An analysis of article downloads from 2,812 academic and professional journals published by 13 presses in the sciences, social sciences, and humanities reveals extensive usage of articles years after publication.
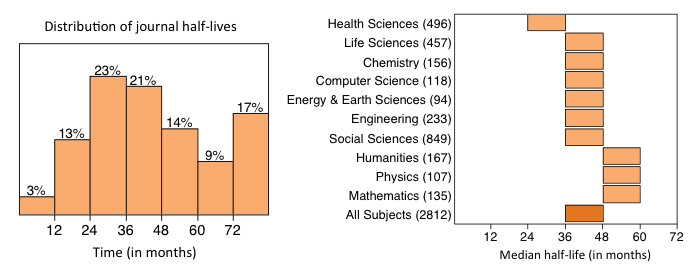
Measuring usage half-life–the median age of articles downloaded from a publisher’s website–just 3% of journals had half-lives shorter than 12 months. Nearly 17% of all journals had usage half-lives exceeding six years.
While journal usage half-lives were typically shorter for journals in the Health Sciences (median half-life: 25-36 months), they were considerably longer for journals in the Humanities, Physics and Mathematics (median half-life: 49-60 months). Overall, the median half-live for all journals was three to four years.
The study involves a variety of non-profit society, association, university and commercial publishers operating under a diversity of business and access models. Analyzed by ten major subject classifications, the study illustrates substantial variation in the usage half-lives of journals both within and across subject disciplines.
As the author of the study, it is my hope that evidence-based studies such as this will help to inform those developing public policy and may aid in setting access embargoes.
The study, “Journal Usage Half-Lives,” is openly available from The Association of American Publishers website.

Discussion
22 Thoughts on "What is the Lifespan of a Research Article?"
Phil,
This is very helpful for assessing how and when information is accessed in different fields. Have you thought about engaging EBSCO Publishing and ProQuest as well? Many users, especially students, access social science and humanities articles this way as opposed to going to the publishers website.
Bob Rooney
Great question, Rob. There are many sources of access to the scholarly literature. This study measures usage from just the publishers’ end. One might surmise that aggregator services (like ProQuest and Project MUSE) and archival services (like JSTOR) would draw the half-life out a little further.
JSTOR would draw the half-life out a *lot* further for the humanities. Many humanities journals have a “moving wall” of five years before archived articles in JSTOR can be publicly accessed; many humanities researchers use *very, very* old articles in JSTOR. The median of 48–60 months is probably simply an artefact of confining the search to publishers’ own sites.
Are there any studies on whether/to what extent usage influences citation rates?
There are a number of studies, going back to 2004 that show a moderately weak relationship between early usage (as measured by downloads) and citations. If you are wondering if increased access influences citations, a rigorous randomized controlled trial of OA publishing shows no effect on future citations, although it does appear to increase downloads (see: http://dx.doi.org/10.1096/fj.11-183988)
Thanks, Phil! What might be interesting – if it hasn’t already been done – is a long-term study tracking the citation rates of articles in your same sample of humanities journals whose usage half-lives are, say, 3-5 years, irrespective of the journals’ business model.
Thomson Reuters reports citation half-lives each year in their Journal Citation Report. For many journals in the humanities, citation half-lives are greater than 10 years.
Any idea how the usage half-life for a journal correlates to its cited half-life?
One would imagine a positive correlation, with citation half-life being much longer than usage half-life. But, I haven’t done the analysis.
Excellent report and it certainly mirrors what we see with usage. There is no “one size fits all” with embargo periods and using medical as the baseline is just wrong.
Agree that using medical as a baseline isn’t appropriate, but what this important study shows is that we really had no evidence-based baseline to begin with. It was a guess, a hunch, and it was wrong.
There is also the concept of “half-life” which we shouldn’t skip over. If a publisher is meant to survive mostly on purveying content on behalf of others (and assuming the risks inherent in that), then even embracing the concept of half-life is risky. Imagine if any other business were asked to give up half of its viable product in order to meet a government or funder mandate.
Publishers used to be able to get the “whole-life” value out of the content they published. Even if embargoes were lengthened to embrace what this evidence shows are more accurate, domain-specific half-lives, it’s still half.
Good point Kent. I am working on an adverse economic impact model for embargoes that is based on this very concept.
“Measuring usage half-life—the median age of articles downloaded from a publisher’s website [..]” may not be a very solid method (if I understand it correctly, you did not limit to a fix time frame for each article?). The older a journal is, the more articles are available from previous years (articles older than 12 months) relative to the number of articles available for download from the last 12 months. It would be better to look at the number of downloads of each paper within the first six years after publication and calculate the median for that distribution?
Half-life is a construct that needs to be properly operationalized for the publishing environment. In calculating the half-life of people, for example, we have a fixed limit on age (about 120 years or so). If we observe a cohort of people born before 1890 (and assume that all of them are dead), calculate their age at death, we can arrive at the half-life of that cohort of people.
This cohort approach, as you mention, can be used to calculate the half-life of articles published within a journal. It is very data intensive, as you can imagine, and assumes that a cohort of articles published in the past (6 or 10 or 20 years ago) follows the same usage profile as a cohort of articles published today. I think few of us would agree with this assumption. The alternative was to take a sample of downloads in a particular period of time and look at the distribution of those article date requests. While the sampling approach has its own limitations–it underestimates the true half-life of an article–it does a better job reflecting how readers are accessing the online scholarly literature today.
p.s. We did exclude new journals, discontinued journals and journals moving from one publisher to another. See “Exclusions” on page 3 of the report.
Phil,
In the paper, you defined “half-life” as “the time taken for a group of articles to reach half of their total number of downloads.” But what I don’t see in the paper is any information about the samples the publishers used — how large they were, the range of years involved, etc. Is there any information about the samples that could help shed light on how robust these samples were?
Also, could you comment on any controls used to reduce what a medical journal might call “interoperator error” — that is, the differences in estimation and sampling approaches between and among journals?
Yes, the report is very “lean” and leaves out quite a number of details that you would find in a full scientific paper. Many of the larger publishers used one month of usage data, taken in 2013. Some of the smaller publishers created their datasets on 3 months of data or an entire year of data. Because of the various publishing systems employed and abilities of these systems to generate the datasets, I was accepting of variations on the extraction protocol. One publisher did a validation study of their own estimates based on different sample sizes and different protocols and got slightly different results. While I don’t emphasize precision in the results (distributions are reported in bins of 12 months), I do feel that the main results are generally robust. Different publishers on different platforms publishing journals in different disciplines using different business models are going to necessarily get different results. On page 5, I do address the limitations of the study, including the issue of estimates derived from samples:
Estimates derived from sample data. The method for calculating journal usage half-life assumes that a sample of download data is representative of all article downloads from that publisher. Large samples of download data are likely to produce more accurate estimates than smaller samples. Similarly, smaller, low-usage journals may be prone to more variable download patterns than larger, high-usage journals. While individual journal half-life estimates are associated with some degree of error, taken together, they provide a central tendency of usage across various subject disciplines.
Thanks. That’s helpful. It’s an important study. Congratulations!


