The authors of a much–critiqued study of the beneficial effects of tweeting on citation and altmetrics speak, finally.
I say “finally” since my attempts to get the authors to respond to my questions seemed futile. No one was willing to defend the paper, not even the journal’s editorial office.
And yet, the authors did finally respond through a Letter to the Editor, published in The Annals of Thoracic Surgery on July 20. I only heard about this letter from a colleague, not from the authors themselves.
The letter “We Stand By Our Data–A Call for Professional Scholarly Discourse“, by Jessica GY Luc and two co-authors reads with a tone of indignation, taking more offense that I questioned their integrity than their research. So offended, Luc appears, that she would not even cite my blog posts critiquing her research, or even dare write my name. How this letter got past an editor without these necessary details is surprising, until you realize that Luc and her two co-authors, Thomas Varghese and Mara Antonoff, are also editors of the journal. The letter was received on July 14th and accepted just two days later, according to its publication history.
While every surgeon has the right to vent their spleen, the authors make two claims that may require emergency surgery. To avoid any misunderstanding that may come from my rephrasing, I will quote their words verbatim:
Claim 1: We were unwilling to share our raw data — Our raw datasets are our intellectual property, ongoing analyses and longitudinal follow-up are underway, and we are not required to share them with individuals unknown to us who demand them.
Scientific publication is about making scientific claims public. (It’s strange that I’d have to write such an obvious statement to a readership of professionals dedicated to scholarly communication). If Luc wanted to keep her data and results private, she should not have published them in a scientific journal where the scientific community has the right to read, question, and demand evidence underlying her claims.
However, Luc’s dataset was built from public data sources, which was how I was able to reconstruct it (dataset download .xlsx) from a list of papers she provided in an appendix published in an older paper. If Luc was able to detect a very large citation effect after just one year, why was I unable to reproduce their findings? Well, she had an answer for that too:
Claim 7: No citation differences exist between the intervention and control arms of the study upon reanalysis of a reconstructed dataset. This comment is based on a false premise that the outcomes of interest at 1 year are identical to the outcomes at 2.4 years. It is simply impossible for the dataset to be recreated because our analyses were conducted at different timepoints–and Altmetric scores as well as citations are dynamic and changing continuously.
The authors double-down on their defense by arguing that “it is infeasible to retrospectively analyze the citations that were present at the exact timepoints that we performed our analyses.”
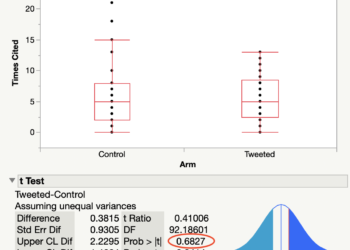
Citations are cumulative — they don’t simply vanish from the public record. An average difference of 2.4 citations in favor of the Twitter intervention group in year 1 should should have been detected in year 2. Even so, I downloaded new citation data from Clarivate and plotted them by year of publication. As you can see from the box plots below, there is no evidence that tweeted papers outperformed the control group at any time after the experiment was initiated: Not in year 1, not in year 2, not in year 3 or in year 4.
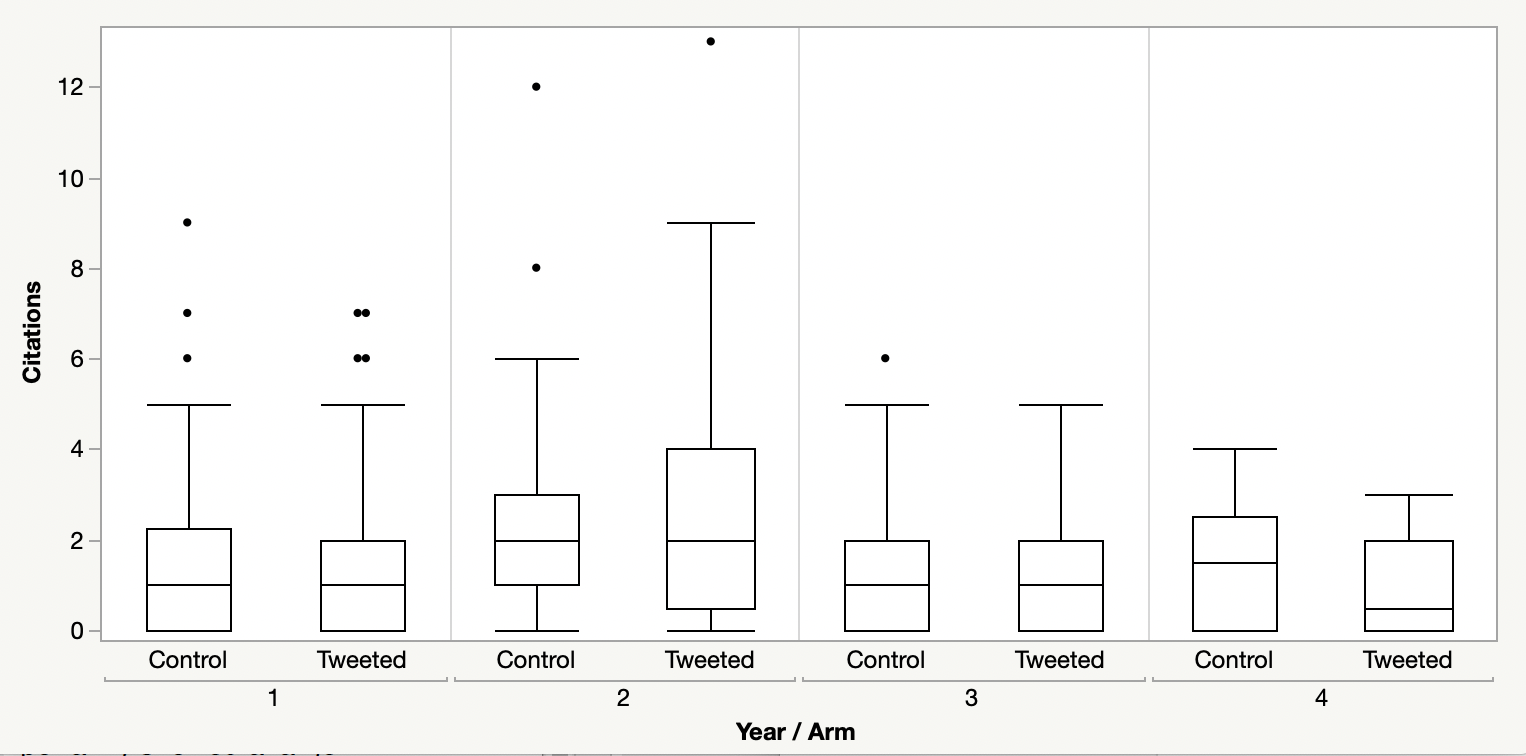
In spite of counterfactual evidence, if you take time to digest their last claim for a minute, Luc and others are making an argument that it is not sufficient to approximate their study closely; it has to be the exact study. And because they won’t tell you exactly when they measured paper performance (and you won’t be able to do it retrospectively, anyway), you have no grounds to question their results. Plus, they won’t send you their dataset, citing intellectual property rights. Essentially, Luc is arguing that the reason why no-one can replicate their results is that their experiment is, by design, non-reproducible.
Will anyone die or suffer because of this paper? Absolutely not. But the same could be said for the vast majority of scientific papers published each year. The claims made by Luc and others may help justify the jobs of social media professionals in publishing, but they may also whittle away the precious hours of people with the false belief that tweeting benefits the dissemination of research and boosts the citation performance of journals.
The process of trying to communicate with the authors of this paper exposes serious questions about the integrity of the editorial and review process performed at The Annals of Thoracic Surgery. If readers cannot fully trust the claims made about a paper on tweeting, should they trust a paper on open-heart surgery?
The real damage of this paper is not the promotion of a sham intervention, but to the reputation of the journal and the editors who are entrusted to run it. Yes, this is a time for professional discourse. The authors either need to admit error and retract their paper or provide evidence to support their claims.

Discussion
27 Thoughts on "Tweeting-Citations Authors Speak, Finally"
Thank you Phil. Your comments need wide publicity – on Twitter
Thanks for this critique and for pointing to the authors’ response. As a librarian working in the area of scholarly impact this is of practical and professional interest. It’s very possible for papers like this Twitter study to find their way into professional practice. As such, discourse about their reliability is needed.
The controversy around this article illustrates perfectly the struggles we’re having with moving to Open Science and the broad acceptance of Open Data policies. Researchers in some fields are more receptive to moving to better, more transparent methodologies, but there are still many stuck in the past. Researchers are often overly protective of their data — they claim ownership over it, having worked hard to put it together, and fear that if they make it available, others may do further research on it that they were hoping to do themselves. The other reason why one would be reluctant to share data is a fear of scrutiny — if someone else can analyze what was done, they may be able to see where mistakes were made and incorrect conclusions reached.
Neither of these is a valid excuse. If you’re afraid your future work is going to be scooped, then don’t publish until you’ve fully exploited your dataset. In this particular case, it seems like an absurd concern — the intervention is trivial and the results are based on publicly available databases. There are no patient confidentiality or informed consent issues involved.
Ideally this controversy will drive the journal in question and the field in general to adopt better, more modern open data requirements. The harm done by being seen as secretive and trying to hide something is much more damaging than being discovered to have made an honest mistake.
What David highlights here is an obvious tension between how scientists operate and how we WANT scientists to operate. I come from a field that studies the nature of science from a philosophical perspective, and this is always the tension that comes up. We can describe science as tentative, subjective, and influenced by society, but scientists do not necessarily recognize those qualities. So, is it truly the “nature of scientific knowledge” if those charged with developing that knowledge don’t think so?
I believe that the library tends to side with this ‘nature of science’ philosophical perspective, but I am continuously curious about the role that scientists think that they play in this field and why they are pursuing the development of scientific knowledge. In this case, I wonder if it is to be famous for a revolutionary paradigm shift (like Watson and Crick), is it to be a part of an “elite” group of intellectuals with capacity far beyond the “layperson”, or is it truly to advance science so that society ultimately benefits? Probably thinking its the latter, but the first two often cloud the potential for progress.
Thanks Kristina — I think another factor is that scientists are human beings, with families, and mortgages, etc. There’s often a desire to put them up on a pedestal, as if they were above the everyday concerns that we all face. But we always have to remember that they are just folks with jobs trying to advance their careers and take care of themselves and their families. So it makes sense that there is a tendency to what’s best for oneself and one’s career rather than what’s best for the more amorphous concept of “scientific progress”. The key to finding harmony is to drive policies at universities, journals, and funders that reward the researcher for doing what’s right for science. Datasets need to be seen as valid research outputs, just as important as the paper (a story written about the dataset).
Thanks for keeping us updated. Keep up the good work!
A very useful case study and discussion. Thank you.
When it comes to research culture change, research funders have the greatest leverage. If data disclosure and a track-record of disclosure were more important factors in determining funding eligibility, researcher behavior would likely change quickly.
While publishers can use checklists to make disclosure assertions more transparent, granular and verifiable, only research funders have the “power of the purse” to reimagine the incentive system.
Too much of today’s research culture (including the article in question here) is apparently driven by the quest for “impact” in the form of citation counting, resulting in counterproductive behaviors.
Richard Wynne
Rescognito
Have you considered engaging with COPE? COPE has a Facilitation & Integrity subcommittee that mediates the kinds of issues you raise. (Full disclosure: I am a COPE council member and I serve on that committee, though I rotate off of COPE next month and I would not be involved in this facilitation because I’ve posted publicly — here — on it).
Seth Leopold, MD
I’m not sure what there is to mediate, Seth. The authors think their paper is sound and are unlikely to retract it on their own accord. If there is any conflict that needs to mediated, it may be within the editorial board of the journal.
Dear Phil,
Well, if the journal is a COPE journal (I’m not sure if it is), and they are found not to be meeting one or more of COPE’s standards, they might find themselves getting sanctioned (COPE does that now, in selected circumstances). Because of this, often a letter from COPE’s F&I committee causes editors to be somewhat more forthcoming. I’m not saying this is the case or that they’ve done anything wrong, since I have not run the numbers as you have and sometimes there are two or three sides to a story. But I’ve seen some nice results achieved by the work done by the F&I group in cases like this one at COPE.
All the best,
Seth
The Annals of Thoracic Surgery is a member of COPE by virtue that it is published by Elsevier.
https://publicationethics.org/members/annals-thoracic-surgery
Right, so if you wanted to, you could ask to have your concern facilitated.
All the best,
Seth
[I originally tried to post anonymously on PubPeer, but after writing a long and detailed comment, it promptly disappeared upon submission. Here is an abridged version:]
The authors have now released a full list of the 56 articles that were tweeted/retweeted as part of their study: https://twitter.com/search?q=(from%3Ajessicaluc1)%20until%3A2018-06-19%20since%3A2018-06-03&src=typed_query&f=live
In the original paper, the authors wrote “We have previously published in detail our study protocol for the present trial [10]. In brief, 4 articles were prospectively tweeted per day by a designated TSSMN delegate (JL) and retweeted by all other TSSMN delegates (n=11) with a combined followership of 52,893 individuals and @TSSMN for 14 days from June 4 to June 17, 2018”
Presumably those 11 TSSNN delegates were also the 11 authors of the study, but I cannot access Supplementary Table 2 of the referenced previous study (https://www.sciencedirect.com/science/article/abs/pii/S0003497519311622) where the 11 delegates should be listed. However, upon inspection I found that a number of those articles were tweeted less than the expected 12 times (11 TSSMN delegates + TSSMN official account), see screenshots here: https://imgur.com/a/IEEg98H. For those 5 articles, I found only 4 accounts consistently retweeted every article, one of which included the official TSSMN account. Other accounts (some of which belong to the article’s authors) only tweeted a subset of those articles or a single article.
The methodological problems in this paper are worrying, and I would strongly urge the authors to reconsider their combative position, engage in open science principles and release their data.
If you email me directly at pmd8@cornell.edu , I will send you the supplementary tables.
Dear Phil,
At the beginning of this article you note “How this letter got past an editor without these necessary details is surprising, until you realize that Luc and her two co-authors, Thomas Varghese and Mara Antonoff, are also editors of the journal. ” I am somewhat surprised that no one has commented on this fact. Is there a standard procedure for avoiding the obvious potential conflict of interest that this situation implies? It is common for experts in a scientific field to be science journal editors in their field, isn’t it? So this situation must be common. Are there no common policies to deal with this, such as recusal if the editor is an author or co-author of the submitted paper? Is there a way to document recusal? Was any such procedure followed in this case?
The first step would be to add a disclosure statement to the paper, alerting the reader that the authors are also editors at the journal. The second step would be to add a statement that this paper was handled by another editor at the journal. Without such disclosures, it is very possible that that Luc and others handled and reviewed their own paper.
Here is an example of a disclaimer on an Invited Commentary published recently in JAMA Network Open:
Leveraging Tweets, Citations, and Social Networks to Improve Bibliometrics
Disclaimer: Dr Trueger is a digital media editor of JAMA Network Open but was not involved in any of the decisions regarding review of the manuscript or its acceptance.
If the tweeted papers are meant to have been cited 3.1 times vs. 0.7 times for the non-tweeted papers, after one year, it seems odd that in your analysis the mean citations are about 3.0 after TWO years for both groups. Citations normally accumulate rapidly in year 2 and 3 compared to year 1.
Figure 1 shows the distribution as box plots (link describing box plots is found in the text above the figure). The horizontal line in the box represents the median performance of the group, not the mean. For skewed distributions, median is a better indicator of central distribution than mean.
Nevertheless, for all papers, I get a mean of 1.5 citations for both the tweeted and control arm for year 1, and 1.6 vs. 1.7 if you exclude Reviews and Editorials.
Here is a link so you can download the dataset. https://3spxpi1radr22mzge33bla91-wpengine.netdna-ssl.com/wp-content/uploads/2020/07/Thoracic-Surgery-Dataset.xlsx If you find anything else interesting, please let us know. Thnx.
It’s mathematically impossible to have one group be cited a mean of 3.1 times and the other 0.7 times after *any* time period, if the mean is 1.5 and 1.5 for those same two groups at *any* time period. Because citations accumulate over time. Since your mean citations are smaller for the tweeted group, your time point must be earlier than theirs; but your mean citations are larger for the non-tweeted group, therefore your time period must be *later* than theirs. This is impossible, hence your results and their results can’t both be true.
Agreed. The figure I generated was based on the print publication year of the paper, so a paper published sometime in 2017 completed its first year at the end of 2017, its second year in 2018, etc. Luc may have used the first (electronic) publication date and measured, in days, from that date, but this is just speculation because her methods section is pretty sparse:
Outcomes
Measured outcomes included citations at 1 year compared to baseline, as well as article-level metrics (Altmetric score) and Twitter analytics.
Indeed, she didn’t include the citation source and wouldn’t divulge that to me by email. It does show up in her Letter, however.
Nevertheless, after 3 blog posts on this paper, I am no clearer to understanding how she got the results she is reporting. The dataset is free for the downloading. Given the position that Luc is taking, I don’t think that she’ll be making her dataset publicly available.
Fantastic article. I hope you take Seth’s suggestion and raise these issues to the COPE F&I committee.
We need more fact-checking in science (and this world in general). Thank you for taking your time to do this.
I am surprised publishing professionals are so surprised by this process. To my mind, this is not a particularly egregious article, and my experience trying to get corrections/retractions made chimes with this perfectly. Journals drag their feet (even with no obvious conflict of interest), data not in the paper is rarely obtainable and I’ve never succeeded getting a formal admission of potential problems on the journal website. I hope this causes reflection on how the publishing system fails in addition to speculation on the motivations of scientists.
The contrast between the attitude to copyright ‘confiscation’ in this post compared to this https://scholarlykitchen.sspnet.org/2020/07/20/coalition-ss-rights-confiscation-strategy-continues/ is striking too me.
“Luc and others are making an argument that it is not sufficient to approximate their study closely; it has to be the exact study”. I couldn’t quite understand this statement. Maybe because I am not a native speaker? Thanks in advance for any clarification. Excellent article.
When the original authors make their citation data available, it will be easy to see if there is a problem. The most obvious way is if some papers have more citations in their dataset (after 1 yr) than their total citations now (after several years). With so many papers, this should occur for some of them if there is an issue.
Mistakes were made and the ensuing silence only amplified the knowledge gap. As noted, Methods were not clearly defined and Conclusions appear to miss the mark of the Objective. The need for process, protocol, and standards adherence is clearly called out to quantify and qualify for good scientific communications to readers and for participants’ lessons: data and their sets. In a “normal” year, the June-July cycle of medical residency training programs aims to control for best outcomes in the midst of daily/weekly shifting resources of faculty and training resident staff, Operating Room (OR) availability, etc., all while annual residency programs are transitioning June 1 -July 1. Add a pandemic and burnout to the equation and a more daunting dynamic to navigate the landscape results. Accuracy and opacity of data remains a responsibility. In due course right the wrongs and learn the lessons in the spirit of knowledge.
Hi Phil, this is useful analysis but the lesson is about reproducibility, open data and author / editor ethics, rather than whether or not communicating research (via e.g. Twitter) benefits dissemination of research (given that your point is that this study wasn’t robust / reproducible enough to provide evidence on this one way or the other). It’s also important of course to distinguish between dissemination (an action) and citations (a result, of a sort). There is no evidence here to underpin your assertion that the “belief that tweeting benefits the dissemination of research” is “false” so perhaps that reflects a personal view rather than a conclusion drawn from your work around this.
When the Altmetric team at NTU analysed usage of Kudos* (https://doi.org/10.1371/journal.pone.0183217) (comparing researchers’ communications about their publications, including posts to Facebook, Twitter and LinkedIn as well as other websites and comms via e.g. email) they found that (of the social media sites) Facebook was the platform most commonly used by people posting about their research, but links shared via Twitter were more likely to be clicked on. That study looked at the relationship between communications and downloads (rather than citations) and found a higher growth in downloads where authors had actively communicated their work one way or another.
That is to say, actively communicating about your publications _is_ worthwhile, and for some people Twitter will be the most effective way to do that. Dismissing that as a “false belief” discourages researchers from taking hugely important steps to ensure their work is found, read and applied.
I am _not_ saying downloads = readership, or that readership = citations; I’m saying that more people being aware of and clicking through to view a publication increases the _potential_ for readership and that in turn increases the _potential_ for citations.
Finally: even if citations isn’t a meaningful measure (as others here have said), the use of citations as a measure can still have a positive effect if, in pursuit of better performance against said measure, people choose to communicate their word more actively and broadly – thus maximizing the potential for it to be found, read, applied and to have meaningful impact whether or not citations are an appropriate way to define that.
*Disclaimer – I am one of the founders of Kudos and we commissioned the Altmetric team at NTU to design and undertake a study of our data to help us understand the effect, if any, of people communicating about their work.