We sometimes treat these important aspects of discovery somewhat dismissively, calling them “serendipity.” There is a long and fascinating history to the term itself, but it is currently used to emphasize the chance associated with a happy outcome. In a recent piece, Patrick Carr has noted that “serendipity is problematic because it is an indicator of a potential misalignment between user intention and process outcome.”
Many of the systems that researchers have relied upon for serendipity have become bent if not broken in recent decades. Perhaps the most vital system for serendipity has been the journal title, which bundled together a variety of articles in a general topic area. Browsing through the newest issue would help scholars to maintain current awareness in a field that mattered to them, even if many of the articles were not ones they would have intentionally sought out. In the transition to online journals, content platforms enabled a researcher to subscribe to an email containing the table of contents of each new issue of every journal of interest. It has been widely reported that these table of contents alerts are failing scholars, who feel overwhelmed by the number of them they might wish to retrieve. The system is insufficiently granular, and I would argue insufficiently personalized, to meet their needs. For humanists, stack browsing is also finding its limits, as so many tangible collections are increasingly fragmented and poorly integrated with digital materials. In both cases, suitable substitutes are sorely needed.
With today’s discovery environment being mindfully designed, we should build systems that intentionally bring forward materials that would benefit scholars and not just be grateful for the happy accidents, especially if they are in decline. The question is how best to do so.
When I recently argued that data can and should be used to personalize discovery and bring greater efficiency to research, David Crotty raised some very important questions about whether these systems would yield a decline in serendipity. We fear what one commentator has called a filter bubble, in which almost nothing that we aren’t looking for doesn’t come our way. One sees this all too frequently in simple follower-driven systems, like Twitter, where too many intelligent people only follow individuals likely to share their own opinions, rather than experiencing the full diversity of smart views available on almost any subject. Scholars need discovery systems that allow them to encounter not only the resources they seek intentionally, but also those unsought resources that would benefit their research.
Designing systems to avoid such a filter bubble, and ensure that researchers discover not only the items they are seeking in their core areas of interest, is essential to scholarly discovery. It can be designed into data-rich systems just as surely as it has been designed into earlier information retrieval mechanisms.
Take the case of an academic chemist focused on polymers. This individual wants to keep up to date with virtually everything in her specific subfield exhaustively and in real time to the greatest extent possible. But at the same time, she also might wish to maintain an overall awareness of some of the more important work in adjacent subfields, in methodologies that may be important, and broader yet across the discipline. It is these latter areas where providing enough focus but also enough serendipity is vital.
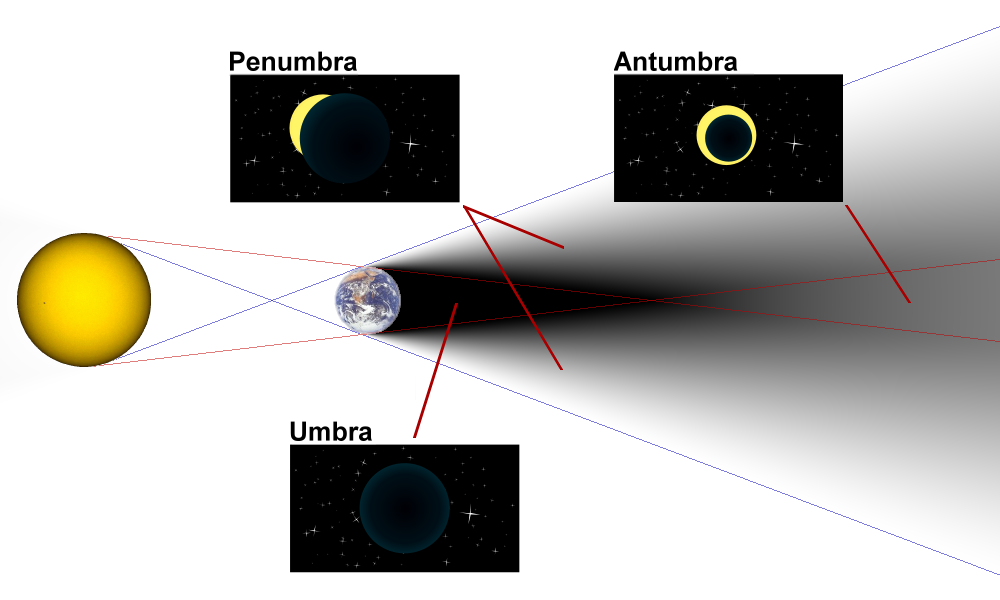
Several years ago, Ben Showers and I proposed adding a “serendipity button” to a personalized information platform. While results in the umbra of the researcher’s interests would appear in a discovery result set as ever, we were beginning to envision mechanisms for incorporating an appropriately-sized selection of especially key results from adjacent and related subfields and methodologies – the research penumbra. One approach would be to apply usage data as a mechanism to gauge the importance or notoriety of an individual item, allowing for materials to be discovered from further afield only insofar as they were relatively important. Such an approach need not be linear, but could also be pursued on multiple dimensions. Ultimately, we were looking for stronger filtering than the journal issue provides while avoiding any sort of filter bubble.
This type of approach underscores the importance of controlling, or at least having access to, data not only about researchers’ interests and practices, but also about research materials and how they are used. A few years ago, usage data were more concentrated with publishers, but due to efforts to make articles freely available online (whether via institutional repositories or the article management tools like Mendeley, ReadCube, and ResearchGate), it is not clear what share of usage data any single party actually possesses today.
Of course, usage data is by no means the only option for engineering serendipity more effectively as a process outcome of discovery services. Recent efforts to provide a reintegrated virtual browsing experience may supplement, if not supplant, stack browsing. But without designing this process outcome more mindfully into discovery systems, we run the real risk of having only umbra, potentially at real loss to scholarship.

Discussion
23 Thoughts on "Personalizing Discovery without Sacrificing Serendipity"
Some time ago I developed an algorithm that finds the penumbra, or at least one version of it. In fact I call it the inner circles method, because it ranks articles in something like concentric circles of increasing conceptual distance from a given topical core. And yes the way that articles spread away from the core is nonlinear, since they go off in different directions. I developed it to help DOE program officers find new peer reviewers, people working in the neighborhood that they do not know about, but it might make a good discovery tool along the lines you mention.
Thanks, Roger, for giving a name to “the serendipity zone”. This is an area of interest for us at HighWire and for most all the publishers we serve.
HighWire’s researcher-user-interviews (conducted largely with Stanford researchers, so some bias)have found related concerns:
“Because of keyword search, I only find what I am looking for” — a direct quote from a senior researcher who recognized and lamented that he was missing what Roger calls the penumbra.
“Search is a solved problem” — another quote from an individual researcher but generally expressing a sentiment of several people that they don’t have a problem with known-item retrieval, and that they don’t want more discovery systems or tools (despite what publishers and librarians and information systems vendors might feel that scholars need). They want help in other areas, though.
The point that journals themselves – via a Table of Contents — used to act as topical filters is important. Is that something to improve and leverage, or is that model/method broken because of the number of places people have to look now? (and that some significant sources don’t work that way anymore, e.g., PLOS One, and many journals using continuous publishing models so not having a “TOC” the way they used to).
What about alerting tools from PubMed, from Google Scholar, and new tools from others? PubMed is primarily keyword alerting; but Scholar in addition has a profile-based alerting service that I’ve found particularly precise (everything it tells me about is of interest), but when I’m working in a new area (one that I haven’t published in, so it isn’t in my Scholar profile), I feel like I’m back to keyword alerting.
Many publishers and platforms have introduced recommendation services of various sorts — e.g., when I researcher is viewing an article, tell him/her what other articles are related. But these don’t attract as much use as we’d like, probably because of where they are in the users workflow (when a researcher is looking at a particular article, they are often in a “grab and go” mode, not looking for more to read). However, when they are looking at lists of articles, that might be the time to surface recommendations, including from the penumbra.
John
One problem is that there are vastly different kinds of discovery, or discovery problems if you like, but these have no names so it is hard to say what a given tool is good for. Alerts suggest an ongoing, known need. Going into a new subfield, which researchers do frequently, is a very different case. Summarizing and citing the history of a problem at the beginning of a journal article is yet another, different case. Exploring the use of a method across distant subfields is another case, and so on. Terms like search, related and discovery are far too broad to be useful in this context.
Thanks for your kind words. I was aware of some of HighWire’s work in this area (and mentioned it in http://scholarlykitchen.sspnet.org/2015/02/05/data-for-discovery/) and am very interested to hear you suggest that we need to get scholarly recommenders in a different point in the researcher workflow. I think that is exactly right. I treasure the Google Scholar “My Updates” but I only occasionally visit that page. Something that was pushed to be at the point of need, more akin to Google Now’s functionalities for news articles and topics I am researching but with a scholarly dimension, would be fantastic.
Lots of food for thought here. I’m wondering if library usage data is part of the story. An academic chemist focused on polymers at Max Planck may want to know recently viewed journal articles at MIT. This brings to mind Harvard’s StackLife for books uses a StackScore, which represents community usage. And, I love David Weinberger’s view that academic institutions need to open up library knowledge to every website/field/person in the form of machine-readable data http://www.researchinformation.info/news/news_story.php?news_id=1847
Library usage/circ data would be a boon to researchers, publishers, and librarians. Rather odd that all these secrets are kept locked up in libraries.
I think there are two main reasons for this (though I’d bea interested in hearing other ideas). First, we in libraries are extremely careful — maybe to a fault — about privacy issues, to the point where it can be difficult to have reasonable conversations about what might be done with anonymized patron data. I think there is a general distrust among us about how “anonymized” the data will really be, even in the face of what should be convincing explanations.
Second, providing the data would involve work, and I think it may not be easy to convince librarians that redirecting staff hours in that direction will provide much immediate and direct local benefit. We have so many projects and programs that _would_ clearly provide such benefit and that are awaiting such redirection of staff hours that this idea ends up getting a pretty low priority.
In an essay titled “The ‘Value Added’ in Editorial Acquisitions” (Journal of Scholarly Publishing, 1999) I identified nine roles that acquiring editors play in the publication of scholarly monographs. One of these roles, which I called “Linker,” is directly relevant to this discussion:
Editors rarely specialize in a subject to the extent that scholars, by necessity, must. Indeed, “dilettante” is a word that is sometimes used to characterize an editor, in contrast to “expert” for a scholar. What acquiring editors lack in depth, however, they compensate for by having a wider vision of the terrain of scholarship, which can provide advantages in espying links among different areas of ongoing scholarly activity. Editors, with their antennae always extended to pick up early signals of new ideas and their extensive networks of individual contacts, play a meiotic role in making connections among different strands of intellectual development and among the different scholars pursuing them. Occasionally this even allows them to link up the efforts of two authors in the same field who are independently pursuing the same line of inquiry, so that they can collaborate on a book.
But an editor’s ability to forge links is not limited to activity within a single discipline. Because many editors have responsibility for acquisitions in a number of fields, they have a vantage point not available to most scholars of being able to juxtapose and relate developments going on within different disciplines. Because of their broad view of the scholarly horizon, editors often have a special fondness for interdisciplinary writing, and it is no accident that university presses publish a great deal of it, perhaps out of proportion to the importance it has within individual disciplines (as judged, for example, by tenure committees).
This meiotic role is usually not very visible to the outsider, but it is valuable in stimulating scholars to pursue lines of inquiry that the structures of reward in their own specialized fields might not otherwise justify. As one observer of university presses put it: “University presses, as a leading vehicle for intellectual discourse, seldom serve as passive gatekeepers. Instead, they actively shape the cultural agenda by defining their role in the scholarly enterprise through listbuilding and aggressive acquisitions methods. By being on the frontiers of scholarship, a press can help direct the cultural agenda, rather than merely reenforce existing values, beliefs, and practices.”
This, of course, relates to book publishing. Is there any counterpart in journal publishing? Might a journal editor play this role? Perhaps, but even a journal editor of a specialized journal is not likely to have the same kind of wider vision that an acquiring book editor has.
Roger — very interesting and refreshing post. Part of the problem may lie in the “relatedness brainwash.” For example, say you were reading a review article on heart failure. How would you feel if you were given recommendations on what to read next and each of them featured another review paper on heart failure? In some cases (e.g, if you were not satisfied with the first review), this might interest you, but more often than not, you’d probably like to move on to another topic that really interests you.
My team and I have built a cross-publisher recommendations widget – TrendMD (www.trendmd.com). We’re already in use by 700+ journals and growing in reach at 3-5% per week – ex. http://jnnp.bmj.com/content/86/4/393.abstract
In addition to using traditional semantic tagging, our recommendation technology uses behavioural click data (i.e. people that have read this, also read X…), and we have recently implemented a “serendipity” variable into our algorithm which introduces a degree of randomness into the recommendation links presented by the widget. We’re always testing our system – typically behavioural click data, for example, can boost the clickthrough rate (i.e. the ratio between the number of people clicking on recommendation links and the number of times they see links) by anywhere from 25-75%, when compared against relatedness (i.e. semantic tagging).
John mentioned that readers are often in the “grab and go” mode. While this certainly may be true for some readers, this also may be a result of traditional scholarly article pages not providing readers with enough value to stick around. Recommendation widgets based on serendipity have been widely adopted in the mass-media publishing space (i.e. Outbrain and Taboola) to solve this problem and have been hugely successful at keeping their readers reading and engaged. Our data based on the performance of the TrendMD recommendation widget on scholarly publishing sites is showing the same.
Serendipity is particularly important in scholarship. I think history has taught us that the most important scientific discoveries often arise from integration of disparate academic disciplines. Therefore, it’s important we design discovery technologies that encompass serendipity and push content to researchers that is outside of their “filter bubble.”
Thanks for sharing all this. I wonder if there are a number of slightly different definitions of serendipity at work here. Can you say a little more about the ‘serendipity variable’ and its ‘degree of randomness’?
We define serendipity as finding a relevant/interesting piece of content that you otherwise would not have found with using a traditional keyword search, and/or keyword alerting system. I imagine you are defining serendipity the same way?
Our recommender system has 3 broad inputs — see this diagram for details: http://i.imgur.com/IqyFKr8.png
We tested the effects of placing semantically less related links in place of more related links and looked at the clickthrough rate (CTR) as a primary outcome. Placement of semantically unrelated links (but still relevant as determined by audience click behaviour) yielded a 24% increase in CTR. Here are more details on the methodology and data: http://www.trendmd.com/blog/most-related-most-interesting/
Paul, I would say that your work is important but your “relatedness brainwash” argument may be overdrawn. The extent to which semantic relatedness (such as term vector similarity) equates with interest depends on the nature of the search. If you are trying to explore a subfield or see who is doing what in the neighborhood, etc., it will be very interesting, otherwise probably not.
Buy the same token your use of the “people who looked at A also looked at B” data will be interesting in certain search cases, but not in others. (I would also expect it to be close to semantic similarity in most cases. It certainly is in the Amazon book case.)
In other words, what is interesting depends on the specific search problem. What we need are ways to match recommendations with search problems, otherwise they tend to be distractions. You are certainly correct that semantic relatedness is not always of interest.
Also, given the algorithmic nature of your recommendations I am not sure they count as serendipity. But then “serendipity” is not a well defined concept. I think of it as “a chance encounter that produces a useful result” but what is a chance encounter?
Hi David,
Thanks for your comments. I completely agree with you — what is deemed “interesting” is highly situational. That said, I think one has to be very careful when speaking of “interest.” Interest must be defined objectively — i.e. the clickthrough rate [CTR] (which is equal to the number of times a recommended link is clicked, divided by the number of times it is seen). The higher the CTR, the more engaging or “interesting” a recommended link was.
Using “people who looked at A also looked at B” may sometimes yield results similar to semantic relatedness, but often, the results are quite different. In our network on BMJ for example, we’ve found many cases of semantically unrelated papers segregating together (i.e. papers on obesity for example tended to segregate with papers on antibiotic use and gut bacteria — this is a hot topic right now — microbiome research).
This is no different from Amazon (i.e. these recommendations are not semantically related). See screenshot here: http://prntscr.com/6o6fmw
Finally personalization is another input that can be used for matching recommendations with “search problems.” For example, if user A tends to click more (as measured by CTR) on semantically related links vs behavioural matched links, we show user A more of related links. As we collect more data, we are able to offer this type of personalization experience for more users.
In an ideal world, perhaps there would be different recommender systems for different use cases. However, given the limited “real-estate” available on any given article page, a publisher ought to select the recommendation type that yields the most engagement/interest from the audience. Based on our data, dynamic, audience-responsive recommendations, while certainly not best for all, leads to a far higher average CTR (and therefore utility/interest) than traditional semantic-based recommendations.
Indeed, Paul, I am inclined (with little empirical evidence) to think that semantically related content speaks to a relatively rare sort of search, one in which the user is trying to understand a subfield, neighborhood group, etc. However I think the Amazon set you linked to would all show up as closely semantically related, because all are about reasoning, so there would be a lot of common technical language.
Agreed, David. Regarding the Amazon recommendations, while they may look somewhat semantically related to you or I, we have no idea if a semantic-based recommender system would show these specific book titles (i.e. there are likely 100s of other books in Amazon’s database that are also semantically related).
Point is, there is presumably a strong reason why Amazon utilizes behavioral click data + personalization (i.e. collaborative filtering – http://en.wikipedia.org/wiki/Collaborative_filtering ) over a semantic-based recommender system — the former, emprically, must perform better at increasing discoverability (and revenue). Our data from 700+ journals (across academic disciplines) using our widget, suggests the same to be true in terms of enhancing discoverability of scholarly content.
Paul, I do a lot in semantic relatedness, in fact my inner circles algorithm is based on it, and those titles are definately closely related. But you are right that there are probably a few hundred other closely related titles. The point then is that the “people who bought A also bought B” filter will typically simply narrow the semantically related group. It is very useful but it will not add another dimension. Thus your “relatedness brainwash” metaphor may be overstated. I have never seen a case where the Amazon “also bought” list returned items on a different subject, although I imagine it sometimes happens.
David, respectfully, I disagree. Semantic relatedness, collaborative filtering (i.e. people who bought A also bought B) and personalization are 3 mutually exclusive processes that each build on each other and add different dimensions to recommended article sets.
I’ll illustrate this point with a recommended articles set on Gut – a BMJ journal currently using the TrendMD widget (below abstract) – http://gut.bmj.com/content/early/2014/06/10/gutjnl-2013-306578.abstract
Here is what the general audience currently sees: http://prntscr.com/6oex8t (this is likely the widget output you will see — unless you have clicked on one of our recommended links in the past.)
The output of the widget here is based on a) semantic relatedness, and, b) collaborative filtering (i.e. people who read A also clicked on B).
The current avg. CTR on the generalized audience widget is 3.2% and relatively steady. CTR = number of times users clicked a link on the widget divided by the number of times the widget was viewed.
Here is what I currently see: http://prntscr.com/6oexpr
Notice that the recommended article set here is different from what the general audience currently sees. The output of the widget here is based on a) semantic relatedness, b) collaborative filtering (i.e. people who read A also clicked on B), and, c) personalization (based on cookie data collected by TrendMD – what I have clicked on in the past). Note: I often read about literature related to the microbiome — and the recommendations reflect this.
The current avg. CTR on the personalized audience widget (i.e. for users TrendMD has cookie data for) is 4.1% and relatively steady.
Here is what the general audience saw approximately 3 weeks ago: http://prntscr.com/6of8mf
Notice, again, the recommended set of articles is different from what the general audience currently sees and from what I currently see. The output of the widget here was based solely on semantic relatedness.
The avg. CTR on the generalized audience widget based just on semantic relatedness was 1.4%.
The 3 different CTR’s illustrate the degree to which more data from different inputs can make recommendations more “interesting” to readers and therefore more valuable to publishers. And even more importantly, the larger the set of articles, the more impact collaborative filtering (i.e. people who bought A also bought B) and personalization have on optimizing recommended link placements and increasing the CTR, when compared to semantics alone.
My point is, traditional scholarly content recommender systems stop at semantic relatedness (i.e. the “relatedness brainwash”), but this is a mistake. Doing so not only limits the value to the reader, but also causes the publisher to miss out on driving more article discovery.
And with regards to Amazon — please see this interesting article on how their recommender system works (and how two people looking at the same product or book may see completely different recommendations).
http://fortune.com/2012/07/30/amazons-recommendation-secret/
The funny thing, Paul, is that I have been trying to agree with you from the beginning. My objections a merely technical and probably not worth the ink. As I said in the beginning, your work is important, and that is what matters most.
Roger, I was very influenced by James Evans’s brief 2008 piece on online searching and the narrowing of research/ scholarship (http://www.sciencemag.org/content/321/5887/395.full.pdf?keytype=ref&siteid=sci&ijkey=TZOmPCveC0Kis) . You may have had this in mind or perhaps more likely the work you’re citing supersedes it! In any case, he was writing about science, but I wonder about the same for the humanities. Research is a very human endeavor– it’s about curiosity. I like the serendipity factor a lot and it sounds more elegant than the stumbling-across factor, but I think the latter is important, too. The things you didn’t intend, and then follow, if not for the current project then tucked away for the next.
But can you engineer this? My gut says no. Then I considered how the libraries I’m visiting this week in London, all of them early modern and inviting all sorts of delicious stumblings, are engineered, too– that is, there is nothing natural in the arrangement of the information. Thus the serendipity you might be able to engineer now will be of a very 21st century sort.
Karin, I’m not sure i would distinguish between serendipity and stumbling-upon. In either case, I think systems can be designed to make it more or less likely for a researcher to find something that will be relevant for them, now or for the future.
From early modern to the 20th Century, librarians designed serendipity into larger and larger collections of materials (see https://en.wikipedia.org/wiki/Library_classification). I am confident we can do even more than this using digital tools for personalization.



{kind=link}