Mention the name Brian Wansink around Cornell and you’ll make a lot of people uncomfortable. Wansink, a food researcher, was known by his innovative experimental designs and headline-grabbing results. He was also exposed as someone who put good stories ahead of good results, investigated for “p-hacking” his data, and unceremoniously left Cornell in 2018. While his departure was more than four years ago, the damage he did to the reputation of his school and colleagues is still raw. For top-research institutions and researchers, reputation is everything. And reputation rubs off in both directions.

p-hacking is a term used in the quantitative life and social sciences where a researcher analyzes data to ensure a statistically significant result. In practice, it can mean using inappropriate statistical tests, excluding data points, collecting lots of variables — in the hope that some associations will come out significant — among other inappropriate behaviors. Fear of p-hacking is the very reason why rigorous medical journals require authors to register their experiments in advance and follow a strict protocol for reporting their results.
In a previous post, I described how a recent study on the effects of Twitter on paper citations violated several of the journal’s rules, by failing to describe how sample sizes were calculated, omitting how readers could access the paper’s underlying data, and refusing to answer questions about the validity of the paper’s findings.
On 13 June 2022, more than a month after my initial request, the editorial office of the European Heart Journal provided me a link to the authors’ data (as of this writing, there is no public link from the published paper). The data were provided in .dta format — a proprietary format for users of a statistical software called Stata. Nevertheless, with the help of a Cornell data librarian (go librarians!), I was able to access the data in a generic format that allowed me to verify the results reported in the paper.
The statistics for analyzing and reporting the results of Randomized Controlled Trials (RCTs) are often very simple. Because treatment groups are made similar in all respects with the exception of the intervention, no fancy statistical analysis is normally required. This is why most RCTs are analyzed using simple comparisons of sample means or medians.
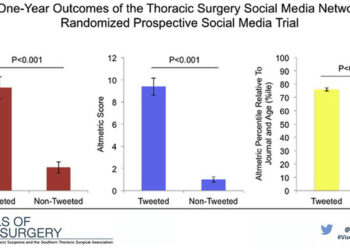
Deviating from this norm, the authors of the Twitter-citation paper used Poisson regression, a more complicated model that is very useful in some fields (e.g. economics) when analyzing data with lots of independent variables. However, Poisson regression is limited in its application because it comes with a big assumption — the mean value must equal the variance. When this assumption is violated, the researcher should use a more flexible model, like the Negative Binomial. Using an inappropriate model on data can result in unreliable results, which is exactly what I found with the Twitter data.
…the only test that provided a statistically significant finding was the one where the model was inappropriate for the data
Using Poisson regression on their data, I got the same results as reported (12% citation difference, 95% confidence interval 8% to 15%, p<0.0001), which appears to be a robust and statistically significant finding. However, the model fits the data very poorly. When I analyzed their dataset using a Negative Binomial model, the data were no longer significant (13%, 95% C.I. -5% to 33%, p=0.17). Yes, the estimate was close, but the confidence interval straddled zero. Using a common technique when dealing with highly-skewed data (normalizing the data with a log transformation) and employing a simple linear model also provided non-significant results (8%, 95% C.I. -7% to 25%, p=0.33). Similarly, a simple comparison of means (t-test) was non-significant (p=0.17), as was the non-parametric (signed-rank) equivalent (p=0.33).
In sum, the only test that provided a statistically significant finding was the one where the model was inappropriate for the data.
The authors didn’t register their protocols or even provide justification for a Poisson regression model in their preliminary paper. A description of how their sample size was determined was missing, as was a data availability statement — both are clear violations of the journal’s policy. The editorial office was kind enough to provide me with a personal link to the dataset, but it is still not public. They have continued to invite me to submit a formal letter to the Discussion Forum of their journal. They have not responded to questions about how this paper got through to publication without these required elements or what they plan on doing about it. No one is willing to admit fault, and the undeclared connection of several authors with current or past EHJ editorial board roles raises questions about special treatment.
I stopped using Twitter recently because it began serving me inappropriate ads and senseless personal tweets. Elon Musk’s pronouncements on how he would change the service, if he became CEO, added to my decision. Social media companies wax and wane, and their influence in the lives of researchers can be ephemeral. In five years, a study on the citation benefit of Twitter may be heaped into the same bin as other fill-in-the-blank-leads-to-citations papers. But a tarnished reputation is deep and long-lasting. I hope the editors of EHJ understand what they are sacrificing with this paper.

Discussion
4 Thoughts on "Desperately Seeking (Statistical) Significance"
Thanks Phil (and the SK) for sharing this analysis. It’s really important that issues around data integrity get fresh air, and this sounds like an example where that was sorely lacking. It also helps educate those (‘most?) of us less familiar with statistical analysis about the critical role that journal policies around data play in ensuring transparency. It’s something I’ve read many times, but hard examples like this help drive it home.
Thanks Phil for such an insightful analysis. It reminds me of the “3 types of lies” and at the same time “devil is in the details”! As Tim said, journal policies around data is very important. On the other hand, I think the main issue of all these is the pressure of publishing more articles and fast turn-around time. Rigorous analysis and peer review might be compromised in come cases.
Thanks Phil for illuminating the importance of open data and reproducibility research. Rick rightly said that one of the causes is pressure to publish more. Policies of journals also effecting this trend. Another cause to surely produce statistically significant results may be that marginalized results are oftenly rejected by peers on reviewing stage although open data availibility may increase the acceptability of marginalized findings. It is also important to ensure the protocols and rigor in conduct of research.
It does seem that there’s a benefit to pulling main points from these posts calling out both the dodgy behavior of the authors and the lax behavior of the publisher and publishing it in EHJ as a more durable venue. Of course if they make difficult you can always rant about that here