Editor’s Note: Today’s post is by Joseph DeBruin. Joseph is the Head of Product Management at ResearchGate, where he applies the scientific training he learned as a neuroscientist at Johns Hopkins toward building products for ResearchGate’s network of users. He was formerly Head of Growth at Feastly, which was acquired by ChefsFeed in 2018.
“Always design a thing by considering it in its next larger context – a chair in a room, a room in a house, a house in an environment, an environment in a city plan.”
– Eliel Saarinen – Finnish/American architect
The world has gotten pretty opinionated about how scientific communication should be designed, and most of what has been published has fallen into one of two camps:
- Camp A) The Covid crisis has torn down the walls of science and cranked the speed dial to 12. Instead of traditional journal publishing which takes months, preprints are exploding, “a global collaboration unlike any in history” is happening in real-time, and an old system is finally getting the overhaul it needed!
- Camp B) We are seeing the first true social “infodemic.” Misinformation is everywhere, most of what is out there “isn’t even science,” and governments are cracking down on social media platforms and scientific publishers to dramatically limit the content that makes it online.
Both of these camps are at least partially correct, but few articles address the fact that speed and uncertainty in science are often two sides of the same coin, and getting the benefit of speed without the risk of uncertainty is extremely challenging. To be sure, focusing as a journalist entirely on the benefit of speed or the damage of misinformation likely reflects a desire to keep an article clean and to the point. Nonetheless it’s important to note that peer review with sequential disclosure, the system that has historically mitigated risk from uncertainty, is exactly the system that is being upended in order to increase the speed of innovation. So although it’s complex, we owe it to science to dig in this rocky middle ground, and to ask the question of how new technologies and insights can allow us to maintain the benefit of established truth-seeking systems while continuing to push the boundaries of speed.
Spheres of relevance
Scientific communication is a many-layered onion, to put it mildly. Knowledge creation starts in an extremely tight unit such as a lab which, like your immediate family, speaks its own language given how much shared history and common knowledge it has built over time. There are often very few other labs in the world who might have use for the truly “raw” output of a given lab. Then as you move outward, there are scientific disciplines, sub-disciplines, related disciplines, and on and on to cover the millions of scientists in the world. To make it more complicated, within each of these groups you can find senior scientists who have 40 years of experience interpreting scientific output and new scientists who are still in their first year of training. And then there’s the wider public including policy experts, journalists, and interested lay-people of all kinds. As the knowledge created in that first lab moves and travels, it needs to change in certainty and in style. Those other 10 labs might want raw data as soon as it is recorded, while the broader discipline isn’t interested until it’s been verified and can safely change the current assumptions of the field. The wider public needs something different entirely, namely a view of how this science can change their lives, and that requires a great deal of translation, context, and safeguards from the layers within. As a simple version, let’s say it looks something like this:
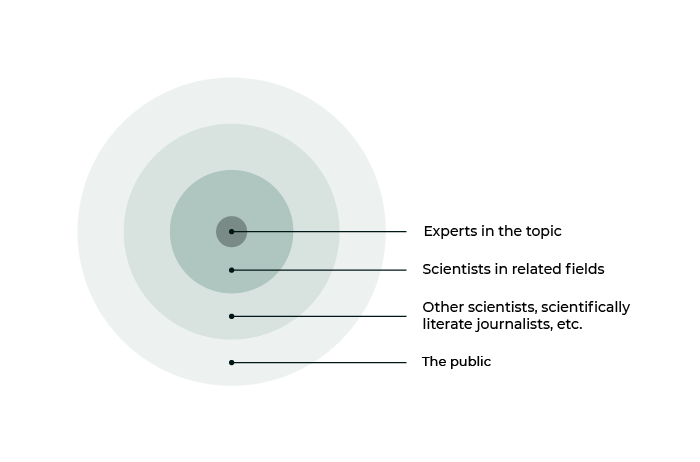
It’s worth noting that this is not even close to the right scale. If it were, it would look something more like this, where the scientists in relevant fields and experts in the topic are so small as to be invisible:
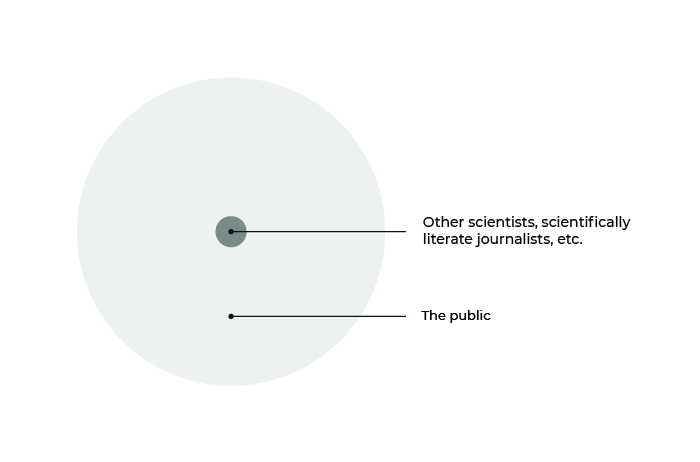
The point to be made here is that communication within science is a series of complex steps outward, and even so, it reflects only a small fraction of the flow outward to the most distant layers of public awareness. Armed with this mental model, we can look at how information has flown through the spheres in a few specific cases within the Covid crisis.
Case studies of misinformation/innovation in Covid
The Ibuprofen rumor
How it happened:
- March 11: Researchers in Switzerland publish a letter to The Lancet observing that in 3 small case studies in China, a high proportion of severe cases also had high blood pressure and/or diabetes. Because Ibuprofen is a common treatment for these issues, it was suggested as a potential risk factor. The authors “encourage someone” to conduct a proper study. Worth noting is how misleading scientific language can be to non-scientists: “We suggest that patients with cardiac diseases, hypertension, or diabetes, who are treated with ACE2-increasing drugs, are at higher risk for severe COVID-19 infection.” “We suggest…are” = we hypothesize, but haven’t proven or tested anything.
- March 14: The French Ministry of Health issues a warning that people should not take Ibuprofen. Almost immediately it is picked up by news outlets in the US and elsewhere, and before long the anti-Ibuprofen craze is on.
- March 16: The Lancet researchers react to the misinterpretation of their letter by publishing an update stating that that it was “expressly formulated as a hypothesis” and should not be interpreted to mean anything for patients. Fair to say this update didn’t do much to stop the momentum.
The Wuhan lab conspiracy
How it happened:
- Feb 5: A researcher in China, Botao Xiao, uploads a preprint to ResearchGate pointing out the proximity of a lab in Wuhan that had reportedly studied coronaviruses in the past to the Wuhan meat market. The paper suggested a causal relationship between studies in the lab and the crisis, but provided no experimental evidence whatsoever.
- Feb 5-15: Several sites pick up the preprint as evidence that China has been covering up the origin of the virus or even intentionally created it. On Feb 15, Xiao removed the preprint from ResearchGate and deleted his account. Later he told The Wall Street Journal (paywall) that he removed it because it “was not supported by direct proofs.”
- Feb 15-current: despite the fact that no material proof has emerged to support this claim, it is still being cited by many influential people as evidence of malicious intent from China. Tucker Carlson of Fox News cites it as a “draft paper” which is “now covered up” and as specific evidence that he is not creating conspiracies but citing “real science.” This claim, as with Xiao’s, appears to also be without direct proof of any kind.
Characterizing the novel virus
How it happened:
- Jan 23: Researchers in Wuhan share a preprint on bioRxiv (one of the major preprint servers) characterizing the outbreak and (among other things) describing the similarity in structure to SARS-CoV and to bat coronavirus
- Jan 23-Feb 03: The preprint is instantly taken up by researchers across the world. To date it has over 250,000 downloads on bioRxiv. Within days it was cited by several other studies, mostly preprints. The preprint alone has almost 100 citations. It was also covered by a wide host of news outlets.
- Feb 03: The preprint was formally published in Nature. It now has almost 1000 citations from scientists around the globe.
A couple of things are worth noting in the above examples, which represent how a similar mechanism can be both innovative and potentially dangerous. First, you see how fast the information travels from the inner core of scientists to the wider circles. Second, it’s clear that as we drive more visibility on earlier stage research it means we not only publish results with huge amounts of experimental validation but also hypotheses and ideas based on few observations. Researchers have always known this early idea-building work to be essential to the advance of science (hence the push towards more and faster visibility!) but the public often doesn’t think of this as any different from any other type of “science” which means it can be interpreted as more certain than it really is.
Last, it’s clear that in none of these cases did it travel in linear/sequential fashion from inner circle to increasingly wider groups; because the information is public from the start, it travels from the inner core of scientists to other relevant scientists who can advance the work while simultaneously making the leap to news outlets and “citizen scientists” on Twitter who are ill-equipped to handle the inherent rawness and uncertainty of a preprint. As Richard Sever, co-founder of bioRxiv, said in a recent webinar, “preprints are intended for experts.”
Temporary problem or lasting shift?
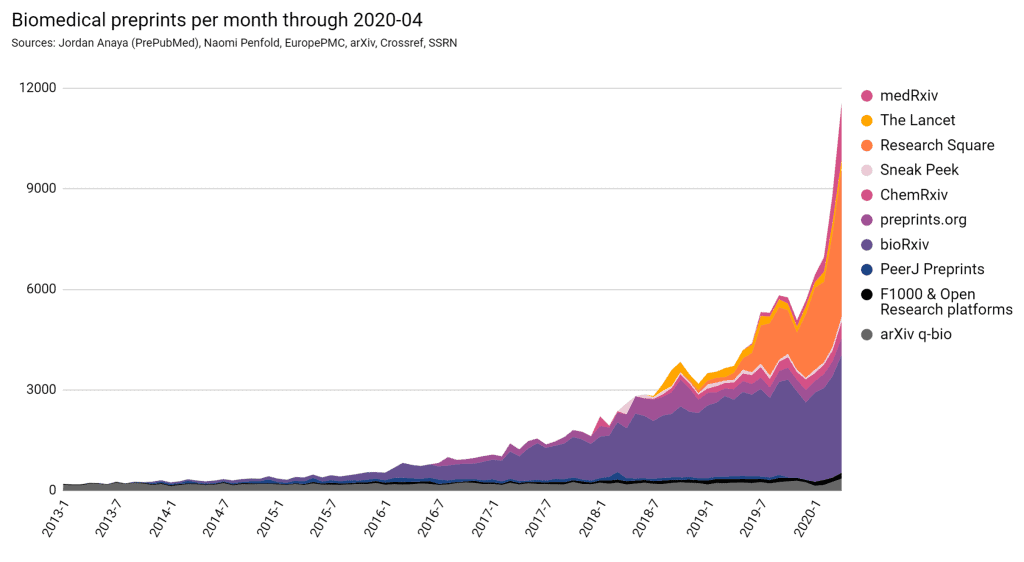
A major open question at the moment is how much of what we’re seeing now is unique to this crisis versus where Covid has catalyzed a lasting change in how science operates. To be sure, the attention of the entire public sphere on science is temporary: I think we can all expect the quantity of scientific articles our uncle John, the lawyer, sends us will decrease after the current crisis is behind us. But faster sharing of early-stage (read: more raw) research and increased openness have been two of the major topics in scientific communication for years. Just look at the growth of preprints since 2013.
Facilitating better information travel via technology
The point I’ve tried to make so far in this article is that speed and uncertainty in science are two sides of the same coin, and that the trends we see in Covid are indicative of a lasting shift rather than a temporary blip. Nonetheless, there are big steps forward we can take towards mitigating the risk associated with limited validation while maintaining speed, especially with the help of modern technologies.
It seems obvious, but one of the biggest things that can be done to reduce the risk of misinformation is to surface high-quality research. Researchers in the UK modeling information spread in crises found that simply changing the ratio of quality information to misinformation read by a population, or “immunizing” a small percentage (20%) of the population to misinformation dramatically reduced the health risk.
Promoting high-quality early-stage research is by no means a trivial effort. Journals have historically been relied on to curate scientific output, and so before a publication makes it to a journal (or if it never does) there are few existing mechanisms that can mimic the human effort needed to ensure that it isn’t simply the splashiest articles that rise to the top. Especially in the early stages of research, new platforms for science will need to put researchers at the center and allow them to gain or lose trust and influence over time, just as journals have. It will be critical to establish the right structures so that experienced researchers are rewarded for the knowledge they curate as well as the knowledge they create. There’s a lot to be learned (both bad and good) from platforms like Twitter in terms of how to establish the trustworthiness and prestige of individuals and allow them to gain influence in content curation. We’ve been working on this for years at my own company, ResearchGate, and are trialing new user curation mechanisms within our Covid Community, but it’s a major shift for science and something that we believe will take time and cooperation with publishers to ensure that the new systems also strengthen the existing ones.
In addition to promoting the best research, it’s clear that we have to minimize and mitigate the times when people consume low-quality or potentially misleading research. One strategy to “immunize” is what we’re seeing with services like bioRxiv or ResearchGate where a clear warning is placed on top of any content that is potentially more uncertain (such as preprints) due to the lack of peer review. Another is working to establish flows within preprints to keep that content from ever appearing in the first place. Major preprint servers have dramatically increased their moderator mechanisms, where researchers approve all content before it gets added. As a user content platform, ResearchGate does itself not directly assess content or pre-approve content, but has set up user driven mechanisms designed to include relevant content in the COVID 19 area, and encourage helpful user commentary on specific works.
Nonetheless if we look back at the examples above, it’s clear that sometimes the problem isn’t that the information is false or malicious, but simply lacking the right context for certain audiences. This isn’t elegantly handled by the binary yes/no of a moderator system, not to mention the fact that scaling moderator systems faces many of the challenges of the peer review system that is such a burden on journals; it’s difficult to find enough researchers to do the work and even more difficult to find ways to properly celebrate the work these researchers do behind the scenes. Moderators can and should flag possible pseudoscience, but we can also explore ways to selectively expose information to the right audiences so that it gathers necessary context as it travels to outer layers. And when content changes (for example, when it moves to a journal and goes through peer review) we should explore mechanisms to make sure that everyone who read the previous versions gets notified of any changes. Establishing these spheres and notification loops for different context triggers within a platform is challenging, but we believe something worth doing.
Science seeks truth
This is a truly challenging topic, for science and for the internet in general. What should give us hope that science can succeed in ways others haven’t is that science has truth seeking built into its DNA at every level. Something doesn’t “become science” only when it “has a sample size of more than 1000 people” (as some would suggest)” or when it goes through a randomized double-blind clinical trial. A hypothesis based on observation, as we have seen in Covid preprints, is no more or less science than a physical law like gravity that has been tested and validated experimentally for centuries. That doesn’t mean we can treat these the same way as they travel along the path of knowledge towards truth. Many of the old systems that have slowed down the pace of science in order to establish relevancy and truth-seeking as it builds from observation to intervention shouldn’t be thrown away in the move towards speed, but rather built into and strengthened via new technologies.
Discussion
8 Thoughts on "Guest Post — The Covid Infodemic and the Future of the Communication of Science"
When seeking “right structures” and “new systems” and saluting peer review as a “system that has historically mitigated risk from uncertainty,” we should surely be trying to make the task of peer reviewers easier. This task involves reading a paper and checking the references, which is more burdensome. The first step is the check the abstract in PubMed. That may be enough. The second step is to check what post-publication peer-reviewers have said about a reference. This was a few clicks away with PubMed Commons (now defunct), but is much more difficult with PubPeer. That may enough. The final step, if necessary, is to read the cited reference.
If agreeing that “scientists in relevant fields and experts in the topic are so small as to be invisible,” then editors and publishers should be bending over backwards to get their help. This means lightening reviewers’ loads to make their tasks easier. It does not mean being “rewarded for the knowledge they curate” (other than the satisfaction of having helped good work get published). Publishers should re-establishing some structure such as PubMed Commons where accredited post-publication reviewers have their say.
So “changing the ratio of quality information to misinformation” means we factor in “experienced researchers are as well as the knowledge they create.” Many highly experienced researchers are below the radar of editors. They reveal themselves with enlightening post-publication reviews that make the task of above-radar reviewers much easier.
In this complicated debate it is important to also focus on how future scientists are trained. With science moving to open ecosystems (with is many potential benefits), it is even more essential that there is great training (and certification?) of how to communicate data, insights and preliminary results. Traditionally there have been a high reliance on the apprentice model and thus the quality of the advisors. This can lead to high variability in the level of training new scientists have in how to communicate results. Some advisores are good in facilitating the development of new scientists others write up the results on behalf of the group and don’t allow apprenticies their own experience in writing papers. As a non-native English speaker the most practical course I ever took, was a summerclass in how to write scientific English. It seems to me that there is an opportunity for funders and societies to define standards and develop certification courses for communication of data and preliminary results in a more open science ecosystem.
I think training and education are a hugely under-realized necessity for the move to open science. One of the most common objections to open data is the extra work involved in getting one’s raw data organized enough so someone else can use it. Instead, one should be collecting the data from the get-go with the idea in mind that it is eventually going to be publicly available and that it should be generated and stored in a re-usable manner. This is not something that most research programs offer training in, and open data efforts should/must include opportunities for researchers to learn how to set up their workflows around this idea.
Science has an inbuilt filter that ultimately separates out truth from untruth, the two examples given by Joseph Debruin are an endorsement of this fact.
The speed of information is important, which in the context of COVID has done wonders. The quick sharing of experience in one part of the world has helped clinicians manage patients in a better way in other places. Whether this happened through preprints or quick peer reviews is immaterial.
The moderation during preprint submission takes care of useless pieces of information on most occasions, the open forum for comments also helps reduce misinterpretation, and finally the ultimate consumer who is either a clinician or researchers does have the right mind to see through the truth.
All platforms that help share scientific information are likely to remain integral part of science in the foreseeable futur.
It’s time we recognized that an unreviewed preprint is a fundamentally different type of publication than a peer-reviewed journal article. Writing styles should not confuse the two. Because every significant claim in a preprint is basically hypothetical (i.e. not confirmed by peers), a preprint must include prominent, even obvious, warnings with every claim. Scientists may not need these disclaimers, but the public certainly does. Once accepted by a journal, the disclaimers may no longer be needed and could be removed to make the article more readable.
There’s no preventing stupid, and some will still misinterpret preprints. But we need to do everything possible to avoid untrained people from misunderstanding preprints.
Preprints should include a link to the data, including summaries of data analyses, involved in the research, so readers can fully assess the quality and accuracy of the information provided in the preprint. I note that bioRxiv does not allow authors to post datasets (see https://www.biorxiv.org/about/FAQ – What types of content can be posted on bioRxiv?). I haven’t looked at the policies of other preprint servers. Preprint servers such as bioRxiv should allow, perhaps even mandate, authors to submit links to where their data has been made publicly accessible.
I agree that preprint content should be prominently labelled as such. Journalists and anyone who publishes for the public, who cites or publishes articles highlighting work published in a preprint, should also point out that the research has not yet been peer-reviewed, rather than assume readers will click on a link to the article and then see the disclaimer that it has not yet been peer-reviewed. I have noticed that some journalists, including writers for the New York Times (eg, https://www.nytimes.com/2020/07/02/health/santillana-coronavirus-model-forecast.html?smid=em-share), mentioned that the research has been published as a preprint, but assumes that the public understands what is meant by a preprint or will see the disclaimer when they click on the link to the article. Not everyone will bother to access the preprint itself.
My 20 years of experience as a statistician casts a shadow over several of the claims of the commentators. The difference between good science and shoddy science is that good science uses good study designs, data collection methods, reliable and valid indicators. Then the data are managed well, analyzed appropriately, and interpreted reasonably–neither under-interpreted (a minor sin) or over-interpreted (a mortal sin). All of the important factors that could affect the interpretation of the data should be clearly stated in the paper. This is true for preprints and peer-reviewed articles. So which of these criteria do peer reviewers “confirm”? They can agree with a study design, data collection method, and choice of indicators. They cannot know whether an important factor affecting the study design or its execution and analysis was hidden from view and omitted from the write-up. Nor can they know how the data are managed. Astute reviewers can judge the reasonableness of the interpretation. Most reviewers should be able to judge how well the findings were integrated with the literature to draw conclusions.
I don’t regard peer review or moderation as mechanisms that can ever reliably separate good science from shoddy science if the authors, for whatever reason, present mediocre data in a positive light by selectively omitting findings or their discussion from a write-up. Yet this behavior is still very common and probably will continue to be common.
Commenting on the commentators above from July 8-9, certainly, it is not true that “Science has an inbuilt filter that ultimately separates out truth from untruth.” Much untruth can be hidden in a paper that “needs” to be published because the researchers invested so much time and resources in it that they will do whatever it takes to get it published. I fail to see how checking the cited references makes much difference in peer review. Cited references tie a study to the community of researchers and the research question but do not affect the quality of the research itself that was done and reported. Finally, I wholeheartedly agree that training and education as researchers is extremely important.
Your “Spheres of relevance” model looks very similar to my wedding cake model from the top, see https://www.jmir.org/2020/6/e21820/ – that’s the paper where I am commenting on WHO’s infodemic initiative… and there are many interesting parallels to what you write above…



