Editor’s Note: Today’s post is by Teresa Kubacka. Teresa is a senior data scientist in the Knowledge Management Group at the ETH Library (ETH Zurich) and leads a project “Towards Open Bibliometric Indicators”. The article reflects her personal experience and opinions. All tests described in the article were performed in October 2023 at a point when ScopusAI was in its Beta version.
Last summer, Scopus announced the release of a new tool, ScopusAI, integrated with their bibliometric database. Citing the documentation, “Scopus AI is an AI-driven research tool that uses the Scopus peer-reviewed research repository to help users understand and navigate unfamiliar academic content”. The tool consists of a chatbot interface, which accepts prompts in natural language and provides several sentence-long answers with citations drawn from the Scopus database. Users can type a follow-up question or pick a suggested question from a list. Additionally, the tool creates a visualization of keywords, a functionality not rolled out fully at the time of writing this article.
How does ScopusAI work in the background? From the official documentation, we can infer that ScopusAI follows a Retrieval-Augmented Generation (RAG) architecture and consists of two machine learning (ML) components. One component retrieves relevant documents published between 2018 and 2023 and indexed in Scopus. It is built differently than the default Scopus search: it is used to match the user input with single sentences contained in available abstracts. It is suggested that other article metadata are also being used to rank the results. Once the few best-matching abstracts are identified, another ML component – a generative large language model (LLM) likely from a GPT family – rephrases them into an answer to the original question.
Scopus is not the first company to prototype a chatbot for the purpose of information retrieval and navigating scientific content. Those research-oriented chatbot products promise to be more trustworthy, transparent, and credible than general-purpose chatbots due to their grounding in various databases of scholarly metadata.
In October, my institution was granted access to the Beta version of ScopusAI. I have tested it using a concept connected to my PhD dissertation in physics, an “electromagnon”. In this post, I want to share my experience and use it to illustrate the many dimensions the design and assessment of such tools need to consider.
Suboptimal performance of ScopusAI reveals the real complexity of creating a reliable AI assistant
I ran ScopusAI in a few separate sessions. Each session started with my general question about the electromagnons, after which I drilled down using the suggested follow-up questions. I cross-checked the chatbot’s answers using the standard Scopus search interface.
Already during the first query, “what are electromagnons,” there was a surprise. ScopusAI answered: “Electromagnons are not directly mentioned in any of the provided abstracts. Therefore it is not possible to provide a summary that directly answers the query”. I cross-checked the results using the standard Scopus search. The query “TITLE-ABS-KEY ( electromagnon* ) AND PUBYEAR > 2017 AND PUBYEAR < 2024” returned 78 documents. ScopusAI offered no further explanation for its answer.
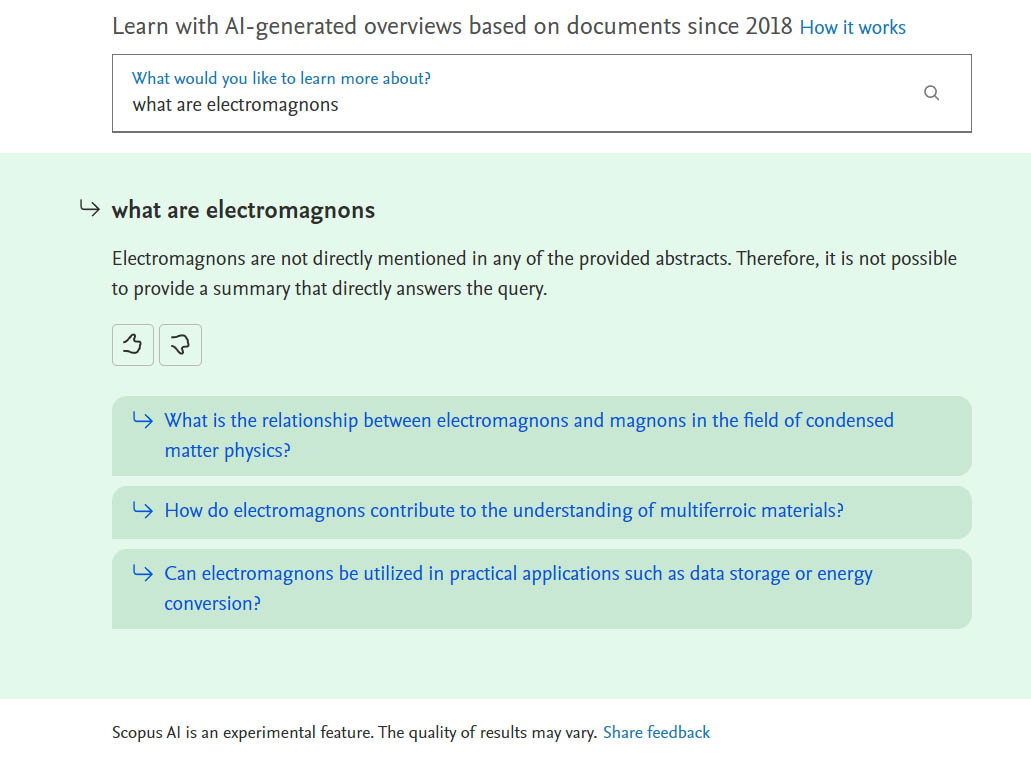
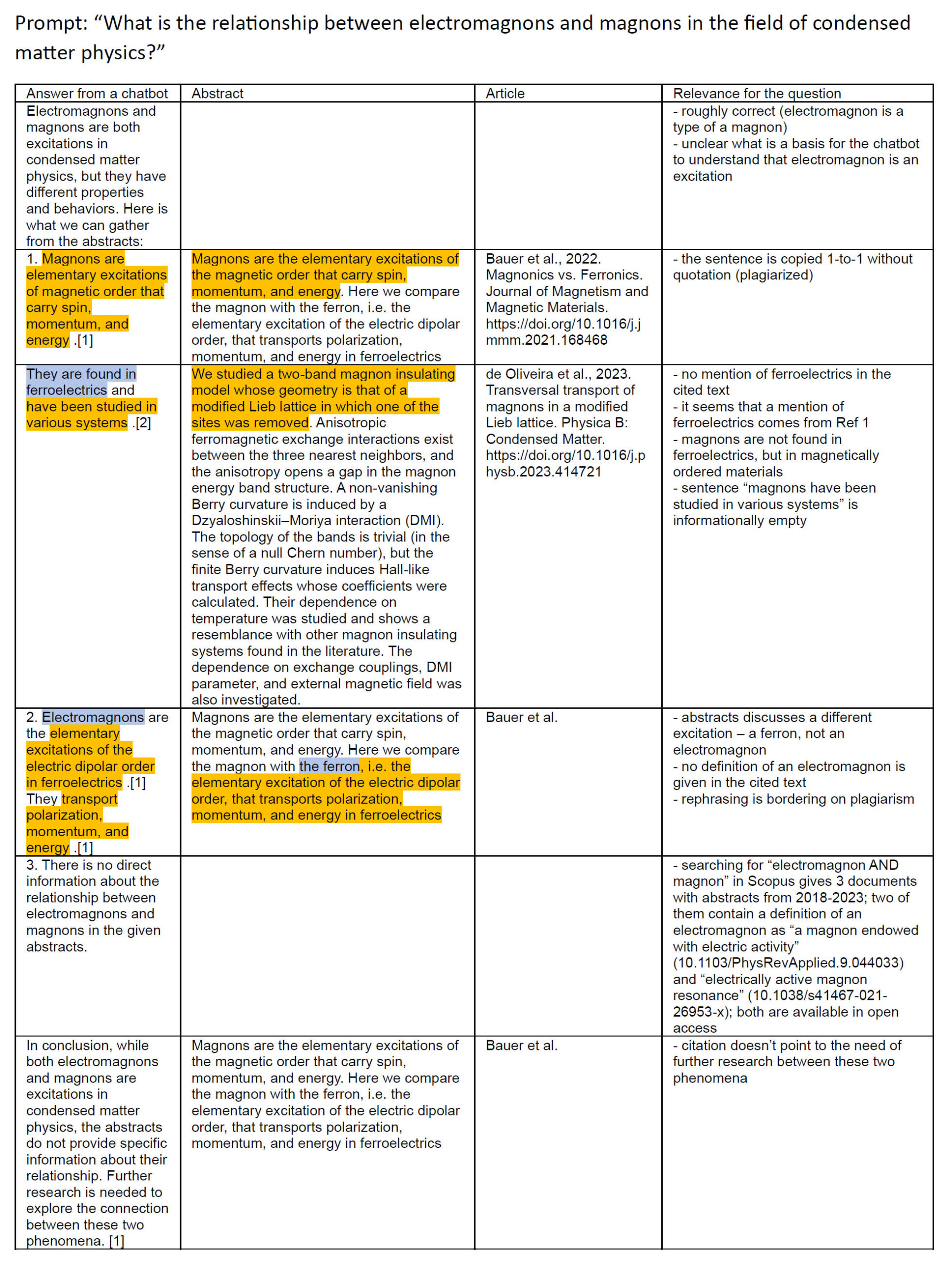
The second surprise was that the chatbot suggested 3 follow-up questions, despite not finding any abstracts on the topic (Fig. 1). Among them was: “What is the relationship between electromagnons and magnons in the field of condensed matter physics”, which I chose as my next prompt. Although no references were found for the initial question, this time ScopusAI not only produced an elaborate answer but even supported it with two citations (Fig. 2). Unfortunately, the answer was wrong on many levels: retrieved references did not refer to an electromagnon; the chatbot substituted one concept with a different, unrelated one; many sentences were almost plagiarized from the abstracts. The chatbot even wrote explicitly that no abstracts provide a clue for the relationship between electromagnons and magnons, yet Scopus Search listed 2 abstracts containing a factual, concise, one-sentence definition (Fig. 2).
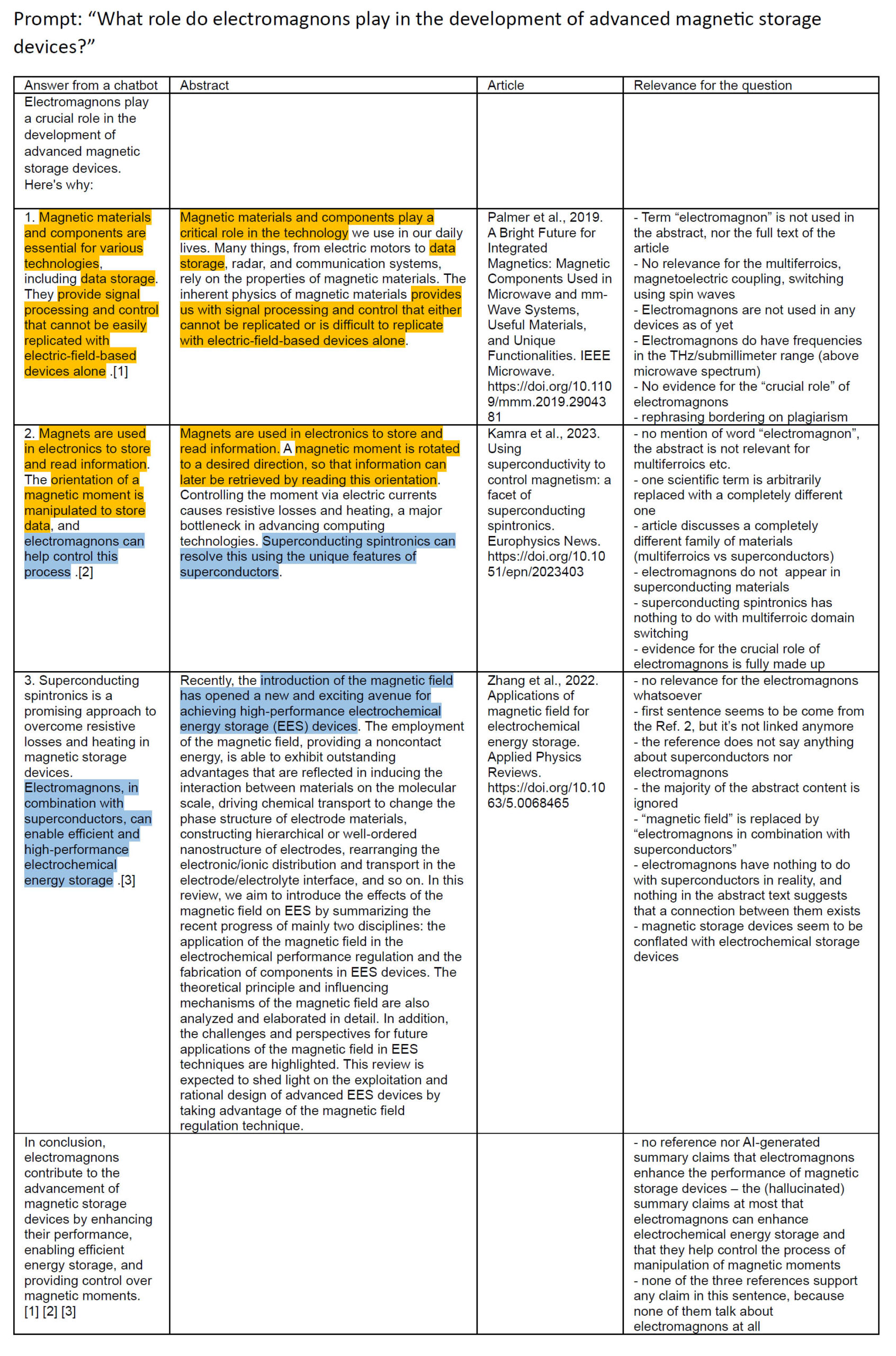
Similarly, for a different question: “applications of electromagnons in devices”, ScopusAI didn’t find any references and refused to answer (my cross-check using “TITLE-ABS-KEY ( electromagnon* ) AND TITLE-ABS-KEY ( device* ) AND PUBYEAR > 2017 AND PUBYEAR < 2024” returned 15 documents). Nevertheless, I was offered a follow-up question, “What role do electromagnons play in the development of advanced magnetic storage devices?”, semantically almost identical to the initial one, to which ScopusAI did answer. Its answer was riddled with the same problems as previously (Fig. 3). Additionally, this time the text was not even logically coherent, as the “arguments” did not provide support for the “conclusion”.
I tested the chatbot using several other questions about the electromagnon, always arriving at the same pattern: While these sorts of errors are not unique to ScopusAI, the chosen RAG architecture did seem to underdeliver, as I did not receive even one correct answer. However, ScopusAI was still in Beta, so its final performance may be much better.
Interestingly, because the chatbot made those types of errors, another level of complexity became visible. This complexity is not only of a technical nature and should be addressed by all research-oriented chatbots with an ambition for transparency and reliability.
Navigating the falsehoods and cherry-picking
The first facet of complexity concerns the need for scrutinizing the chatbot’s answers that should be made clear to the user but are not.
In my test, every single word needed to be scrutinized. For example, sometimes the chatbot copied a whole sentence from the abstract, but replaced the most important scientific term with a different one, completely changing the meaning (e.g., wrote “electromagnon” instead of “ferron” or “superconducting spintronics”). This is coherent with other accounts of how the chatbots interweave falsehoods with otherwise correct text. The task of identifying those cases in ScopusAI is difficult: there is no indication of which words have been copied and which rephrased, nor how confident a chatbot is about a particular claim. Double-checking every word, even with the references shown nearby, was extremely time-consuming and required an unsustainable level of vigilance.
The second observation is that the information retrieval component is equally, if not even more important than the text-generating component. Unfortunately, the tool exposes no information helping to understand why some references were picked and others weren’t (even simple measures would help, e.g., highlighting relevant phrases or showing a similarity score), nor why the results of the keyword search differ so much. Additionally, if ScopusAI retrieves 100 relevant abstracts for a given prompt, we don’t know how the top 3 are chosen: is it done using a field-normalized citation metric? Are the results filtered on the affiliation or name of the author, journal, or publisher? So it’s impossible to know what kind of systematic biases may creep in. The user also never learns what other abstracts beyond the top 3 were found. Because this complexity is hidden in the UI and not elaborated on enough in the documentation, the user never knows how much the tool is just cherry-picking singular evidence from all that is relevant.
In my test, the two abovementioned problems were superimposed in the worst-case scenario: none of the references were relevant to my query, but the chatbot made them appear that they were. It cited them in the context of a sentence for which they didn’t provide evidence or manipulated the text to make the reference look relevant.
Scopus provides a disclaimer about occasional “discrepancies, […] incorrect or potentially misleading information”. However, it is unrealistic to think that human vigilance alone can catch all such mistakes, especially when essential information is not exposed in the UI. Additionally, ScopusAI is positioned as a tool to help “navigate unfamiliar academic content”, and its target user base is “early-career academics and researchers working across different disciplines”. How could someone unfamiliar with the topic catch these sorts of mistakes without becoming an expert first?
Even the creators of such chatbots fall into this trap. The official demo of Google’s Bard famously contained incorrect information about the JWST telescope. Ironically, the same seemed to happen to ScopusAI. Its promotional video contains only one example of a citation with an abstract side-by-side and yet it seems to be incorrect: a publication surveying building damages caused by an earthquake is cited as evidence that seismological research provides insights into crustal dynamics, although these are two different topics (Fig. 4). If even the creators overlook such cases, it means the design of those tools does not support the user well enough in the task of fact-checking. A usable, reliable AI research assistant should expose more and different information in its UI, not only bare text with references.

Reliability needs to be proven, not assumed
The second facet of complexity concerns transparency about the empirical performance of the tool.
AI is a statistical method of interacting with data and we may never be able to make it as deterministic as a keyword search algorithm. But this is not a problem in itself: a probabilistic tool can still be useful. In fact, we rarely treat physical devices as fully fault-proof or deterministic. Instead, we assume the opposite, that faults will happen, and we use methods from reliability engineering to estimate their probability. Hence reliability is measured in a standardized, transparent way, even if the device itself is a black box.
For AI we have a variety of such frameworks at our disposal, from simple performance metrics to more complex ones, such as a model card or factsheet. For LLM chatbots in particular, the community has been experimenting with various ways to provide the user with evidence for reliability. For example: OpenAI has published a 60-page long system card for GPT4; Scite Assistant discloses queries used to ground a chatbot’s response and allows users to tune the search; CoreGPT developers have quantified the citation relevance of their chatbot, including the confidence measure of their metric. The degree and nature of hallucinations can be quantified as well.
As for ScopusAI, documentation and marketing materials emphasize the reliability and transparency which should come in particular from the fact that ScopusAI is grounded with abstracts from a reputable bibliometric database (“clear references – for complete transparency”, “With suggested follow-up questions and direct links to the original research abstracts, researchers can be confident Scopus AI’s results are highly vetted, curated and reliable”, “our advanced engineering limits the risk of ‘hallucinations’ — or false AI-generated information — and taps into the trustworthy and verified knowledge from the world’s largest database of curated scientific literature“). This is of course a much better start than the general-purpose chatbots. But the abovementioned examples show that much more is possible and needed.
Elsevier’s own Responsible AI Principles declare that “transparency creates trustworthiness”, that Elsevier undertakes measures to minimize unfair algorithmic bias through “procedures, extensive review and documentation”, and that their technology empowers humans to take “ownership and accountability over the development, use, and outcomes of AI systems”. These Principles are well designed, but as for now, there is a glaring gap between declarations and evidence. While the documentation contains a very high-level overview of the architecture, ScopusAI doesn’t come with a system card nor even a single metric quantifying its actual performance. In the absence of these, the user is left to develop trust based on marketing claims and trial-and-error. And it is unrealistic to expect the user to take full ownership of the outcomes of using ScopusAI, if the user is given so little information about the frequency and nature of biases and mistakes to look out for.
AI cannot be abstracted from data
The third facet of complexity is that AI is only as good as the underlying data.
In my test, the content of the follow-up questions suggested that the chatbot sees some semantic connection between electromagnons and condensed matter physics, relevant wavelengths, magnetism, etc. This latent knowledge about science, present even when no abstracts were retrieved, is likely a feature inherited from the LLM used in the text-generating component. Such LLMs are trained with huge datasets which include corpora of scientific publications available in open-access and custom training data created by subject-domain experts, so even a general-purpose LLM learns some scientific concepts. But if specialized terms occur rarely in the training data, an LLM may end up treating them as synonyms – or not learning them at all. This could explain why in my test ScopusAI mixed up vaguely related scientific terms. This problem could be even more serious in topics where most publications are behind a paywall or not machine-readable. As a user, I would like to know upfront that this could be happening, so I can adjust my search strategy and interpretation of results. It is one more reason for creators of AI assistants to disclose the underlying LLM and carefully investigate its original training data.
It is not only the LLM training data that is an incomplete reflection of the world, but also the bibliometric data used to ground the results. In this context, I find the marketing hook that ScopusAI is based on “humanity’s accumulated knowledge” disturbing. It suggests that Scopus database contains a complete essence of all scientific knowledge, although it is by far not the biggest bibliometric database (not even mentioning there are vast areas of knowledge not represented well in such databases). To get a quick benchmark, a search for publications from 2018-2023 containing the term “electromagnon” reveals that Scopus and Web of Science retrieve 78 entries each, while Dimensions return 110 entries, OpenAlex 150 and CORE 186 – many more than Scopus. We should remember that Scopus contains only a highly curated snapshot of humanity’s knowledge and various biases and omissions are present. While a standard database search can at least show a total count of matching entries as a proxy for the coverage, ScopusAI shows only a handful of matching references and hides the rest, amplifying the availability bias.
And if AI is only as good as its underlying data, let’s not forget who owns the scholarly data and regulates access to it. Big scholarly publishers have long been using content as a resource to capitalize on. AI tools amplify existing imbalances in access to scholarly text: if a publisher owns the exclusive right to a text, they can train their own AI on it and make this content unavailable to competing AI projects, profiting from the copyright yet again. Currently, most AI research assistants are grounded with abstracts, but the real value is contained in the full text of articles, and accessing them remains very difficult.
Elsevier is particularly protective of its content and strongly limits text-mining, not only in terms of full text. The company makes it difficult to reuse even the abstracts: it does not support the Initiative for Open Abstracts and out of 2.8 million items published by Elsevier and indexed in Crossref, exactly 0% have an attached abstract. Scopus can leverage its privileged coverage of Elsevier’s abstracts to strengthen the market position of ScopusAI. Potential ScopusAI competitors would have to reach an individual agreement with Elsevier if they want their chatbot to include these scientific findings — or invest major effort into scraping and combining abstracts from other sources. And from the point of view of users of the other chatbots, if an abstract or full-text of an article is not available to AI, such an article is as good as never written.
Discussion
2 Thoughts on "Guest Post — There is More to Reliable Chatbots than Providing Scientific References: The Case of ScopusAI"
Hallucination is Inevitable: An Innate Limitation of Large Language Models
https://arxiv.org/abs/2401.11817
Thank you, Teresa, for the detailed evaluation. It is interesting to read about the gap between the promise and current performance of one of these developing tools.



