The various bibliometric databases available to researchers and analysts are invaluable tools for understanding what’s going on in scholarly communication and for planning strategy for a journals publishing program. But each of these tools is unique, with different strengths, so it’s important to use the right tool for the job. When using them for research, it’s important to realize that as data sources, they vary considerably in how they treat the often-flawed metadata supplied by publishers. Further, they are impermanent, that is, the main tools we use for bibliometric information are continuously evolving, which makes it difficult, if not impossible, to exactly reproduce any given piece of research.

I wrote recently about some of the differences between some of the major bibliometric databases, largely meaning to point out that the databases that rely on persistent identifiers (PIDs) like the DOI (digital object identifier) excel when one is examining the current state of the market, but create challenges when one is performing historical analyses and looking for trends over time. In short, databases like Dimensions or OpenAlex identify articles based on their DOIs. If a journal moves from self-publishing to say, a partnership with Elsevier, all its DOIs are redirected to the Elsevier version, so in the database it looks like Elsevier has always been the publisher of the journal. Thus, the snapshot a DOI-based database provides is the current state of the market.
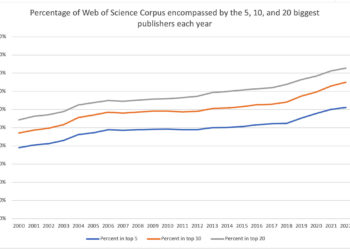
That’s why in this post from last October, I used Web of Science (WoS) to look at market consolidation over time. WoS is a selective, curated database, so a disadvantage of using it for market sizing is that it covers only a slice of the total market. The advantage of WoS, however, is that it shows a static screenshot for each year, offering a view of where an article was when it was published, rather than providing constantly changing data based on where a journal’s DOIs currently point to now.
All of these databases rely on publisher-supplied metadata as the basis for their listings, and because the quality of what each publisher puts out can vary, quality of the data outputs can suffer. Different databases have different processes of cleaning up and refinement on intake of publisher data, and thus may show very different results when looking at the same set of publications. Conference proceedings papers, for example, can show up differently in the same database depending on how they’re tagged by different publishers. In Dimensions, SPIE shows 25,000 “conference papers” in 2023, while IOP Publishing shows none, despite three of their three biggest publications being conference series journals. To accurately compare two publishers thus requires careful examination of the specifics of each program, rather than just a collection of the raw numbers.
Tagging irregularities can lead to significantly skewed data for the market as a whole. In 2022, the CABI Compendium (a resource that “brings together data and research on pests and diseases”) must have done something different with the metadata for its articles, and both Dimensions and OpenAlex show it as publishing nearly 80,000 articles that year. OpenAlex accurately lists these as “dataset” article types, while Dimensions sees them as journal research articles. If you’re not careful to filter them out, CABI suddenly appears to becomes the 9th largest journal publisher on earth for 2022, only to disappear entirely in 2023. ChemInform is listed in both Dimensions and OpenAlex as being among the largest journals in the history of journals. For those who don’t know ChemInform, it was an abstracting and indexing service and database from Wiley (ceased in 2016) that collected abstracts from a variety of chemistry journals. These collected abstracts appear to be tagged as articles, and with nearly 800,000 “articles” in Dimensions and around 500,000 in OpenAlex, it rivals the size of journals like The Lancet and Nature that date back to the 1800s.
In my experience, publishers have little incentive and business motivation to correct these past metadata errors — to do so takes time and effort and often incurs resupply fees. Thus, constant surveillance for anomalies is needed by those relying on bibliometric data to ensure they are filtered out.
But variance in the bibliometric databases goes beyond metadata issues and how the different databases parse that information. All of the major bibliometric databases evolve over time. Each of these organizations has dedicated teams making constant technological improvements, as well as editorial decisions about what gets indexed and how. At some point last year, Dimensions added the (very helpful) ability to filter by “Document Type,” which can help separate some (but not all) conference abstracts from actual research articles in a journal. This allows one to segregate 277,000 conference abstracts published in 2023 from actual journal articles, and more than 3.4 million for the last twenty years. Using this filter to get a more accurate picture of the research literature, the total number of journal articles each year drops by a significant 5%.
Clarivate made major changes to its Journals Citation Report (JCR) over recent years, reducing Journal Impact Factor scores to tenths rather than thousandths, merging journals from the Emerging Sources Citation Index (ESCI) in with its other indexes, and merging listings for journals that appeared across different indexes. All of which means that the data you collect for 2023 has to be adjusted if you want it to match the data for 2022 or 2021.
It’s not just these major changes across the databases. New and existing journals are added indexed regularly, often retrospectively. Scopus added nearly 1,200 journals in 2021 alone. Article indexing is often a lagging process, and it can take months for published articles to make it into the indexes. Pulling data early in the year for the past year risks missing articles published in the last few months of the previous year. You’ll also see different numbers as errors are corrected and lost articles found. Depending on the bibliometric index you’re using article access status might change across the life of the article: subscription articles reach their 12-month embargo point and become counted as green open access (OA) papers. Bronze OA articles complete their period of free availability and go back behind paywalls.
All this means that when you try to check the work in a bibliometrics analysis, or even your own work from a few weeks ago, the data collected at a certain point in time can no longer be reproduced.
There’s perhaps a parallel here with ecological research or studies looking at a one-time event like a hurricane or a supernova. An ecological survey of a particular region at a particular time cannot be reproduced ten years later, nor can one just whip up a new hurricane to see if previously reported results hold up. So like these types of studies, perhaps we should consider bibliometric analysis to be transient views of our knowledge of the literature at a particular point in time rather than the last word on any subject.
Making public the data behind any such analysis can resolve some of the issues, at least allowing one to check the work done in a study (but not to reproduce it from scratch, as that same data is no longer available from the same sources). But things aren’t that simple, because we’re mostly dealing with commercial products with limited rights granted toward redistribution of content, though OpenAlex and its CC0 license provide a stark contrast.
At the very least, every bibliometric analysis should include a detailed explanation of data collection. There are clearly anomalies in the data available from all of the major bibliometric databases, and a savvy analyst will compensate for them. But you may be aware of different anomalies than I am, and our compensations may not match, leading to potentially different conclusions. At a bare minimum, knowing which databases were used, which filters were employed, which terms were included and excluded, and which adjustments were made to account for known anomalies is essential. As always, thoroughly described open methods offer much more trustworthy results than analyses that gloss over the details.
But even so, we may just have to accept that there is a level of fuzziness and idiosyncrasy that can’t be avoided, and every analysis requires a certain level of asterisks and caveats.

Discussion
5 Thoughts on "Variability, Irregular Publisher Metadata, and the Ongoing Evolution of Databases Complicates Reproducibility in Bibliometrics Research"
I just want to note that one part of a DOI is the original publisher number. So a DOI-based database could be used to do bibliometric analysis on how many articles are now owned by a different publisher from the original one who registered the DOI. That may not be the analysis you are interested in, but there is that bit of historical vestige in DOIs.
Often true but not always. Many DOIs are deposited on the publisher’s behalf by aggregators using their own DOI prefix. In other cases, a publisher that acquires a journal with a large backfile that has never had DOIs may assign and register them using its own prefix. Getting an accurate publication history often requires viewing the front matter of each issue.
Good overview of these issues, David. You may be interested in participating in a Delphi study to develop a bibliometric reporting guideline, called GLOBAL. I believe the Round 1 survey is still active.
David, we have a couple of internal analysts who practice the dark arts of bibliometrics data normalization, but it was always an opaque topic to me. I appreciated this post! Thanks, Todd
Having just worked on a report for a client, this hit home for me. Getting some numbers to line up is not always easy! The journal website may show X number of articles published in a given time frame while Clarivate has something different. Dimensions does allow you to filter out conference abstracts to show only journal articles, but unless I’m missing it, they do not distinguish between an :original article” or a “review article” or a “letter to the editor’ and so on. And the citation counts never match! Making sense of all this is hard work, but can yield valuable results! Great stuff David!