 Editor’s Note: this is the second of two posts from HighWire Press’s John Sack, part one can be found here. John is the Founding Director of HighWire, which facilitates the digital dissemination of more than 3000 journals, books, reference works, and proceedings. HighWire started a blog this summer, and it has already become a valuable source of information and critical thought. It is increasingly vital for our industry to bring more voices to the table and for the stakeholders in scholarly communication to have their voices heard. We are cross-posting this piece, along with next week’s follow-up on both blogs, so please do take a look at what the HighWireblog has to offer.
Editor’s Note: this is the second of two posts from HighWire Press’s John Sack, part one can be found here. John is the Founding Director of HighWire, which facilitates the digital dissemination of more than 3000 journals, books, reference works, and proceedings. HighWire started a blog this summer, and it has already become a valuable source of information and critical thought. It is increasingly vital for our industry to bring more voices to the table and for the stakeholders in scholarly communication to have their voices heard. We are cross-posting this piece, along with next week’s follow-up on both blogs, so please do take a look at what the HighWireblog has to offer.
The transformation in discovery – and its consequences – was the topic of the opening keynote at the September 2015 ALPSP Annual Meeting. Anurag Acharya – co-founder of Google Scholar – spoke and answered questions for an hour. That’s forever in our sound-bite culture, but the talk was both inspirational — about what we had collectively accomplished — as well as exciting and challenging – about the directions ahead. Anurag’s talk and the Q&A is online as a video and as audio in parts one and two.
This post is in two parts: Part One covered Anurag’s presentation of what we have accomplished. The present post, Part Two, covers the consequences. Anurag has agreed to address questions about this post that readers put in the comments. Here is my take on the key topics from Anurag’s keynote.
In Part One, I highlighted the factors that have transformed scholarly communication over the last 10-15 years:
- Search is the new browse
- Full text indexing of current articles plus significant backfiles joined with relevance ranking to change how we looked and what we did.
- “Articles stand on their own merit”
- “Bring all researchers to the frontier”
- “So much more you can actually read”
In Part Two of this post, I cover Anurag’s view of What Happens When Finding Everything is So Easy?
Each of the above factors may seem to be incremental, but together they deliver so much impact that even a tradition-bound and well-practiced researcher workflow will change. In fact, while publishing behavior – often determined by a senior member of a research group, and by the senior editors of the journals they publish in – is slow to change, the “hunting behavior” of readers can shift more rapidly in response to adjustments made by the younger graduate students and post docs.
What are the effects of the transformation in finding and reading? Here Google Scholar has a lot of evidence – based on search and result behavior – from which to report. While the evidence and its interpretation are two different things, the evidence alone of behavior shift is important for us to be aware of.
What do researchers look for? More queries, more words, more concepts, more areas
Scholar records these changes, per user:
- growth in the number of articles clicked
- growth is in both abstracts and full text clicked
- but abstracts are growing more
- growth in diversity of areas clicked on
What’s happening here? An iterative-filtering workflow is now common: search – scan titles and snippet – click on a number of abstracts – click on a few full texts – change query – lather, rinse, repeat. I think of this as a kind of hunt-then-gather mode: you hunt, you gather up, you move on to another venue, you repeat. I imagine people are determining relevance via the abstract – which loads more quickly and never hits a paywall – then decide whether to store (a PDF) or read.
Scholar has also found that abstracts that have full text links are more likely to be clicked on than those that do not have such links. Perhaps this is because the user is assured that full text is available if it is needed. And/or perhaps because the entries draw your eye:
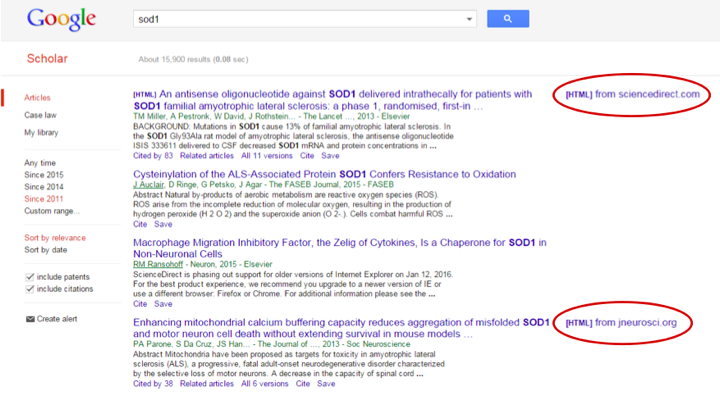
PDF still wins the popularity contest
While there may be reasons that HTML full text is more “powerful” – especially for researchers who need access to high resolution figures or supplemental data sets – the PDF still wins the ‘conformance quality’ (1) award: a downloaded PDF ensures you will be able to read the article later. The impermanent nature of access rights – library subscriptions change, off campus access, a reader’s own job changes – leads to a need to store a local, permanent copy. As Anurag said in the Q&A, “Some downloadable form that is permanent will survive.”
The spread of attention
The ease of finding a great variety of items encourages what Anurag called a “spread of attention”. The spreading is on several dimensions: small journals, new journals, non-English journals, old(er) articles, non-articles (preprints, dissertations, working papers, proceedings, technical reports, patents) all get more attention when they are in the same query space with the “formal literature” that is found in the highly-curated databases.
The “article economy” is enabled by many things in our ecosystem, but the scholarly search engine which finds articles – not journals or issues – is key. The early user experience design decision that each full article would have an address and be on one page rather than be atomized across several is another key enabler. The SKU for an article is a URL or a DOI, if you will; an article doesn’t have several DOIs or URLs. (This wasn’t always the case. Some early scholarly-article web sites had each article section on its own page.)
Users want lots of abstracts and only some full text; metrics should recognize this
Literature review is inherently a filtering process, and abstracts are purpose built to be the distillation of an article. Anurag believes that supplying users with full text when they can’t use it (because the part of the workflow a user is in is the filtering part, not the reading part) is not helpful and slows down the filtering. (There are probably exceptions to this, such as detailed methods searches when the information needed for filtering is not in the abstract.) Similarly, metrics that ignore abstracts are missing a lot of the utility a journal provides to its readers. Anurag encourages COUNTER to add abstracts and PDF downloads as required measurements in addition to full text, gold OA and denials currently emphasized.
Abstracts should now be written for a broader, not just a specialized, audience
Research articles are typically written to the authors’ peers: subject-matter experts in their field. And so abstracts are typically written for the same audience. Relevance ranking in a comprehensive search will lead searchers outside the field of experts to these articles by their abstracts, attracting a larger research readership, giving the authors’ a wider impact. But abstracts written for one’s peers often have jargon (like blog posts for publishers…). Abstracts that are accessible to a broader audience, i.e., researchers in related fields, will help.
Anurag noted that Science and Nature have written broad-audience abstracts well for many years. We see journals beginning to attend to this by adding keywords to articles, and by including impact summaries and “take-home messages”. Readers appreciate these, and they expand the audience while also efficiently helping the broader audience contextualize a paper.
Now on to the Q&A, which was a wide-ranging one.
“What about searching books?”
To paraphrase Anurag again: ‘We need a representation of a monograph that functions like the abstract does for a journal article. This can’t be an introduction or preface, and it can’t be the first few pages –these things aren’t a representation of the whole.’
On the difference between book and journal searching
‘Users expectations are different for these two. When you search books you expect an answer; when you search journal articles, a scholar expects a list of things to read. A book represents late-stage work, not the early-stage work of journal articles.’
You can easily see the difference between these two modalities. Do a search in Google for “San Francisco weather” and the answer pops up: the current temperature and conditions, and the forecast. But for the “weather scholar” there is also a list of sites below the forecast that you can go to if you want to study the topic by reading web pages about San Francisco weather.
“Do you use things previously searched and found for ranking in Scholar?”
Anurag: ‘This isn’t as significant as you think. [Scholarly] queries are long and contain discipline-specific terms” unlike in Google web search.” He adds, “Personalization helps when queries are ambiguous. When queries are detailed and specific, as most Scholar queries are, personalization doesn’t add much.” There were follow up questions on this theme, suggesting disbelief that Scholar doesn’t use frequency, location, etc. as a ranking signal. It doesn’t, Anurag repeated. He encouraged people who can’t believe it to try the experiment of doing the same Scholar queries in different countries, or with different people trying the same query.
“What is the role of the journal in the future?”
To paraphrase Anurag: ‘I have no good answer for that. The journal was a channel of distribution, and this is less important now. It is still important as a channel of recognition. There are three important relevance-ranking signals for a just-published article: Who wrote it? What is it about? Where was it published? The last of these, where it was published, covers many different indications.’
“The goal of Scholar…”
“…is to make it easier for people solving difficult problems to do more.”
Anurag has agreed to address questions about this post that readers put in the comments.
(1) Conformance quality: Quality of conformance is the ability of a product, service, or process to meet its design specifications. Design specifications are an interpretation of what the customer needs.
Discussion
24 Thoughts on "Guest Post: HighWire’s John Sack on Online Indexing of Scholarly Publications: Part 2, What Happens When Finding Everything is So Easy?"
I use GS to study research communities, which may be somewhat different from most users, or perhaps not. In any case the reason for the repeats is often that in reading the abstracts one finds different search terms related to one’s interest. Sometimes this means broadening the search. For example I once started with “author disambiguation” then discovered that a lot of the relevant literature used “name disambiguation.” But sometimes it means narrowing the search, by discovering search terms that more precisely fit what is sought. Related Articles is also good for this. Is there data on the use of RA? The point is that in addition to discovering content one discovers search terms.
There is a huge difference between having the search term appear in the full text, where it may be incidental, and having it appear in the title, where it will be central. For example I recently did a search on “fracking” since 2011, without citations or patents. There are about 13,000 full text occurrences but just 700 title occurrences. The latter is the place to look. Any data on this search distinction?
If finding everything is so easy… By which one can assume that for any given subject, the set of all possible content is listed in a results list somewhere, what do we do with the problem stated by Benedict Evans recently; “That it is no longer possible to hear of everything” that has been produced for a given subject.
(The link is here: http://ben-evans.com/benedictevans/2015/6/24/search-discovery-and-marketing)
This seems to be the central problem now – how to surface what one needs to find, vs what can be found.
I’d welcome your thoughts!
Actually it is still hard to find everything on a given subject, but I have developed a procedure for doing so. As for finding what one needs, that is probably what the complex search patterns GS is finding are all about. I have long argued that the logic of search (and how to facilitate it) is one of the great scientific challenges of our day. We need to understand these patterns as a form of problem solving. This is cognitive science.
Information plenty is a _lovely_ problem to have! Those of us who grew up in times & places of information famine marvel at what has become possible. Just wanted to get that off my chest…
There are three broad classes of search needs. First, when you have a question and are able to convert the question to one or more effective search queries. The challenge here is to find the most useful results for well-formulated queries. This is where relevance ranking of matching articles makes a huge impact. We have come a long way in handling this class – there is of course more to do.
Second, when you have a question but aren’t able to construct effective queries. It may be because you aren’t familiar enough with the research area/direction. The challenge here is two-fold: doing as well as you can ranking-wise with the queries you get and helping users construct more effective queries. Our first step in terms of helping users construct effective queries is automated query suggestion when users create alerts. To see this in operation, search for say, prion protein on Scholar and click on the “Create alert” link. You will see a suggested query which will hopefully work as well in alerts as the original query did on the entire collection (and a sample of results so that you can judge the effectiveness yourself, modify/evaluate alternative queries etc). There is a lot to do for this class.
Third, when you don’t have a question but should have. The challenge here is to successfully walk a tightrope between relevance and novelty. Results provided when there is no query need to still be relevant — so that we are not wasting your time — but not too relevant, because you already know about those articles. Our first step in this direction was the introduction of recommendations based on authors’ public profiles. Feedback from users indicates that it often helps them find articles relevant to their work that they would not have been looking for. There is much more to be done – researchers who with a short publication history, practitioners who don’t publish much any more, shorter term exploratory interests.
Question for Anurag: We have done a lot of work building a discipline-specific taxonomy with the belief that it will help the researcher uncover a level of relatedness not possible with pure keyword searches. Does GS have plans to deploy taxonomies?
Taxonomies are often too broad for answering user queries. User queries are usually more specific than taxonomy terms/labels. Full-text matching & ranking matches user expectations better and usually goes a long way towards returning useful results.
That said, taxonomies may well be useful for the help-me-find-new-things-I-wasn’t-looking-for case. The set of newly published articles is small enough that the broader grouping taxonomies could help identify candidate articles that may be of interest to the user. To be effective, it would need to be combined with relevance-ranking in some way to achieve the relevance-novelty balance. All of this is just speculation on my part though 🙂
Those who were present would have heard me ask the question about books because it is super frustrating not to find scholarly stuff except journal articles in a service called Google Scholar – scholars read books and use data too! That said, Anurag accepted my challenge to look at the way we publish books and work is not going on to have our books covered by Google Scholar 🙂
Taking a somewhat broader view, when we look at innovations in scholarly communication across the research cycle, we observe many big players (e.g. publishers) working towards offering a suite of services where researchers can search, do analysis, write, publish, create awareness and measure impact all within the company’s ecosystem (some examples here: http://goo.gl/Xl8GXr)
Google seems to have almost all of these elements in place already. So… is there ‘Google Science’ suite in the future, enabling a research workflow from discovery to assessment, including some kind of platform for publication/sharing?
Hi Bianca: there are no plans for an end-to-end research workflow system.
There is so much to do to help researchers find all that they need to read & learn from – I described some of the key needs in earlier comments.
anurag
Hi Anurag, Can I ask what your view is of the inclusion of content from so called “Predatory” journals in Google Scholar. Their proudest boast is “indexed by Google Scholar”.
> Abstracts should now be written for a broader, not just a specialized, audience
Should they? or would it be better to add a plain language summary alongside the abstract for the broader audience? It’s my belief that the abstract has sufficient value for its intended / core (academic) audience that we shouldn’t mess with it; specialist language and structure serve a useful purpose for those in the field. But, we can usefully add a simple layer on top of this that will (a) be more comprehensible to non-specialists – or speakers of other languages and (b) further help specialists to skim and scan through more of the literature – a top-level relevancy check before diving even as far as the abstract.
I agree and this is why we’ve been commissioning short, accessible, summaries for our main publications and translating them into as many as 20 languages. The ‘multi-lingual summaries’ as we call them, are freely accessible and get a lot of traffic. We even turned some of them into country-language ‘magazines’ which also proved popular (www.oecd360.org).
Toby Green
OECD Publishing
From whom do you commission the lay summaries, the authors or professional science writers? In my experience, the ability to translate complex scientific concepts into clearly understandable language for the non-specialist is a rare talent. When I was a book editor, we would get weekly submissions from scientists who wanted to write a book about their research, but not a book for scientists, one for the general public. Our usual response was to have them write a sample chapter, which was inevitably either a dull textbook (“DNA stands for deoxyribonucleic acid….”) or just jumped right in assuming a depth of knowledge from the reader that was unlikely to be there. There’s a reason we revere folks like Richard Feynman and Carl Sagan, because what they were able to do is not easy and not common.
So my worry is that including lay summaries is easier said than done, or at the very least, would result in an increased cost, which means increases in subscription prices or APCs depending on one’s business models. It might certainly be worth the extra spend, but I suspect many would balk at any price increase.
David,
we have two in-house writers (ex-journalists) and some of our authors are supported by communications specialists, so a mix of resources to get the work done. Then, we have a network of freelance translators to create the different language versions. But, you’re right, finding people with the talent to convert specialist content to accessible, lay, content is hard because it’s a rare skill. And, yes, it does cost money but we believe it helps expand the market for our content and it certainly helps boost impact which feeds back into winning new research funding – so the benefit isn’t just for publishing, but for the ‘system’ as a whole.
Toby Green
I think you’re right that not everyone can write an entire book for lay audiences, but I’ve been pleasantly surprised by how many people can at least give a few sentences that simply summarise what the work is about and why it’s important. Not every one lends itself to a genuinely mainstream audience but I’d say 99% of the contributions people make in Kudos do make it easier to get a handle on the work in question.
This is a fairly hairy issue. Abstracts play a crucial role in the discovery logic workflow. One of the most common paths (there are many others) is title->snippet->abstract->article. Then too, frequently only only the abstract is read. Broadening the abstract makes it less technical, hence less precise, which may disrupt this flow.
On the other hand, if we add lay or less technical summaries (as Kudos does) the question is how to handle them in the GS search results? Perhaps a new button below, or a link to the right, as is now done for a repository version. Plus they need to be indexed and tied to the article. This is clearly feasible, but it is a significant technical challenge that would require a critical mass of summaries to be worth doing.
Hi Anurag — re books– You’re quoted as saying: ‘We need a representation of a monograph that functions like the abstract does for a journal article. This can’t be an introduction or preface, and it can’t be the first few pages–these things aren’t a representation of the whole.’
Can you be more specific? Would this be akin to a comprehensive “Executive Summary” or…?
An executive summary is probably too long to play the role of an abstract in book discovery.
Hi David: A few points/questions.
1. I can see that the executive summary of a dense monograph would be longer than the summary of a business book called “The One Minute Manager”. But would it necessarily be “too long”?
The length of abstracts is pre-set by customary practice: I find definitions claiming a maximum of 250 words. There is no defined maximum length for an executive summary, but by definition these summaries seeks brevity: their purpose is to describe the whole in as few words as possible.
2. I was using “Executive Summary” in quotes as this form is a recognizable type of summary of a longer document (in contrast to an “introduction” or a “preface”).
Looking at some of the online literature on the topic [(https://goo.gl/G91nGf) and (http://goo.gl/0dSsQ5)] it strikes me that the descriptions of the roles of abstracts and executive summaries mostly demonstrate their similarities.
My question is really, what would we call this thing that’s a “representation of a monograph that functions like the abstract does for a journal article”? Or, lacking a name, how would we describe it? Is it –like– something we’re already familiar with, such as an executive summary, or is it something quite different?
I see no reason why the abstract for a book should be any longer than for an article. When I do a GS search I am offered titles and snippets for both. I then look at promising abstracts to decide which way to go next. That books are longer than articles does not enter into the decision making. It is all about the cognitive workflow.
Thad, I would call it an abstract. In STEM at least the logic structure of the abstract is the same as the article’s — here is the problem, here is what we did, here is what we found and here is what it means (the last being optional). The humanities will be rather different of course, but presumeably there is still a body of reasoning.
Think of it as a 250 word executive summary, if you like. I see no problem here.
Hi David: (a long-ish comment, but…)
Thanks for your replies.
Here’s the somewhat convoluted reasoning swirling around in my head:
– My current project is understanding how metadata can be better used to make books show up in search results: not necessarily to a level beyond what they “deserve”, but when that book is an appropriate search result for a query.
– Anurag is asked “What about searching books?” and he suggests that there should be something other than what’s available to search books today, something that’s “a representation of a monograph” and “that functions like the abstract does for a journal article.”
– It’s that “functions” word that I hoped he would clarify. And that’s why I stressed that the function of an Executive Summary is similar to an abstract. I recommended an Executive Summary on one assumption only: that books are substantially more dense than a single journal article, and the standard 250 word abstract would be of insufficient length.
– You reply with something I’d not considered “That books are longer than articles does not enter into the decision making. It is all about the cognitive workflow” …and suddenly I can imagine that indeed a 250 word abstract, prepared using the “rules” of abstract preparation, might well do the job. (Though equally I can imagine that it would not…It would be interesting to test). (Think, in particular, of monographs that are just collections of 8, or 10, or 12 journal articles, each with an abstract. How would an abstract of 12 abstracts work?)
– The next hiccup for me is: Is Anurag recommending that from now on book publishers (all book publishers? All book publishers of non-fiction? Or only monograph publishers?) engage in a new editorial practice: The book’s editor is to be charged with creating an abstract as part of their work. This would appear in a short section at the beginning of the book labeled “Book Abstract”, in the midst of whatever preface, intro, and ‘about this book’ that the author might also wish to include.
– OK, it’s an interesting idea. The abstract could serve to create a “metadata layer” that would be valuable to search. But because not all books are indexed through Google books, this abstract might not be discovered by Google search.
– But it would be simple to create an ONIX metadata field for the text of abstract, and label that field and include it perhaps as a sub field of . Then it would be up to publishers on their web sites, on reseller sites, etc., to routinely expose that abstract, thereby making the book appear more frequently in an appropriate search result. This would be valuable to the author, publisher and the searcher.
Does this make any sense?


