Editor’s Note: Today’s post is by Dustin Smith. Dustin is the Co-founder and President of Hum, which provides AI and data intelligence solutions for publishers.
Last week Hong Zhou from Wiley published a piece called “Generative AI, ChatGPT, and Google Bard: Evaluating the Impact and Opportunities for Scholarly Publishing”. The piece seemed a little unfair to the robots in question: Bard, ChatGPT, and Bing. It also risked leading readers to incorrect conclusions.
This post will offer two upgrades:
- Choosing the right AI tool for the job
- Prompting well
We’ll focus on a section entitled “Generative AI (LLMs) for Discovery and Dissemination” where Hong tests tools for usefulness with a particular focus on discovery. Zhou ends being critical of ChatGPT. But given how ChatGPT works, it wouldn’t be able to complete that particular prompt. It’s a bit like chiding a two-year-old for not being able to drive a car.
Here is the section:
“To generate personalized recommendations, we used the following prompt for ChatGPT:
“I am a research scientist in NLP area. I am currently interested in large language models like GPT-3. Can you recommend some relative papers about this area?”
ChatGPT recommended five papers published before 2021.
We then asked, “Can you recommend some latest papers?” ChatGPT suggested five more papers:
- “GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding” (2021)
- “Simplifying Pre-training of Large Language Models with Multiple Causal Language Modelling” (2021)
- “AdaM: Adapters for Modular Language Modeling” (2021)
- “Hierarchical Transformers for Long Document Processing” (2021)
- “Scaling Up Sparse Features with Mega-Learning” (2022)
In this example, although the prompt only asked ChatGPT to recommend the latest papers, it understood what topics we were looking for based on the previous conversation. But there is some danger here! If you try to find any of these articles online, you will discover that the papers ChatGPT suggested do not in fact exist. You can also see that because ChatGPT’s model includes no data after 2021, its non-existent suggestions are much less recent than we would expect. Based on these experiments, it is clear that ChatGPT can anticipate human intention and generate human-like text very well, but has some crucial limitations.”
You might conclude that no generative AI tools can excel at this task.
Was ChatGPT set up to fail? If you’re asking a model that’s (a.) disconnected from the internet about (b.) data that’s after its knowledge cutoff, and (c.) do not have a high-quality prompt – you have a recipe for “hallucination” (plausible-sounding responses that are not factually accurate).
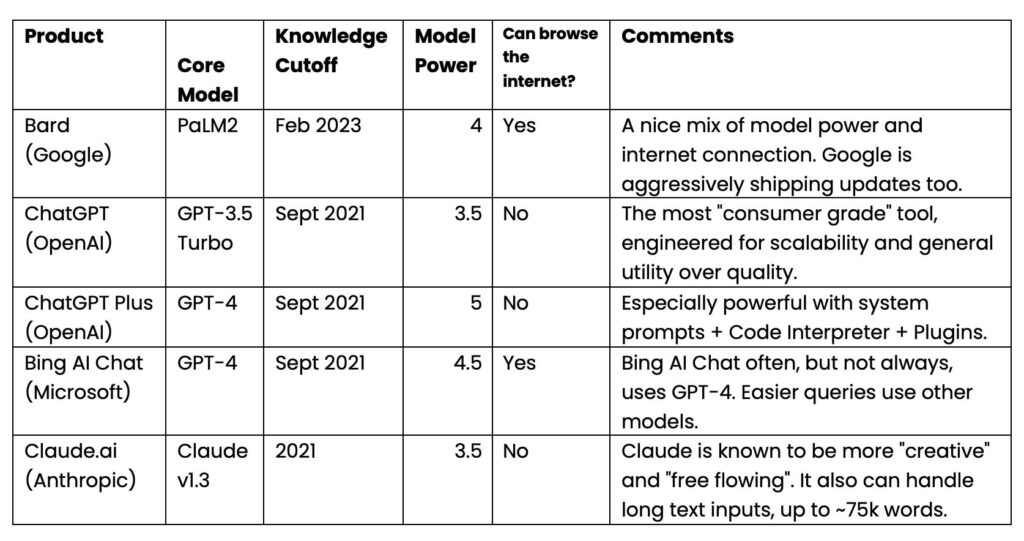
There are two obvious candidates for this particular task: Bing and Bard. Both are connected to the internet!
LLMs – the core models referenced above – distill terabytes of text and code training data into megabytes of intelligence. They may memorize things that appear frequently in training data, but rare and unique items (like an academic paper title) are much less likely to be able to be reproduced. So you’re more likely to get “hallucinated” plausible-sounding paper titles.

Until it is connected to the internet, Chat GPT is a really big brain stuck in a room.
So instead of reading “we fed ChatGPT” think we fed “big brain in a room” the following prompt: I am a research scientist in NLP area. I am currently interested in large language models like GPT-3. Can you recommend some relative papers about this area?
Since Bing and Bard are both internet connected, they can use their intelligence (from GPT-4 and PaLM2 respectively) and search the internet. So you’d reasonably expect them to be able to find recent literature.
And indeed they can! Using Zhou’s prompt, word for word.
Bing (Creative Mode — August 18, 2023)
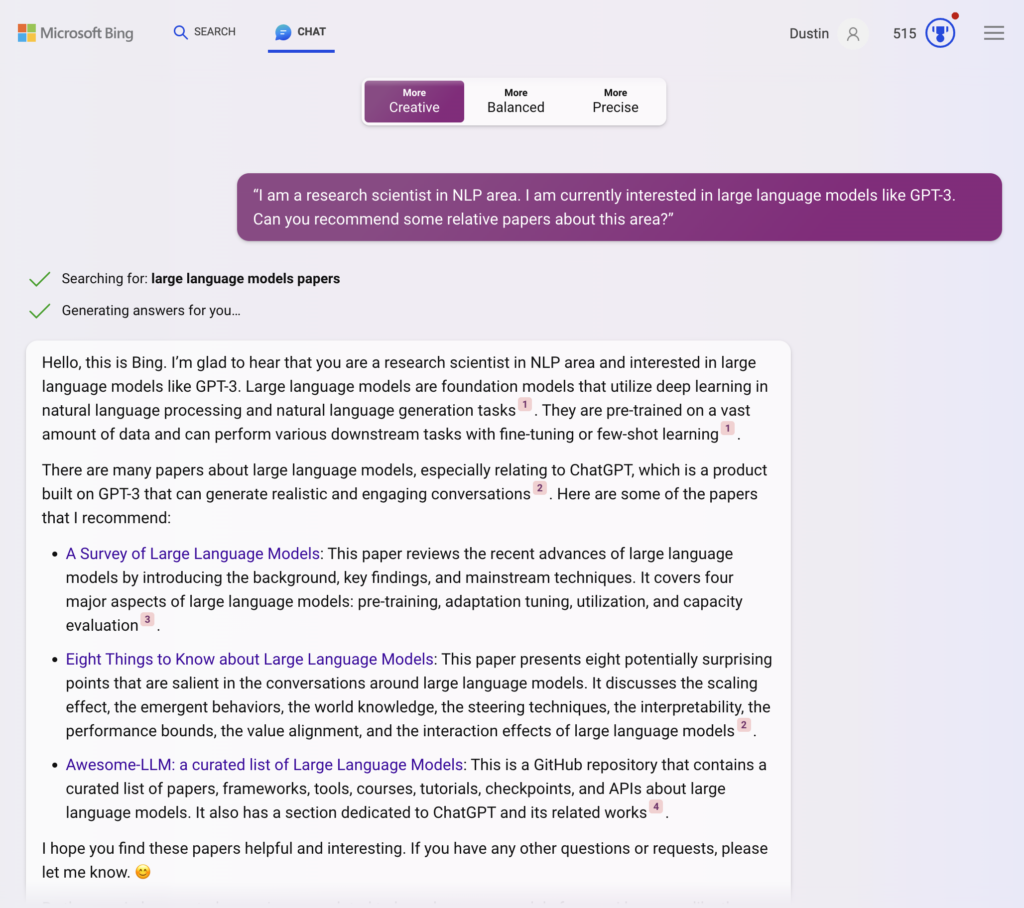
Full prompt and completion here: https://sl.bing.net/k3GGTlF5FVA
Bard (August 18, 2023)

Full prompt and completion here: https://g.co/bard/share/42b5ec45a9ec
The Bing papers are more general and introductory. The Bard papers are more foundational – “Attention is All You Need” kicked off the transformers (the key technology at the heart of LLMs) revolution.
But they work!
Improving the Prompt
In addition to selecting the right tool (Bard or Bing), the prompt could be improved to create better results if this were real-world use by an academic.

The original prompt:
“I am a research scientist in NLP area. I am currently interested in large language models like GPT-3. Can you recommend some relative papers about this area?”

Bing Results (Creative Mode – August 18, 2023)

Bing provides 5 solid choices.
Full prompt and completion here: https://sl.bing.net/hXBqR1NXa9Y
Bard (August 18, 2023)


Bard provides 10 good examples, with more diversity and depth. It also nicely reformatted the table headers and gets bonus points for providing a “Export to Sheets” option.
Full prompt and completion here: https://g.co/bard/share/c54982255170
ChatGPT!!!! (August 18, 2023)

The recommendations were only as current as the knowledge cutoff (2021), but still useful. So while I’d still recommend an internet-connected tool (Bing or Bard) for this exercise, an improved prompt produced the result we were looking for.
The message here: Give the robots a fighting chance! The new wave of AI tools is immensely powerful. But you have to use them correctly to unlock their potential.
This analysis is just scratching the surface. We’ll dive into much more detail in our new whitepaper “The Bright Future of AI”, coming soon.
Discussion
6 Thoughts on "Guest Post – Was ChatGPT Set Up to Fail? Choosing the Right Tools and the Right Prompts is Essential for LLM Discovery"
ChatGPT can be connected to the internet via its ecosystem of plugins https://apiumhub.com/tech-blog-barcelona/chatgpt-plugins-internet-access/. Just get a subscription and try them. Bing Chat and Bard may be connected to the internet by default, but they frequently make mistakes pulling the wrong information on the basis of a URL. No idea where they get that data from in those cases. Here’s some good research on issues like these affecting these bots. Some of them may be solved via the use of better prompts, others may turn out to be ‘unfixable’: TRUSTWORTHY LLMS: A SURVEY AND GUIDELINE FOR EVALUATING LARGE LANGUAGE MODELS’ ALIGNMENT https://arxiv.org/pdf/2308.05374.pdf
ChatGPT (which is the name for the free version) was the subject of the original inquiry, so we limited it to that as well for this piece. At least for the time being it’s disconnected from the internet.
ChatGPT Plus is $20/mo at the moment, and there are a series of scholarly-related plugins including “ScholarAI” which are connected to external sources. I tried Zhou’s original prompt with ChatGPT Plus + ScholarAI and four articles were returned. They were ok:
– Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm (2021)
– Persistent Anti-Muslim Bias in Large Language Models (2021)
– A systematic evaluation of large language models of code (2022)
– Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey (2021)
Apart from which papers were selected, a major critique would be that they’re old in AI years. Things move so quickly. Something like the large language models of code would be missing all the Llama 2 based work, Replit, Bard, etc.
Broadly trying for better tools + better prompts is good, though helpful to be mindful of limitations like sycophancy, factualness, consistency, etc as the ByteDance paper suggests.
Great follow up to a great article. However, I do want to point out something that neither Hong Zhou nor Dustin Smith spent time on:
Using LLMs for information generation or content creation is simply not the most effective or valuable way to utilize these tools. Currently, asking Bard or GPT to generate original content is like trying to cook a Thanksgiving dinner in a microwave.
Will the end product be enjoyable to consume? Probably not.
Does it leave you open to potentially dangerous mistakes? Absolutely.
Is it more trouble than it’s worth? Every time.
Isn’t this sentence a little misleading?
“Since Bing and Bard are both internet connected, they can use their intelligence (from GPT-4 and PaLM2 respectively) and search the internet”.
That implies that it is the LLM that is leading Bing and Bard to search the internet, from the LLM’s ‘intelligence’.
I’d thought that Bing and Bard are programmed to search the internet for answers to every question they’re asked, and that their LLMs are prompted to rephrase what comes back. Well it’s more complicated than that — here’s Microsoft’s explanation of Bing’s architecture https://blogs.bing.com/search-quality-insights/february-2023/Building-the-New-Bing, in which we learn that one’s query is orchestrated iteratively by a separate AI [presumably not an LLM] called Prometheus but essentially, the LLM is a rephrasing wrapper built around a non-LLM search engine, yes?
It’s a similar story, is it not, for the various LLM-assisted search engines – Scite, Elicit, Scopus AI and so forth – which all internally prompt their LLMs to reply *after* an initial non-LLM-powered search, in which the LLM’s internally prompted task is to rephrase the results of the search.
Would appreciate any clarification on this. In my view we must be careful not to imply that LLMs are running search engines if the search itself is being conducted by other algorithmic means.
Richard, it’s an interesting point you raise. Is what Bing is doing more a search engine driving a generative AI to surface results or a generative AI driving a search engine to surface results? It actually prompted some internal discussion today. I do see how you can interpret “search the internet” in multiple different ways, but there is much more going on in Bing/Bard than a traditional search engine producing results and then leveraging a disembodied brain (LLM) to summarize or interpret them.
The machinery around Bing AI is very sophisticated/complicated. They will process and route inbound queries to multiple models (they also likely have a cache of responses so they can save on running completions for repeats). They likely use a hybrid search (keyword + internal search index is also likely powered partly off a separate LLM using embedding search) to tap the search index. They likely pre-process those results before potentially passing to an LLM. Etc.
The cohort you mentioned likely has much simpler setups at present (but I could be wrong!). Dimensions suggest they use “the large language models Dimensions General Sci-Bert and Open AI’s ChatGPT” for the Dimensions AI Assistant (https://www.dimensions.ai/products/all-products/dimensions-ai-assistant/). At a high level: the initial query is performed and returns a set of relevant content or content chunks (using the Sci-BERT model embeddings). That, along with the query (perhaps re-processed) is passed into the prompt. The completion is then returned to the user.
The LLM embedding index search used by Dimensions and others are effectively there to get you in the right ballpark then the generative AI pulls from all the content provided to take it home.
At any rate, the central point remains LLM + internet was what really mattered to be successful here.
Hi Dustin,
Thanks. Having talked to or corresponded with the creators of the Dimensions, Scite, Scopus and Elicit ‘LLM-assisted’ tools, my understanding is that the generative AI part of this pulls from content provided by a separate search. As you say, that separate search process certainly involves AI in itself, as semantic search has now moved on further such that word-embedding models (vector search) are used to get better semantic matchings to the query the user types in.
Also, I can see that the generative AI could in principle be used to rephrase the user’s first query to better set it up for semantic search (though I don’t think that for now this is actually what happens in the search tools I mentioned). In that case I would see the generative side of this as the glue rephrasing natural language inputs into better search queries, and – on the other side – the glue rephrasing what’s returned into more readable answers with citations.
Perhaps this is just a semantic discussion — and doesn’t take away from your central point — but I find it quite useful to try to unpick the algorithms at play. I worry that the shorthand that ‘generative AI searches the internet’ ascribes too many capabilities to the generative AI algorithm itself.
thanks for the discussion!