Editor’s Note: Today’s post is by Hong Zhou and Hiba Bishtawi. Hiba is Product Manager – Information Discovery at Atypon. Hong and Hiba are designing the new generation of conversational based discovery powered by GenAI on the Atypon platform.
Whether you believe artificial intelligence is friend or foe, it’s undoubtedly changing many aspects of how we work, including the way we discover content, information, and knowledge. In our first post exploring AI and information discovery, we discussed the evolution of AI, and how it can potentially be applied to solve pain points for researchers and publishers alike.
Here, we explore generative AI (GenAI). These systems can produce original and realistic outputs based on the patterns and data they have been trained on. We’ll discuss how GenAI is moving us towards conversational discovery and what this might mean for publishing, as well as potential future trends in information discovery.

The future is here. How are scholarly discovery applications moving with the times?
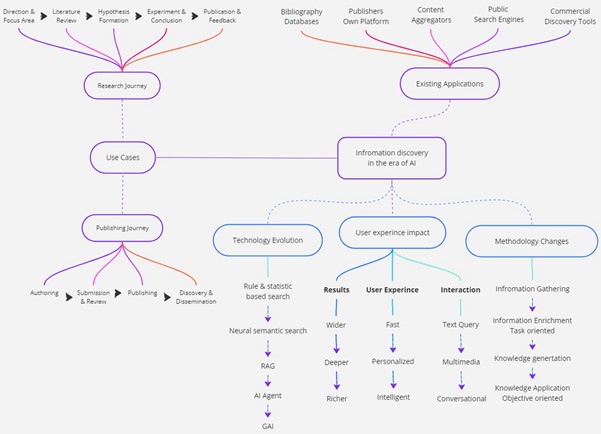
We’re already seeing an evolution in the technology affecting information discovery applications, along with a shift in the way researchers seek and use these applications. Public search engines are one of the most-used scholarly discovery applications, serving as a compass in a huge ocean of information. Commercial and researcher-facing discovery engines focus on open-ended reasoning, simplifying the literature review process and saving time and effort. And bibliography databases act as giant libraries holding metadata and information about millions of books, research papers, and articles to help researchers uncover valuable insights and trends. Let’s take a deeper dive into each of these applications…
GenAI native applications: Most of us have probably used ChatGPT to help us quickly find answers to any given question – and the same goes for researchers. Its ability to help analyze large amounts of information and data saves time and effort. However, it has limited updated knowledge – ChatGPT 3.5 only provides information based on the data it was trained on up until its latest update in April 2023 (although ChatGPT 4 is able to search the internet to get up to date information). Similarly, Google Gemini (formerly Bard) and Microsoft Bing Copilot help streamline the process of identifying relevant scholarly content, create and analyze images and datasets, and support contextual conversations and AI augmented answers. But they follow different strategies and have different goals.
Reading between the lines, it seems that Microsoft would like to leverage their advances in GenAI (they rely on OpenAI technology) to boost usage of and traffic to Bing (it currently has 3.6% of the global search engine market). On the other hand, Google may look to leverage their strength in search (they currently have 90.9% of the global search engine market) to boost their GenAI usage and compete with ChatGPT. And then we have Perplexity.ai, a popular new conversational search engine which presents a clean and simple way to discover information and allows users to focus on scholarly content.
AI-powered bibliography databases: We’re all familiar with scholarly databases like Scopus and Dimensions, which we described in our last post, but they’ve now integrated GenAI into their platforms. AI-powered features include natural language search, concise summaries, and synthesis of research based on a huge database of trusted content.
Scopus AI was built using a combination of Elsevier’s own LLM technologies along with other LLMs, including the GPT (generative pre-trained transformer) developed by OpenAI for ChatGPT. It has the ability to use keywords from research abstracts to generate concept maps for each query. Dimensions Assistant offers well-structured explanations that help researchers go deeper into evidence drawn from publication data, clinical trials, patents, and grant information. It can search licensed literature in a secure way, and researchers can receive notifications each time content is generated based on data in Dimensions, with references and citation details.
Commercial and research facing discovery tools: These include Elicit, Scite, SciSpace, and Consensus. Elicit has two great features to aid researchers – firstly, a customized data extraction where users can specify what sort of information they’re seeking. The tool then adds a column in the results page summarizing the information the user is seeking in preview/comparison criteria for the results of the main prompt. Additionally, its ‘List of Concepts’ feature is designed to give users a summary of the main concepts and topics covered in the research literature that Elicit has identified as relevant to the user’s query. It allows researchers to get a high-level understanding of the conceptual landscape in a particular research area.
Scite’s main strength is in reference discovery and identifying supporting and contradictory references. It supports three alert mechanisms – newly detected citations statements matching the search query, new citations statements referencing papers from the results of the search query, and newly published papers matching the search query.
SciSpace has a functionality called Copilot that works as a research assistant and is available across over 200 million research papers in the SciSpace repository. The AI research assistant can explain papers and answer user queries, providing additional context and clarity. And Consensus is designed to answer scientific research questions, leveraging GPT4 and other LLMs to summarize results. Many of these tools have been connected with ChatGPT as GPT plug-ins.
All of the applications mentioned above provide synthesized answers, including references (usually around 4-6 references are included in the answers), and LLMs are used to analyze the abstract, unless the tool has access to the full text. And prompt suggestions or keyword prompt prediction is supported for most of the tools.
Each of these tools leverage AI to provide a personalized user experience that meets the needs of researchers. Users can add columns as prompts to the displayed results, letting them dive deeper into those results and get the knowledge they’re seeking. They can also upload content and use AI as a research assistant to better understand that content. This personalized discovery experience means researchers can extract knowledge and information tailored to their specific needs.
So what do these GenAI-powered search tools have in common?
Returning answers, not results
Enabling natural language search can enhance the discoverability of content. Users can not only find relevant articles, research, or information, but also exact answers to their questions even when they’re not familiar with precise terminology or keywords. Additionally, users can ask questions in different languages, making content more accessible to a wider audience. By enabling discovery from multiple publishers, both publishers and researchers benefit; researchers can quickly get the information they need without having to search across different platforms, and publishers can increase dissemination of their content. Natural language Q&A means users can search for specific questions, rather than having to scroll through a long list of results to find answers.
Improved customer experience
Conversational discovery creates a more user-friendly experience – essentially, it’ll look like talking to a person. That ‘person’ will be able to understand our questions and intentions, memorize previous information, and provide answers in the preferred format. In a process called flipped interaction, they’ll also suggest related or follow-up questions to help refine users thought processes and get to what is actually needed. Answers will be provided with evidence and will be given not only in text format, but in rich format such as links, images, audio, and videos. Since people are used to asking questions in everyday language, any system that can respond to these natural language queries will likely boost user engagement and satisfaction.
Better content engagement and SEO
Better content discoverability can lead to increased views and engagement, potentially benefiting monetization efforts through ad impressions, subscription models, or other revenue streams. Beside direct SEO optimization using GenAI, enhancing the search experience can also indirectly improve a platform’s SEO — when users find what they’re looking for more easily, they’re more likely to share and link to that content, boosting search engine rankings. And with this type of search able to provide insights into user preferences (based on the questions they ask and the topics they’re interested in), it’ll help guide content and audience strategy.
Pain points for researchers and publishers
Journal suggestion is an important and popular use case for using GenAI. ChatGPT, MS Bing, and Google Gemini can be used to suggest relevant journals for a research paper, and Gemini can also give relevance scores and explain their calculations. However, when we experimented with these tools for this purpose, they tended to recommend only related top-tier journals (perhaps because these top journals appear more often in their training data which has created a bias).
We know that finding relevant – and available – reviewers is a known pain point in the publishing process. In most cases, publishers must rely on editors or authors to find qualified reviewers. We took an article title and abstract and asked MS Bing and Google Gemini to suggest relevant reviewers for that paper. Neither tool performed well in this experiment; Bing often suggested a list of researchers who were co-authors from a relevant publication, while ChatGPT and Gemini suggested non-existent reviewers.
Our experiments show that GenAI still has some way to go in solving some of the biggest pain points in the publication process. Dedicated journal and reviewer suggestion services are trained on dedicated data and usually outperform generic GenAI applications and provide detailed results.
Next, we’d like to touch on the evolution of discovery solutions and methodologies through AI involvement.
We’ve seen the way we search for information online change significantly over the years. Traditionally, a search engine would use keyword search and Boolean operators based on predefined rules with an inverted index (a data structure that maps content terms to the documents or locations where they occur) to match your query to content. But with so much information out there, and ever more complicated queries, a need for more relevant and scalable search systems led to the development of neural semantic search. This uses natural language processing to understand the semantic meaning of content and queries to handle more complex requests, while improving over time with user feedback.
The Retrieval Augmented Generation (RAG) framework integrates externally updated knowledge with large language models to generate one answer from different relevant information in a more cost-effective way compared to fine-tuning LLMs directly. AI agents are becoming more popular since they can represent systems to perceive, decide, and act autonomously to achieve specific discovery goals. We believe that search and results generation will converge in the future as GenAI becomes fast and cheap to train with the latest knowledge, while able to memorize and understand larger volumes of information as input ( two million tokens/around 1.5 million words, equivalent to around ten average books currently). This will lead to more accurate and contextually appropriate responses. So, users won’t search for results or answers — rather, AI will generate personalized answers in rich formats on demand.
And as search solutions have evolved, so have methodologies. Original information discovery systems aim to find and collect information from various sources, returning results based on the accuracy and frequency of the keyword in a body of content. And while this method is still used, it has limitations in handling complex queries.
Methodology advanced to imitate user understanding, but without fully reaching a human level of interpretation. The process involved extracting and enriching the content and its metadata to improve quality. The methodology then evolved to explainable and contextualized discovery by understanding and organizing that information into a coherent, consistent, and structured knowledge base. It provides more comprehensive and value-added information representation (such as key concepts, events, relations between entities, and hidden knowledge).
The ultimate goal of discovery is not to find information but to apply information to achieve our business or task objectives. We’re moving from procedure-oriented discovery (focusing on executing each task during information discovery) to objective-oriented discovery, which focuses on defining clear goals and automating intermediary tasks, just like the cool multistep reasoning capability released by Google search recently.
However, there are risks and limitations involved…
So far, we’ve seen how GenAI can help publishers and researchers in information discovery, but we also need to recognize its risks and limitations during the journey. During content and answer generation, insufficient or flawed training data or encoding issues can lead to nonsensical or false information – also known as hallucination or repetitive and irrelevant information. There are also ownership disputes over AI-generated content, with a need for current copyright law to be further developed to meet needs in the era of GenAI. Lack of explanation of AI output further reduces human trust in AI during dissemination. There’s also the risk of AI discovering more biased information, with personalized content creating an ‘information cocoon’. When AI-generated content is applied, or when content is used for AI, data privacy and security issues arise as personal data is collected, or when users mistakenly share confidential information with the AI. The misuse of unlicensed training data has already raised significant legal and ethical concerns.
So what might all this mean for information discovery in the future?
AI presents a new generation of computers and operating systems, with a potentially immense ecosystem. There are two types of AI/GenAI powered discovery systems: AI+ refers to native applications which can only be built based on GenAI (such as Chat GPT and Perplexity.ai), while +AI means AI/GenAI can be integrated to improve existing discovery tools and search engines such as Google and Bing. We can expect to see new novel discovery systems appearing in the near future.
Real multimedia content discovery is becoming more popular. Currently, most multimedia content search is still based on text extracted from images and videos. As AI moves towards multimodality, in which it is able to understand, generate, and interact with multimedia content, people can search images and videos based on the semantic meaning of scenes in images and videos and even with voice. For example, OpenAI’s recently released GPT-4o can notably process and understand inputs and outputs across different formats such as text, code, voice, audio, and images in near real time.
Essentially, as GenAI powered discovery becomes more popular and sophisticated, we believe that everyone will have a personal AI assistant. What does this mean for researchers? They’ll be able to discover, memorize, and apply information and knowledge more effectively. They’ll get broader, deeper, faster, and more tailored insights. And it’ll help them better analyze, plan, and execute their work, leading to more efficient – and faster – research outcomes.
Most information discovery solutions are based on the RAG pipeline now. Although RAG can reduce hallucination and allow users to discover updated information in a more secure and cost-effective way (compared to fine-tuning LLMs), there is still a lack of explainability, coverage, and answer navigation. There is a trend to combine RAG with knowledge graphs, which organize data in interconnected, semantic relationships. The new system can deliver even more precise and comprehensive insights. For researchers, this means a significant improvement in information discovery capabilities, enabling more accurate and explainable retrieval and analysis – crucial for advancing academic and scientific inquiry.
In the age of AI, we need to reconsider business objectives and any new business models. For instance, GenAI has the potential to decrease traffic and click-through rates, challenging the core business model of companies like Google. This is one of reasons why Google hasn’t been one of the earliest players in GenAI, although they had the capabilities to do so before OpenAI. We may see search engine vendors shifting their goals from returning relevant results with relevant ads, to providing accurate answers without ads, just like YouTube and Perplexity.ai are doing. Moreover, publishers are evolving from content providers to knowledge providers by selling high-value added knowledge instead of just articles and books. It’s possible that publishers will create their own domain-specific knowledge base and provide paid knowledge discovery services to answer researchers’ questions, charging on-demand and leveraging GenAI, LLMs, and their curated knowledge bases.
And finally, humans interact with machines at a high level using cognitive abilities like sight, touch, hearing, voice, and spatial awareness, all of which are part of our daily lives. This shift is particularly beneficial for individuals with disabilities, as it enhances basic cognitive interactions and improves knowledge discovery. And we could also see AI-powered metaverse libraries which can curate vast collections of resources in the future. Researchers could explore, interact with, and access information in immersive and engaging ways. It’s an exciting prospect, and we’re looking forward to seeing where artificial intelligence takes us next!

Discussion
1 Thought on "Towards Conversational Discovery: New Discovery Applications for Scholarly Information in the Era of Generative Artificial Intelligence"
Hong Zhou, nice analysis & read.
We will see Google emerge in the AI+ field with their “Generative AI in Search” product which will soon be launched https://blog.google/products/search/generative-ai-google-search-may-2024/
The world of AI search is very buoyant with lots of new players to the market space a number of which you mention in this article.
I can also see that with a few smartly worded “prompts” that you can get a long way to turn a +AI like Microsoft Copilot into a specific AI+ tool to replicate what some AI web search tools are offering. All with Microsoft commercial data protection and privacy built in.



