CHORUS (Clearinghouse for Open Research for the United States) comes from a coalition of scholarly journal publishers and is meant to steward a partnership with federal agencies to provide public access to papers emanating from research they fund. A recent series of presentations from CHORUS offered a progress report and a better sense of what the proposed technologies offer.
We’re now nearly a month past the six month deadline called for in the initial Office of Science & Technology memorandum on Expanding Public Access. By now the first draft plans from funding agencies describing their strategies for providing free public access to funded research papers after an embargo period should have been turned in. There has been little word from the White House on these plans, but as was noted at this past summer’s SSP Meeting, these were meant to be initial drafts, and may not be publicly divulged until they are further refined.
The three main routes publicly discussed in response to the memo are an expansion of PubMed Central (PMC) to all US government funding agencies, the Association of Research Libraries’ SHARE proposal to build a series of interlinked institutional repositories, and CHORUS, a technology-based solution put together by a cross section of publishers. The Association of American Publishers (AAP) has provided startup funds for the project, but CHORUS is an independent project that will not be directly tied to the AAP.
The “PubFed Central” approach offers something of a known commodity to funders, and PMC is seen as a tremendously successful endeavor in broadening public access to research. The downside is the apparent cost, reported at the recent ALPSP meeting to be a $100,000 startup fee to each agency and a $75 charge per paper deposited. SHARE has recently formed a steering committee, but little detail has emerged as to how development and ongoing maintenance costs will be funded.
CHORUS remains something of an unknown quantity with much to prove, but it does offer the upside of being funded by publishers, which leaves research funding to be spent where it should be — funding research. New details have recently been released by CHORUS’ Director of Development, Howard Ratner, giving a better picture of how the service will work, and how it proposes to meet the assurances that federal agencies require for compliance and archiving.
Essentially, articles will be tagged as they’re submitted by authors to identify the funding agencies behind the research. These metadata tags, powered through FundRef, will drive a series of functions for agencies, publishers and others, shown in the slide from below (a pdf version of the full slide set is here). First, the tagged article will automatically become freely available on the journal’s website after the embargo period specified by the funding agency.
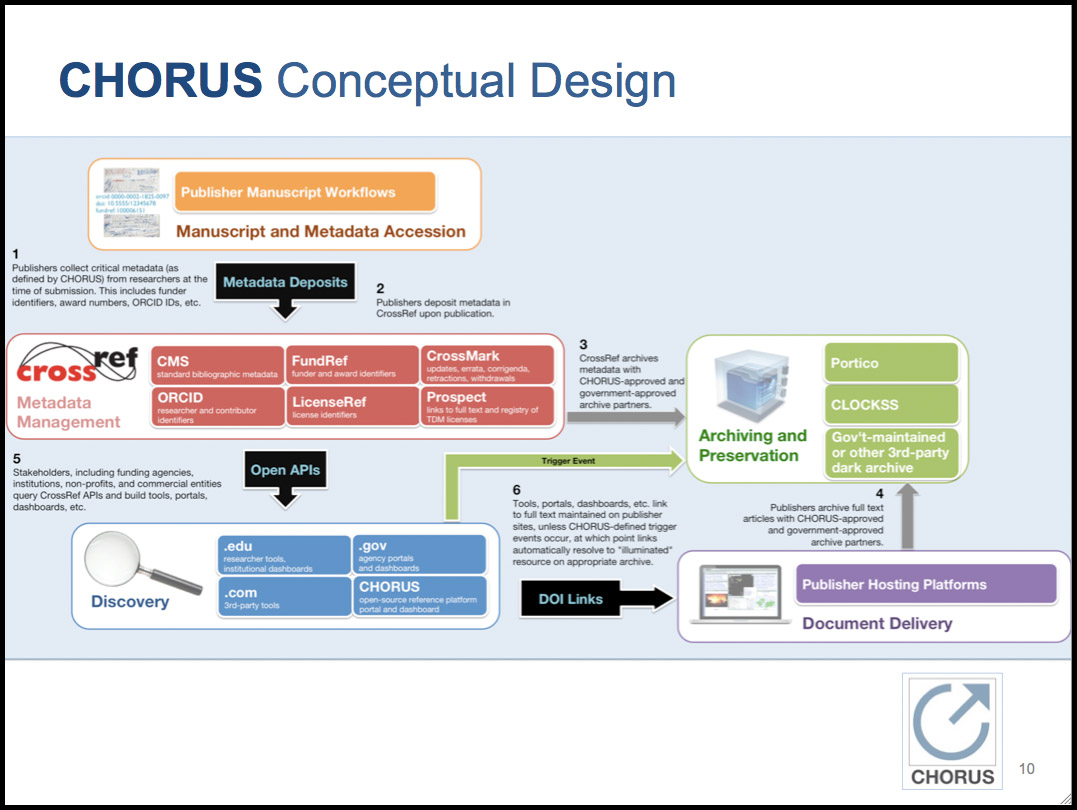
As the paper is published, the tag will trigger an upload of the paper to an archive. These archives will likely include CLOCKSS, Portico, and other archives, either government built and maintained or approved. These are to be “dark” archives, and the papers won’t be made publicly available through them, except in the case of a “trigger event,” such as the paper no longer being freely publicly available on the journal’s website.
This can be monitored and enforced through a CHORUS dashboard available to each funding agency (see slide below). The planned dashboard would show the number of papers that have been deposited for each funding agency, and the status of when they’ll become publicly available. The dashboard also has an audit functionality, allowing the agency to be certain that papers that should be available are available. If a paper cannot be publicly accessed, it sets into motion a chain of actions where the publisher is given a chance to correct the error, and if this is not done, the formerly dark archived version comes to light, and links to the paper are redirected to the archive version.

These are important aspects of CHORUS vital to its acceptance. There is seemingly little trust for publishers among the funding agencies, so it is necessary that archives of the papers exist that are in the control of the agencies, that compliance by publishers is assured through licensing agreements, and that tools exist to continuously monitor that compliance. These safeguards will hopefully set to rest many of the concerns about control that initially greeted the CHORUS proposal.
CHORUS will provide open APIs allowing anyone to build portals showing federal funding and availability of research papers, as well as tapping into the data provided to drive other discovery tools.
The final piece of the puzzle, as called for in the OSTP memo, is to “maximize the potential for interoperability between public and private platforms and creative reuse to enhance value to all stakeholders.” Most have taken this sentence to mean making the content as available as possible for text- and data-mining purposes. This is a much more complex set of functionalities as one has to deal with a wide variety of licensing terms for availability, as well as providing the actual access for these sorts of analyses. CHORUS proposes to address the questions through CrossRef’s Prospect and LicenseRef projects.
Prospect is meant to provide a common API for researchers to access the full text of content identified by DOIs across publisher sites regardless of their business models. LicenseRef will offer a license registry for publishers to transparently show what terms apply and offer clickthrough license agreements if necessary (Edit: See correction and link to further information from Ed Pentz below). Details are in the slides below.
All of this is encouraging — CHORUS has evolved significantly from its original announcement and appears to be making great progress in answering initial critiques and better meeting the needs of funding agencies. The proof will, of course, be in the pudding and this burden still lies with CHORUS. Launches of pilot versions are due in the next few months which should give a good indication of where things stand.
If delivered as promised, CHORUS seems the lowest cost solution for funding agencies that at the same time requires the lowest amount of time and effort on behalf of the researchers in order to attain compliance. Funding agencies will still need a plan to allow compliance for any publishers unwilling to join CHORUS. One other interesting aspect of CHORUS is the open architecture of the system. If it proves successful for the US, it seems readily adaptable to meet the Green OA needs of other funding bodies worldwide.
(Full disclosure: my employer, Oxford University Press, is on the steering committee for CHORUS though I am not directly involved. The opinions expressed above represent my take on things, not OUP’s)

Discussion
14 Thoughts on "CHORUS Comes Into Focus"
David, maybe you could help with something that puzzles me about CHORUS. It seems that the design of CHORUS (as described at the ALPSP conference) starts with the possibility that you could record final accepted manuscript or final published versions on the system. However later on in your description above, the references seem to be only to final published versions. At the LMS, we make a clear distinction between the final accepted mss and the published version. We do this because it is the only distinction left to us when it comes to green open access varieties. The reason is that we have given up hope of governments recognizing appropriate embargo periods on the final published version for mathematics. Our citation half life on the Proceedings is 33 years and no government would consider tying the embargo period to the citation half life of our journals! So we stick to only permitting green access to any version up to and including the final accepted version.
The question is, how could we feed final accepted manuscripts into such a model and keep them distinct from the published version? It looks like we might have to get new DOIs for each mss and store them on a web-based system, mirroring the published versions. If so, the costs would prevent us signing up to such a system.
First, a general point–there’s no direct correlation between citation half-life and subscription. I don’t think this is the appropriate metric to use when trying to make arguments for longer or shorter embargo periods. What we need to look at instead is usage, because that’s what we’re talking about, what’s a fair embargo period that won’t significantly harm subscription business levels where we are charging for usage, not for citation. And as formal policies are introduced, I suspect there will be many challenges and requests to alter the initial 12 month embargo period. A system for such challenges is a requirement of the policy.
As I understand things, CHORUS is designed around making the “best available version” of the paper freely available after the embargo period. The decision on what’s the “best available version” of the paper is going to be up to the individual publishers. The OSTP apparently is satisfied (as is PubMed Central) with the Author’s Accepted Manuscript (AAM) version of the paper–basically the paper in the state that it was accepted for publication at the end of the peer review process, before any editing or further work done by the journal. Many publishers are likely to use this as the version that’s made freely available. Others will use the Version of Record (VOR), the final, published and fully edited version.
CHORUS is being built to accommodate both tracks. You’d have to get in touch with someone at CHORUS (or your publishing platform provider) to get more information on how different publishers are going to deal with the technological and organizational complexities that using the AAM creates over using the VOR. It does raise questions about DOI’s, updates like corrections or retractions, and making sure that citations are accurately counted.
There are likely development costs that will come into play if one takes this route. The question is going to be whether covering those costs is worth retaining the traffic to your journal that would otherwise be siphoned off by repositories.
Thanks David. Although it is early days (and it is someone at OUP who is looking in to this for the journals we have there), and exceptionally high usage is focussed on a few papers, it looks like our usage half life is also over ten years on the Proceedings. There are other bits of evidence, such as the cancellation of subscriptions to the Annals of Mathematics, that suggest that access to the VoR in mathematics will quickly lead to the cancellation of our journals if we permit access to the published version in an organised fashion.
I think that it’s really going to vary quite a bit from field to field. From my understanding, mathematics is one of the fields with a longer usage half life. This sort of evidence is going to be key to the process of extending embargo periods where appropriate for different fields. I think it’s one of the strengths of the OSTP policy that it allows for such variability rather than a one size fits all approach.
I suspect that as things proceed we’ll see some technology platform solutions available for journals that choose to take the AAM route.
As for PubFed Central, have you read today’s paper? Will there be any funding after October 1? In the present political environment, the U.S. Government is NOT a reliable and stable source of funding for such a proposed critical system. And, this is without even considering the remote but frightening possibility of government censorship.
CHORUS has a lot more going for it, but still suffers from being dependent on Government funding. I have no doubt the big publishers will be able to handle the metadata tags and stuff like that. However, this could be a big burden on the little guys.
By hey, maybe we’re on to something! Let the Government copy the papers in our subscription library. Then, when PubFed shuts down, and all researchers are stuck in the fiscal mud, let’s raise our subscription prices and make back the money we lost!
I think the point of CHORUS is that it’s not dependent on government funding. It is essentially a good faith effort by the publishing community to provide a desired service, but doing so in a way that’s optimal for our own needs as well. We can bend to make sure the funding agencies get what they need, and we are offering to cover the costs in return for a system where the traffic to the publicly available papers are found in context in our journals (rather than a third party repository), as traffic is the lifeblood of a journal publisher.
I guess the question about the little guys would similarly apply to all broad community efforts to create shared resources like CrossRef, DOI’s and the like. Are smaller publishers unfairly burdened by these? And as noted, there will likely have to be a track available for those who won’t or can’t join CHORUS. Perhaps it will mean direct deposit of papers into one of the same repositories and public availability of the repository version, rather than the one in context in the journal.
RE THE STATEMENT, “CHORUS … does offer the upside of being funded by publishers, which leaves research funding to be spent where it should be — funding research.” Might it not be more accurate to say that publishers invest up-front funding with the expectation of of a return on that investment. So who is the final payer beyond whom there is no one else to pass this expense? Then where does that final payer get the funds to pay? In order to fully understand these things, we have to follow the money to the end of its journey.
I want to note that this model of money is based on money as a physical artifact that has an end to its journey. Economies don’t work this way. Only in failed economies does money end its journey. In vibrant economies, it gets spent in some manner, either directly or through investment or lending. Does government benefit from all the taxes it gathers from employees at publishing houses? Do universities benefit because editors can send their kids to college?
At a very fundamental level, the better question is, “Is more wealth created if research is funded more robustly, and funds not diverted to paying the government to host articles?” Given the amplification effects research has on economies, I think the answer is yes.
From what I understand, if the OSTP mandated solutions incur costs, it’s up to the funding agencies to cover those costs and the most likely path is taking them out of their research funding budgets.
If the publishers pay for it, the costs will likely be paid through a wide variety of sources. Journals have many different revenue streams–advertising, secondary rights, subscriptions, author fees and more. Different institutions pay for subscriptions in different ways, generally some combination of tuition revenue, student fees, some from grant overheads. So there isn’t the same 1:1 correlation where the funds come directly out of a research budget.
As CHORUS proceeds, publishers may be able to reap some savings from eliminating the expenses they currently spend to deposit articles on authors’ behalf into repositories, which could offset costs as well.
I think one of the major ways publishers would benefit from this is that their online businesses would not be harmed, as they currently are by PubMed Central, which siphons 15-30% of their traffic away when content is posted on PMC and the publisher’s site at the same time. Traffic is the lifeblood of online publishers, whatever their business model.
It’s especially interesting to note that the harm from this current situation seems to hit OA publishers the hardest, as there is no embargo period (so no time they are safe from the effect), and as an analysis I did using data from PLOS showed that PLOS journals suffered a 30%+ traffic shift to PMC, higher than for subscription publishers. This costs PLOS about $75-$100K per year in lost advertising inventory, for example.
For subscription publishers, the effect of these traffic drains on COUNTER reports can skew their value downward.
Simply correcting the deleterious effects from PMC would provide publishers of all types with some relief.
I have a clarification about LicenseRef. CrossRef’s Prospect text and data mining pilot is testing a common API for researchers to request full text from publishers’ websites. The pilot is also looking at a license registry specifically for text and data mining terms and conditions – it’s not a general license registry. The CrossRef slides are unclear on this point but LicenseRef refers to metadata CrossRef will be collecting. LicenseRef isn’t a separate service it’s just a tag () that contains URIs pointing to licenses. We’ll make more (and clearer) information available as these things move forward.
All the gory details on the various updates to CrossRef metadata are here: http://goo.gl/a8dfEj
Thanks Ed, much appreciated. I’ve updated the post to point down to this correction and link.
The primary challenges are legal, not technological. It is hard to give the government something for nothing, especially control. These hairy issues are yet to be addressed and it will not be easy.
PMC’s $75 per paper is a bit of a choker budget-wise. Collectively the agencies are estimating around 100,000 papers per year, which works out to $7.5 million a year. Few if any of the agency scientific communication offices have that kind of money, other than NIH of course. Then too a lot of journals send everything to PMC, not just the NIH funding related articles. If that happened government wide the numbers could be much higher.