The Recent History of Generative AI
As interest in generative AI and large language models (LLMs) continues to grow, I’d like to offer a brief update on how generative AI has progressed and how it has been applied to research publishing processes since ChatGPT was released. This update addresses business, application, technology, and ethical aspects of generative AI, as well as some personal observations I hope will foster discussion and stimulate further consideration of generative AI tools.
Note: I composed this blog post with the assistance of ChatGPT, Google Bard, and MS Bing. I outlined the structure and content, then used these three tools to gather some information from the internet, improve the writing quality, and finally generate a title based on its understanding of the content. The post was then reviewed and edited by several of my colleagues, and the title was updated to reflect the updated content.
A note on AI terminology
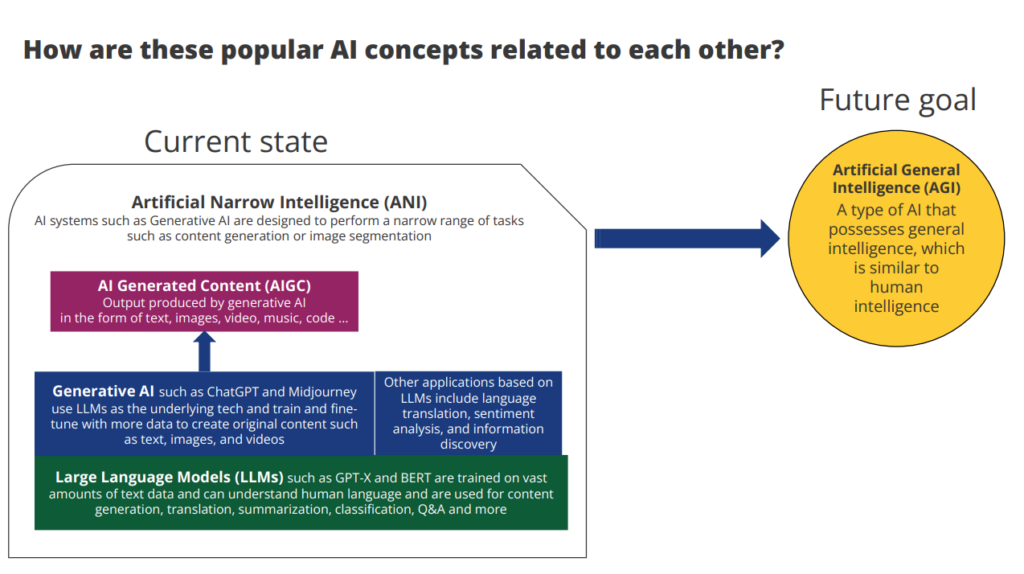
You may have seen a variety of AI terms in media coverage, such as large language models (LLMs), generative AI, AI-generated content (AIGC), artificial narrow intelligence (ANI), and artificial general intelligence (AGI). Before we start, a brief explanation of these concepts and how they are related to each other:
Business and strategy
ChatGPT is the fastest-growing app in history. Within two months, ChatGPT reached 100 million users, compared to the 42 months it took for WhatsApp to reach the same milestone. This rapid growth is especially remarkable given that ChatGPT reportedly blocks a huge number of Asian accounts due to possible batch account registration, API abuse, and technical issues caused by excessive traffic.
What does this mean for businesses? By revolutionizing app accessibility and problem-solving, ChatGPT threatens not only Google Search and Amazon but also the Apple Store, Google Play Store, and Amazon Skill Store. Users can simply set goals, then allow the AI to choose the appropriate services or apps, execute tasks, and aggregate the results.
Big tech companies are already integrating generative AI and LLMs into their existing commercial products to improve collaboration and productivity for users. Examples include the Google Workspace (including Gmail, Docs, Slides, and Meet); Microsoft 365 Copilot, including Word, PowerPoint, Outlook, and Teams; Alibaba’s Tmall and DingTalk; and Baidu’s Wenxin Yiyan (known in English as ERNIE Bot).
What does this mean for our industry? These advanced AI tools could significantly boost productivity and improve the user experience in information discovery, code generation, data analysis, project management, and more. They also have the potential to transform research processes. For example, generative AI tools may be able to help researchers with various parts of the research and paper writing process, including potentially to discover and analyze vast data sets to get more accurate insights, identify new research areas, write high-quality papers, and improve communication and collaboration across disciplines. In addition, AI can support screening and integrity checks during submission and review. While not based on generative AI, many of these services are already in use and continuing to improve; examples include auto-tagging, journal recommendation, and reviewer suggestion.
The big cloud providers, including Amazon, Google, Microsoft, Alibaba, and Baidu, have released their own generative AI models and plan to offer their services to customers via the cloud.
What does this mean for researchers and readers? Beyond SaaS, PaaS, and IaaS business models, emerging cloud-based offerings such as AI / LLM as a service and knowledge as a service are gaining traction, and leveraging these will in turn expedite further AI development.
Applications and solutions
Tools that leverage generative AI are creating a new generation of information discovery — faster, more accurate, more intelligent, and better personalized. Users are now looking for answers, not just relevant information.
ChatGPT may get the most media attention, but it’s not the only AI-augmented search game in town. Both Microsoft and Google are improving their search engines by embedding generative AI models, using different strategies: Google has integrated their search engine into Bard, their generative AI, whereas Microsoft has integrated their generative AI into their Bing search engine.
Based on my testing, Google Bard is faster than MS Bing, provides more detailed answers, and generates search queries; Bing is slower than Bard and produces shorter responses, but includes links as evidence. ChatGPT is better than either one in terms of understanding questions and tasks, but its knowledge of world events since 2021 is limited. With all these examples in mind, our team at Wiley Partner Solutions is designing and developing a next-generation discovery system, using AI to enhance our products.
More domain-specific AI models are emerging as the time and investment required for training decrease. For example, models like PubMed GPT can be created by fine-tuning the base models with domain-specific data sets to achieve better accuracy for specific tasks. This is a trend worth watching.
In addition, task-specific GPT tools can be created by combining ChatGPT, with its ability to create relatively human-like text, with other tools that have the knowledge and capabilities to perform specific tasks. Examples include ChatGPT + Wireframe Alpha for precise computation, ChatGPT + Midjourney for image creation, and Gen-2 for text to video. While these types of AI tools can facilitate research by speeding up time-consuming tasks or auto-generating images and videos from text, they can also be used in ways that raise concerns about research integrity — such as altering images and data or creating fake text or videos.
A third category of generative AI application can be described as GPT as Agent. This category covers AIs such as ChatGPT Plugin, AutoGPT, AgentGPT, HuggingGPT, and Visual ChatGPT that are becoming more self-sufficient: they can plan, execute, and learn from the tasks they perform without our input, and they can access up-to-date information, call other services, and aggregate results for different purposes.
What all of this means for researchers is that by using generative AI tools, they should be able to better analyze, plan, and execute their work, yielding faster and more efficient outcomes. Advanced generative AI can also be integrated into publishing-related workflows, platforms, and services to deliver more effective results for our customers.
Where we are now
In March 2023, OpenAI released GPT-4, a large multimodal model that exhibits human-level performance on various professional and academic benchmarks. OpenAI plans to introduce its next model, GPT-4.5, in the third quarter of 2023. These new AI models — which can learn from a variety of information sources including text, images, videos, and signals — can significantly enhance the readability, discoverability, and accessibility of the content we publish.
The LLMs in the “GPT-X” category are designed not only to encapsulate knowledge but also to be tailored to human needs. As more individuals and corporations adopt customized LLMs/GPTs to support their work without sharing their data, more such models are emerging, thanks to the availability of base LLMs, extensive training data, and faster frameworks.
Although Google currently lags behind the OpenAI + Microsoft collaboration in generative AI, it has considerable potential to close the gap in the future. We are also seeing more and more open-source and affordable LLMs, small enough to run on a local computer and achieve decent results.
Meanwhile, Meta has released the Segment Anything Model (SAM) — an AI model that can accurately segment anything on any visual content — along with a data set of 11 million images. SAM and diffusion models are considered a revolution in computer vision, just as ChatGPT is a revolution in natural language processing. Seven national governments (China, Cuba, Iran, Italy, North Korea, Russia, and Syria) have also effectively banned ChatGPT; Italy is the outlier in that its ban was explicitly related to privacy concerns and has now been lifted. And a long list of tech leaders have recently called on all AI labs to pause training of AI systems more powerful than GPT-4 for at least 6 months. While a global pause like this is almost impossible to imagine in practice, as no company will want to lag behind its competitors, it is crucial to discuss, understand, and address both the potential benefits and the potential harms of AI technologies.
In the scholarly communications industry, however, the focus should be on harnessing and adapting to these irreversible trends through internal experiments and evaluating existing tools for potential future use. As of June 2023, many publishers including Wiley, Elsevier, and Springer Nature, as well as individual journals, have amended their policies to explicitly ban ChatGPT as an article co-author; Nature has stated that they will not publish images or videos created using generative AI. University professors are expressing different opinions on ChatGPT, some encouraging students to use it in their studies while others discourage it. AI is still very new for most people, and it will take time to establish clear regulations and guidelines for ethical AI use. But based on current trends, it seems likely that more and more content will be generated through a combination of human and AI efforts, so we may need to reconsider definitions of contribution and authorship.
What’s next for generative AI?
Ethics and governance
Of course, all of the above is subject to effective ethical and governance controls. A significant advancement in new generative AI is its enhanced ability to understand, adhere to, and adapt to human values, needs, and expectations — not only on providing useful information but also ensuring that AI-generated content adheres to ethical, legal, and social norms and avoids harmful or misleading outcomes. User-centric design, accuracy, reliability, safety, privacy, and fairness are key concerns in this unsettled, evolving landscape.
According to OpenAI, their approach to AI safety focuses on rigorous testing, safety evaluations, real-world feedback, and continuous improvement; they prioritize developing safeguards, protecting children, respecting people’s privacy, and improving the factual accuracy of results, while actively engaging with stakeholders, governments, and the public to shape the future development of AI technologies. A piece in Search Engine Journal supports this view, while also noting that there’s still work for OpenAI to do. Google, Microsoft, and Amazon also have AI policies, standards, and practices which are aimed at creating fair, safe, and responsible AI.
Trust, risk, and security management will become even more critical as AI continues to advance. Gartner forecasts that “by 2026, organizations that operationalize AI transparency, trust and security will see their AI models achieve a 50% result improvement in terms of adoption, business goals and user acceptance” — highlighting that focusing on trust, risk, and security management is not just the right thing to do, but also critical to success.
The intelligence revolution
Generative AI is accelerating the transition from Web 2.0 (characterized by user-generated content, social media, and online collaboration) to Web 3.0, where users can better control their own data and engage in peer-to-peer interactions without intermediaries. We don’t yet know how this transition will influence authorship and ownership of research outcomes.
Because barriers to accessing and applying AI tools are diminishing, it will be increasingly important to define the right business models, provide customers with end-to-end solutions or platforms empowered by AI, and build ecosystems around them, so that customers no longer need to find, evaluate, and integrate a range of AI features from different vendors to meet their needs.
Rather than viewing AI as a competitor, individuals and companies alike should recognize its potential and strive to harness its capabilities. In the future, the competitive landscape will be shaped by the distinction between those who can use AI effectively and those who cannot. But balance is crucial here, because relying too heavily on AI may erode the critical thinking and creativity that give humans a unique advantage.
The future of human-machine interaction (HMI)
As HMI evolves from passive click-based interfaces to proactive prompts, ChatGPT shows how important it is to define the right question or problem. Prompt tuning is a key innovation in ChatGPT, allowing it to be applied more broadly without comprehensive fine-tuning. This progression has even given rise to a new profession known as Prompt Engineering.
This means we can expect fewer specialized apps but more “super apps” like ChatGPT and MS Copilot, aggregating services and features into a single user interface with a comprehensive ecosystem so that users so that users no longer need to install and switch between multiple apps.
Meanwhile, information discovery is progressing from fuzzy matching to semantic matching, and ultimately to precise info generation — in other words, from delivering relevant results to generating exact answers backed up by evidence. AI can not only enhance the quality of search results but also introduce new methods of information discovery (e.g., conversational searches, personalized results) that will help researchers develop high-impact work more quickly.
The evolution of research
As AI becomes more sophisticated, it may be able to better support researchers with a personalized assistant that can discover, memorize, and apply information and knowledge, but also offer broader, deeper, faster, and more tailored insights.
But while generative AI can facilitate collaboration and improve the quality, reproducibility, and transparency of research work, it also introduces some risks to research integrity. As we have already seen, AI’s capacity to generate human-like text and to manipulate images and data can be used for many purposes — including manipulating the publishing process. As new methods to manipulate content emerge, so too will innovative strategies to detect and counteract them.

Discussion
8 Thoughts on "The Intelligence Revolution: What’s Happening and What’s to Come in Generative AI"
When peer review processes (and their associated publishers’ policies) effectively fail to examine and diligence the data underlying authors’ claims in published manuscripts, call me skeptical the academic publishing community will invest in services that mitigate machine generated noise from polluting their pond.
I think that peer review should NOT fully rely on the ChatGPT/GAI. As I will demonstrate in my next post, GAI is good at extracting info and enhancing writing, but not good at criticizing things, especially when there is a need for deep domain knowledge. In our experiments, GAI has performed well in selecting the most relevant and differentiating between various research fields and article types (research article vs review). I think it has the potential to improve with finetuning with more relevant training data including review comments and papers. Such a system could be useful in the future to facilitate reviewers and editors during peer review but not replace people. Moreover, detecting machine generated noise is an endless battle and hard to do. When new LLMs are developed, new detection models need to be properly finetuned.
Thanks for your excellent summary on Generative AI. Finding proper reviewers for manuscripts is more and more difficult. Do you think that ChatGPT or similar apps might – at least partly – replace the reviewer’s tasks and support the review process of the editorial office in a medical journal?
We have done several experiments using ChatGPT and Bard on the peer review process. I think that peer review should NOT fully rely on the ChatGPT/GAI. As I will demonstrate in my next post, GAI is good at extracting info and enhancing writing but not good at criticizing things, especially when it needs deep domain knowledge. In our experiments, GAI has performed well in selecting the most relevant and differentiating between various research fields and article types (research article vs review). I think it has the potential to improve with finetuning with more relevant training data including review comments and papers. Such a system could be useful in the future to facilitate reviewers and editors during peer review but not replace people.
Thanks for this article. A small correction: ChatGPT has already been replaced by Threads as the fastest growing app. https://www.zdnet.com/article/threads-hit-100-million-users-in-under-a-week-breaking-chatgpts-record/
Indeed. Thanks for pointing this out. But it is out of my control. This post has been waiting for publishing for several weeks after I finish writing it.
Interesting article, but I feel like a reference to the companies and organizations already using LLMs for discovery and understanding in this space should have been made, such as scite (https://scite.ai/assistant), Elicit (https://elicit.org/), Consensus (https://consensus.app/), as well as others. These tools are already used by millions of researchers around the world. professors.
Indeed. There are many nice and innovative applications based on LLMs. https://typeset.io/ is also a nice one. I am going to write a post to introduce these discovery tools which change people’s ways to research



