD (hhttps://www.sciencepod.net), we already provides on-demand extractive AI-summarisation solutions.
This year, we have gone one step further, to introduce novel solutions to support science publishers in their content marketing, as a means to engage authors more systematically. We have productised NLP summarisation to deliver personalised experience in research discovery to researchers. This is what the ScioWire (https://www.sciowire.com) newsfeed is about. It is a tool delivering custom newsfeeds made up of NLP-generated AI-summaries of the latest research studies. This sort of tool can be used by scholarly publishers to enhance their engagement with authors, to drive usage and submission, and even allows to personalise newsfeeds for each researcher, using keywords.
Last but not least, when we started introducing these sorts of NLP solutions a few years ago, the initial response from scholarly publishers was that the raw AI-generated summaries were not polished enough to be publishable. Now since LLMs have arisen, there has been an increase in the level of tolerance of publishers of ‘not-so-perfect summaries’, as they understand that sometimes AI-summaries are ‘good enough’ when it comes to increasing the productivity of scientists for literature discovery.
What is more, like the majority of publishers engaging in using AI solutions to generate text, at SciencePOD we have the capabilities to combine a raw first draft generated by machine with the intervention of skilled editors, who can polish the text, for the creation of plain language summaries, for example.
And that is good news for the generation of editors who have a very bright future improving the drafts stemming from generative AI.
Greg Brockman, one of ChatGPT’s co-creators, recently did an interview with University of North Dakota’s President Andy Armacost. Brockman attended UND as a high school student before moving on to MIT and Harvard, both of which he dropped out of to work on OpenAI.
You can view the video here: https://blogs.und.edu/und-today/2023/09/video-a-conversation-with-greg-brockman-co-creator-of-chatgpt/
He’s an insightful young man.
I find many of the discussions around LLMs and GPTs faintly amusing. At Access Innovations, in our Data Harmony software, we incorporated the same technologies in the late 1990’s. We’ve deployed them for our clients with great results. I don’t think of our technology as an LLM, but maybe an FLM – Focused Language Model – or even a YLM – Your Language Model. Each deployment is based on the client’s topic coverage, so it doesn’t need to incorporate everything available on the internet (including that Reddit content).
It seems that once again, what is old is new again. We’ve been doing this, successfully, for 26 years. Experience counts.



