Editor’s Note: Today’s post is by Hema Thakur. With over a decade of experience training academic researchers and editors, Hema has supported authors in publishing across major scholarly platforms. Her work has appeared in outlets such as The Scholarly Kitchen, Springer Nature Communities, SAGE’s Social Science Space, Disability Horizons, and the European Association of Science Editors blog, alongside other international platforms.
Simplifying language for people with cognitive disabilities isn’t just a stylistic or compliance exercise; it’s a design decision with ethical and cognitive implications. This is especially true when using generative AI to adapt complex material for users. In particular, it can be challenging to process and interpret peer reviewer feedback without support, given its dense, technical, and context-specific nature. But what happens when the simplifying tool distorts meaning in the process?
My recent research explored this question through a targeted experiment on the use of AI to improve the accessibility of peer review feedback. What I learned is important for every member of the scholarly communications and publishing community.
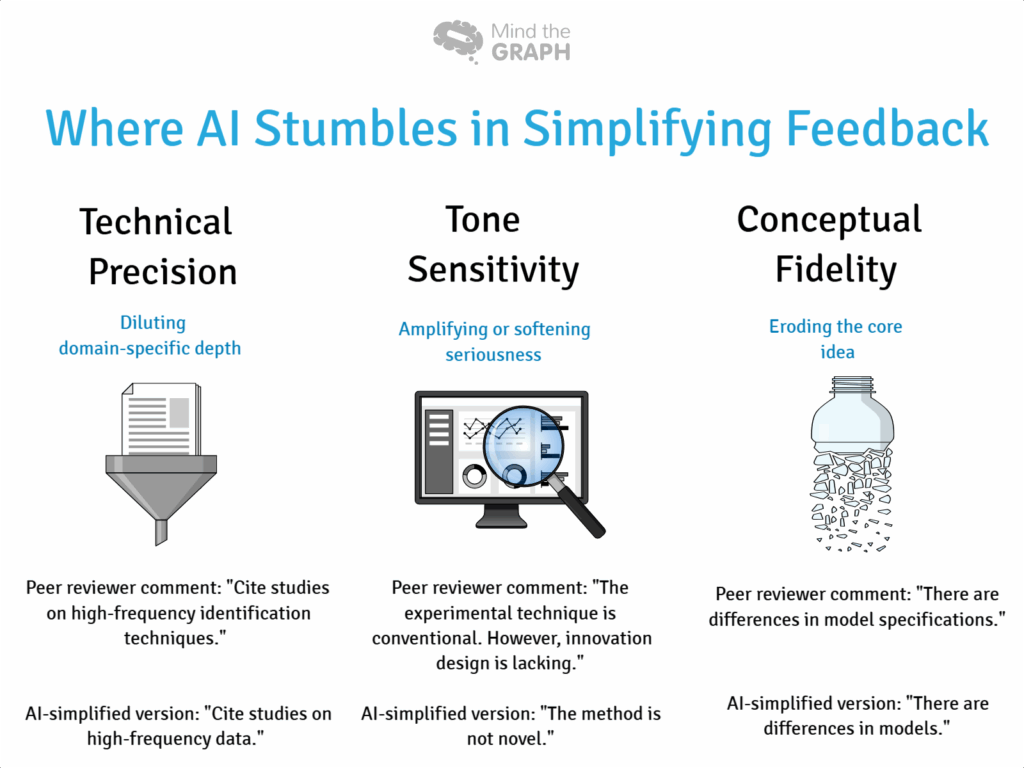
I evaluated GPT-4’s ability to simplify peer reviewer feedback in the academic field of finance. This domain was chosen not only for its highly technical language but also because its concepts, such as causality, risk modeling, or endogeneity, are closely tied to specific analytical methods. In such contexts, even small shifts in wording can distort connotations or undermine a reviewer’s intent. With a background in finance myself, I saw this as an ideal test case for examining whether AI can simplify with both clarity and conceptual integrity. I’d encourage researchers in other subject areas to run similar experiments within their own fields, where the stakes and semantics may differ, but the accessibility challenges remain just as urgent. To ensure complete transparency and reproducibility, I have shared transcripts of my conversations with GPT in my paper.
By prompting the model to rewrite feedback — once using a general plain-language prompt and once referencing cognitive accessibility needs — I examined how well it could preserve core meaning while improving readability. I selected ten technically dense reviewer comments and ran each prompt scenario twice, allowing me to assess not only the quality of simplification but also the model’s consistency across outputs.
I found that the model often missed the mark, not due to lack of clarity but due to loss of meaning. GPT-generated simplifications frequently altered the interpretation of technical language, glossed over methodological nuance, and introduced semantic inconsistencies across outputs. This raises critical concerns about the reliability of AI tools in accessibility contexts, especially when the goal is not just comprehension but equitable participation in scholarly discourse. What I found should concern anyone who disseminates content with both accuracy and inclusion in mind.
Take, for example, a reviewer’s comment about using a difference-in-differences approach to explain the timing and magnitude of market reactions to central bank announcements. The original text alluded to causal inference, a core concept in econometrics. GPT-4’s simplification turned this into a line about “how fast and how strongly the market reacts” rather than why markets react that way. That rephrasing softened the point from a methodological recommendation to a vague observation, effectively stripping away the purpose of using the technique in the first place.
In another case, the model described “endogeneity” as “hidden effects.” While this sounds more accessible on the surface, it dangerously dilutes the technical specificity of the term. Endogeneity is not just about things we can’t see — it refers to situations where explanatory variables are statistically compromised, often requiring advanced modeling strategies to correct. A more accurate definition would be “When something in your model affects both the cause and the outcome, making it hard to tell what’s really driving the results.” Oversimplifying it can lead a reader to overlook critical flaws in their research design. For instance, imagine a paper studying the effect of education on income. If the author interprets endogeneity as just “hidden effects,” they may focus only on missing data or measurement errors — things that are literally “hidden” — and might ignore the fact that factors like innate ability or family background influence both education and income, biasing the results.
The model also faltered with conceptual language. It simplified “bounded rationality” as “limited thinking ability” — a phrase that not only misrepresents the concept, but risks sounding offensive. Bounded rationality refers to decision-making under constraints like incomplete information or time pressure, not an inherent cognitive deficit. In content design for accessibility, we’re taught to center dignity and precision; GPT-4 failed on both counts here.
Even visual accessibility suffered in some outputs. For example, a reviewer’s concern about the illegibility of figure legends in a regression plot was simplified into a comment about “labels being hard to read.” While factually correct, this rewording dropped the context of why the legends mattered — namely, their role in interpreting group-wise effects in income data. For users depending on simplified content, this loss of purpose is no small matter.
Across multiple runs, GPT-4’s inconsistencies added to the problem. In one version, it retained key terms like “sensitivity analysis” but failed to explain them. In another, it replaced them with vague metaphors like “double-checking your methods.” The fluctuation wasn’t just stylistic — it was semantic. Sometimes the message changed entirely depending on how the model interpreted the same comment on a different day.
These results point to a core tension in AI-based content simplification: Efforts to clarify can unintentionally blur the underlying logic of a concept. This tradeoff is not acceptable in accessibility-focused design. When we rewrite for inclusion, we must preserve purpose, not just polish form. Especially in domains like finance, science, or law, the price of a misunderstanding isn’t confusion or flawed wording — it’s misdirection or flawed modeling of meaning.
Large language models like GPT-4 don’t “understand” the intent or function of a comment the way a human reviewer might; they predict likely phrasings based on statistical patterns in language. As a result, they often miss the why behind a piece of feedback, especially in content where accuracy and reasoning are the message itself. This makes them ill-suited, in their current form, to adapt content that demands both clarity and conceptual rigor. In accessibility contexts, where simplification must be done with care and respect for user autonomy, these failures are systemic rather than incidental. And they point to a need for more deliberate design in how we use AI for inclusive communication.
So, what can publishers, software developers, and AI practitioners take from this? First, prompt design is not a substitute for domain knowledge. Even accessibility-aware prompts failed to consistently guide GPT-4 toward better simplification. Second, verification matters. Each AI-generated simplification should be reviewed for technical fidelity and cognitive respect. And third, we need better alignment between LLM training and accessibility goals—not just in language style, but in conceptual accountability.
Designing for inclusion means more than making things easier to read. It means ensuring people receive the intended message rather than just a readable one. Since we have seen that GPT-4, in its current form, isn’t there yet, here are a few ways we might begin to develop tools that respect both meaning and accessibility.
One path forward is to develop AI tools fine-tuned to domain-specific academic content — such as models trained on preprints, peer reviews, and methodological appendices — so that simplification retains conceptual fidelity, not just surface clarity. Early-stage use could also include feedback loops: rather than expecting ongoing human verification, tools can learn from initial rounds of correction by editors or accessibility experts, improving their semantic accuracy over time.
Additionally, interface-level innovations — such as allowing reviewers or editors to label the purpose of a comment (for example, whether it relates to methods, structure, or language) — can help AI understand why a piece of feedback was written. This added context can guide the model to simplify more intelligently, preserving the intent behind the comment rather than just rewriting the words.
If we want accessibility to mean equity — not erasure — then these are the initiatives that every content strategist, accessibility advocate, and AI developer should take seriously.

Discussion
2 Thoughts on "Guest Post — The Accessibility Illusion: When AI Simplification Fails the Users With Cognitive Disabilities"
An interesting post, and I appreciate the nuances of your concerns, but would counter that the AI is doing exactly what you requested, simplifying the message.
Frequently when text is summarized details are lost. That is the whole point of the process. Consider “I was late to school because the battery in my phone did not charge and the alarm never sounded. I rushed but missed my train by three minutes and the next one comes an hour later…” could be simplified to “I overslept and missed the train” or even “I was late to school”.
I appreciate that the AI translation lost some significant details, possibly enough to make the comments useless or even dangerous, by reversing the meaning…. (I could feel the classic causation vs correlation surfacing…)
But I would ask why you want to use an AI to summarize reviewer comments which by their very nature need to retain a high level of detail. The editor should have sufficient knowledge to parse their meaning as well as the original paper’s content, and if not, simply ask the author to respond and if needed go back to the reviewer for explanation. This is a crucial point where that conversation really needs to occur.
A similar risk occurs when text is translated…
Thank you so much for engaging so thoughtfully with the piece — I truly appreciate your nuanced take.
You’re absolutely right that summarization inevitably involves some degree of loss, and your example captures that tradeoff well. In fact, I agree that AI did exactly what it was prompted to do — the issue arises when that simplification unintentionally shifts the intent or integrity of technical feedback, particularly in high-stakes contexts like scholarly peer review.
My aim wasn’t to suggest that all detail must be preserved verbatim, but rather to highlight that in certain domains, like econometrics or finance, the type of detail lost can have disproportionate consequences. For example, simplifying “endogeneity” as “hidden effects” might seem like a fair generalization, but it erases the underlying statistical implication — and for a researcher with a cognitive disability, that can mean misinterpreting a foundational flaw in their methodology.
As you rightly pointed out, the editor (or a trained intermediary) plays a crucial role in interpreting and facilitating that conversation. My research focused on accessibility specifically for users who may not yet have that level of technical fluency — including early-career researchers or scholars with cognitive disabilities. The idea was to test whether AI could support that access journey, not replace human judgment. But you’re spot on that the simplification step alone is not a substitute for dialogue or contextual understanding.
I love your point about translation as well — that’s a perfect parallel. It’s not just about converting language, but preserving meaning, tone, and nuance. That’s exactly the tension I was hoping to surface here.
Thanks again for reading and for such a thoughtful reflection!


