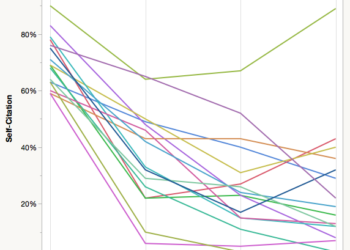
Everyone cites themselves. It is normal, acceptable academic behavior for anyone who has published more than one paper, a way of building upon one’s prior work and the work of one’s colleagues.
So why is self-citation getting such a bad rap these days?

In a recently published paper appearing in the journal, Publications, Justin Flatt and others argue for the creation of a self-citation index for measuring and reporting the extent of author self-citation.
Modeled after the h-index, a single metric that combines author productivity and citation performance, the s-index would calculate author self-citation scores.
Given the extent that citation metrics play in the evaluation of individuals for grants, promotion, and tenure, Flatt worries that self-citation is causing unintended damage to the course of scientific research and discovery. Moreover, the benefits appear to accrue to those who abuse the citation record, further exacerbating gender and status biases.
Flatt’s socioeconomic pronouncements on the damage done by self-citation relies heavily on the findings of a single bibliometric study of Norwegian scientists, which itself, may suffer from confounding effects, that is, confusing causes and effects. Still, we can all probably think of authors who go to extremes to promote their own papers, whether they are relevant to the manuscript or not.
The debate over counting self-citations is almost as old as citation counting itself. Here, in 1979, Eugene Garfield, creator of the first Science Citation Index responds to the criticisms of counting self-citations:
The question of the validity of self-citation is a simpler one. Theoretically, self-citations are a way of manipulating citation rates. On the other hand, the practice of citing oneself is also both common and reasonable […] Since scientists tend to build on their own work, and the work of collaborators, a high self-citation count, more often than not, indicates nothing more ominous than a narrow specialty.
This does not bode well for an index intentionally created for uncovering bad behavior. Given multiple intentions for self-citation, how does one interpret a high citation score? It is simply not possible to distinguish a prolific author in a specialized field from a shameless self-promoter.
Writing for Open and Shut, Richard Poynder presses Flatt on defining self-citation and how such a metric can flag inappropriate behavior. Flatt concedes that there is no scientific agreement. “I think we should come together as a community to try and reach a consensus,” he responds. Nevertheless, Flatt argues that making self-citation data more transparent would allow each discipline to debate the conditions and parameters of acceptability.
This hand-waving toward transparency as a salve that will soothe all conflicts, biases, and inequalities in science has become routine. Given that a self-citation index could cause unintended harm due to its interpretive ambiguity, it behooves Flatt to explain exactly how the s-index would curb inappropriate self-citation.
Many citation indexes currently allow users to calculation h-index scores for individual authors. It is puzzling that Flatt argues for a separate s-index over the option to calculate an h-score without self-citation. The Journal Citation Report calculates Journal Impact Factors without self-citation. (It does not calculate a Self-Citation Journal Impact Factor.)
What the world needs now is not more transparency, but more curation.
To me, the s-index is a symptom of a larger, more insidious problem of vanity journals, which predate the recent explosive growth of open access predatory journals. Even 40 years ago, Garfield envisioned how such gaming could be attempted, detected, and defeated. Substitute “obscure journals” in the following quote with “vanity” or “predatory” and the argument could easily have been written today.
[I]t is quite difficult to use self-citation to inflate a citation count without being rather obvious about it. A person attempting to do this would have to publish very frequently to make any difference. Given the refereeing system that controls the quality of the scientific literature in the better known journals, the high publication count could be achieved only if the person had a lot to say that was at least marginally significant. Otherwise, the person would be forced into publishing in obscure journals. The combination of a long bibliography of papers published in obscure journals and an abnormally high self-citation count would make the intent so obvious that the technique would be self-defeating.
Like Flatt, Garfield argues that transparency working in concert with disciplinary norms would dissuade this type of citation gaming. However, this line of thinking presupposes that anything an author writes would be indexed, its references collected, counted, and used to compute a researcher’s citation score. Under this model, the responsibility for digging, sifting, and filtering the raw data that forms the basis of an author’s citation score is left entirely to the user. It’s hard to believe that a fully-transparent let-the-user-beware model is going to be of any help to anyone.
A fully transparent data model won’t dissuade citation gaming, it will only enable it. What the world needs now is not more transparency, but more curation.
Don’t get me wrong, there is good intention behind the creation of the s-index. My concern is that it won’t solve the abuse of self-citation, largely because the problem is ill-defined, contextual, discipline-dependent, and may do harm to the reputation of some authors. An s-index also does nothing to detect citation coercion or citation cartels, well documented behaviors that have the potential to create much more damage than self-citation (see here, here, here, here, and here).
The simplest solution to a perceived problem of authors gaming their h-index is for indexes to calculate an h-index with and without self-citation. If the two numbers are far apart, it may indicate that something is amiss.
The ultimate solution, however, does not come from the creation of new metrics, but from more rigorous curation of what gets indexed and included in the citation dataset. When abuse is uncovered, transparency is simply not enough. Indexes must be able to sanction and suppress offending journals. Not only would rigorous curation help to preserve the quality of the citation data, but maintain trust in the validity of the citation metrics. Metrics are only as valid as the data behind them.
Index curation requires human intervention, which is vastly more costly than running a computer algorithm, but immensely more valuable.

Discussion
3 Thoughts on "Do We Need A Self-Citation Index?"
If citations to a study are taken as a proxy of the uptake or impact of the study on the scientific community, then wouldn’t it be safe to just disregard self-citations when this measure is used for the evaluation of individuals? Self-citations are natural consequence of an author’s study building on his/her previous work, there is no doubt about that, but they don’t indicate impact in that sense. I cannot impact myself, in my opinion. Or rather, I am impacting myself all the time, but we already know that and therefore it’s not interesting for evaluation either. I should say that evaluation should be concerned with how and to what degree someone’s work impacts others.
There are, however, some use cases that I wouldn’t be so sure how to categorize, for example when authors A and B publish an article X, and then authors B and C publish another article Y, that cites X. Should that be considered a self-citation from the point of view of A? We might consider the absolute choice, that a citation is a self-citation when any of the authors in the cited paper is also a coauthor of the citing paper, or we could choose the author-dependent choice, that a citation is a self-citation for author A only when author A is also a coauthor of the citing paper. This is just to say that how we define self-citation itself can have an influence in the results we get. Probably this has already been discussed, but I don’t know where.
It is fairly easy to calculate the % of self-citations in Web of Science by running an author search and then clicking on ‘Create Citation Report’. The CCR provides ‘total publications’, h-index, … and ‘sum of times cited’ & ‘citing articles’ … each also ‘without self citations’. Calclulating the % of self-citing articles, for a small sample of established Caltech authors, gives values from 1.2% to 2.7%. Given the inherent problems with comparing h-index values, might this be a better measure?
Hmm, with self-citation, some is expected for most authors who have been doing iterative science, where new papers stand upon the ones that came before. But too much is untoward self-promotion through gaming citation metrics. So how much self-citation is too much? In a session on publishing at a recent scientific society* meeting, with a swing of her silver scepter the Editor-in-Chief decreed that 15% was too much. Yet I ran across a paper A macro study of self-citation by Dag Aksnes reporting averages of 17-31% average self-citation across disciplines with chemistry and astrophysics being most enthralled with their own works. (His abstract says 36% which seems to be a mistake). The highest % self-citations occurring in the least cited papers. Aksnes suggests self-citation is a self-limiting problem.
* Homes to the best science journals, Support Science by Publishing in Scientific Society Journals