Though often used in a pejorative manner, the concept of the “ivory tower” is based on a separation from the concerns of the everyday–the idea of academia serving a higher purpose than the rat race of business. Last week Rick Anderson wrote about the higher standards of behavior required from scholarly publishers, and watchdogs continually call out any deviation from the strict rigor that characterizes academic research itself. As technology startups continue to hold more sway over scholarly communication, should we similarly hold those companies and their business practices to the same high standards? Academia.edu’s recent marketing campaign offers an interesting case study.
In the era of the app, everyone is a developer. The lure of the Silicon Valley gold rush draws in more and more former researchers. Given how rare academic jobs have become, the modus operandi for many leaving graduate school is to draw from one’s limited experience, to focus on one part of the research process that was found to be difficult, and to create an online service to address it. Suddenly a startup business is born. Some of these businesses are bad ideas, many are redundant, yet some few offer interesting potential new directions.
Profit is a powerful motivational tool–it’s why in the US we have the Bayh-Dole Act which allows researchers and their institutions to own the intellectual property produced from taxpayer-funded research. The for-profit startups are where much of the interesting action can be found in the world of scholarly publishing. There’s nothing wrong with patronizing a for-profit service, but should we ask that such services live up to our community standards?
We rail against predatory publishers, just as we frown upon journals caught gaming the Impact Factor. And so we should. But shouldn’t we take just as stern a look at misbehavior from startups that look to play a part in the scholarly community? For example, a company offering researchers an increase in citations through use of its service (a service which seeks to profit from the data it aggregates about its users), with no evidence to support such claims? I am of course referring to the marketing campaign built around the flawed and un-reviewed study commissioned by Academia.edu discussed yesterday in the Scholarly Kitchen.
For a researcher to gain credibility, their work must go through peer review. Whether the journal reviews for significance or simply for accuracy, one key question must always be answered: are the conclusions supported by the data? Here we have a company asking for the trust of the academy that wasn’t willing to follow that one guiding principle.
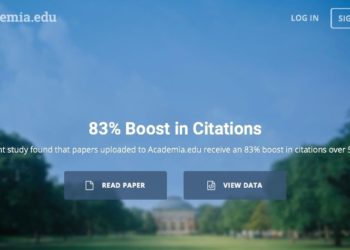
The problem is seen in the marketing campaign promoting the study, which glosses over even the authors’ (Academia.edu’s own employees!) more cautious conclusions. Compare the following two statements:
“While our study is observational, and it is difficult to conclude a causal effect, we do find the citation advantage is substantial even after controlling for some potential sources of selection bias.”
And…
“A recent study found that papers uploaded to Academia.edu receive an 83% boost in citations over 5 years.”
The first statement comes from the research study itself and while problematic given the flaws in the study, it at least clearly acknowledges the lack of proof of any causality whatsoever. The second statement, used in Academia.edu’s advertising campaign and on the homepage of their website essentially promises the reader that if they use this product, they will indeed receive a free lunch.
If we are deeply skeptical of researchers who practice “science by press release” then what are we to make of Academia.edu? They sponsor a study and rather than submit it to peer review, they send out it to millions of customers, and feature it in a widespread public relations effort including articles in major mainstream publications. A quick look at the data shows a major flaw in the study, but the cat is already out of the bag.
A better case for the dangers of replacing pre-publication peer review with post-publication peer review could not be made.
We would drum any scientist who tried to pull a fast one in this manner out of the academy in a heartbeat. Shouldn’t we hold startup companies, particularly one that, “wants to become a full-fledged academic publisher” to the same standard?
Even if any of the supposed citation advantages of various products that have been touted were true, they are short-lived at best. If they actually offered a cynical but effective cheat code for citation, then everyone would sign on and the playing field would quickly once again become level. But venture capital investors only need to think in the short term. Build it up and sell it off, let the long term be somebody else’s (or everyone else’s) problem.
Silicon Valley, and the venture capital business model runs on a very different set of principles than the academy, and ultimately serves different masters. The question one must always ask when dealing with any private interest on any level is, as Jason Kottke recently pointed out, “who’s the customer?” For a startup, the focus is on building value for the company’s investors rather than serving the needs of the users or the research community.
We often complain about the Impact Factor, particularly that it lacks transparency and reproducibility, part of the consequence of relying on a megacorporation owned mostly by a holding company. Yet the suggestions for new metrics are often just as privately-owned and opaque. So too efforts by startups to create systems for peer review credit, peer review itself, discovery, article sharing, social bookmarking, making public and archiving research data, and so forth shift academic functions further into private hands and behind closed doors.
When we rely on Google or Google Scholar, we need to be aware that the main purpose of Google is to serve the needs of advertisers. Google shows us what its advertisers want us to see, not the best objective answer to our queries. What portion of the scholarly literature effectively disappears from view when Google shifts its algorithms to better serve the needs of those advertisers?
If we are to build a system of career credit and reputation assessment that uses social media like Facebook and Twitter, we must again acknowledge that those systems are not designed to be transparent, consistent, or fair; rather that they’re designed to maximize the data they collect for the benefit of advertisers. As the users, we must understand that each of these companies actively degrades the user experience for the benefit of its real customers.
Given the ever-increasing number of entrants into the market, scholarly communication remains a strong draw for businesses. The academy is essentially in the driver’s seat here and has the power to set standards for what is acceptable.
Can’t we do better than this?

Discussion
16 Thoughts on "Academia Versus Academia.edu: Should Tech Business Needs Trump Scholarly Culture?"
How is the academy in the driver’s seat, such that standards can be set for business practices related to scholarly communication? What do you have in mind?
The academy is in the driver’s seat because this is a buyer’s market. There are scores and scores of companies looking to serve these niches. Why not carefully select only companies that offer the transparency and accountability that we demand within the community? This can be done on a personal level and on a greater administrative and official level.
I guess I am asking about specific mechanisms, because that is something I study. Are we talking about blacklists and boycotts? Administrative or official rules, if so by whom? I agree that sending out 20 million emails promising a benefit that may not exist is a bad thing, but what is the proper control?
I suppose it depends on the level where one is looking. On a personal level, I’d like to see more analysis and selectivity on the part of researchers joining networks–take a close look at the network and its practices, are they things you support? Joining means publicly signing your name to a company which can be seen as an endorsement. Are you willing to publicly endorse this thing?
On a higher level, we’ve seen funding agencies setting policies that govern publisher behavior, so I don’t see any reason why they couldn’t engage similarly for other types of businesses. Agency X will only consider metrics from companies that meet certain standards for scholarly behavior, transparency, reproducibility.
This may be nit-picking, but I don’t see funding agencies setting policies to govern publisher behavior. They are setting policies to govern author behavior. The authors are being told what they have to demand from the publishers. No one is holding a gun at a publisher’s head and saying, Publish this my way or else! Publishers can always walk away, as can libraries when faced with terms they find unattractive. Interestingly, no one appears to be walking away.
Do you think it’s a viable option for a journal to turn away the majority of its authors? For example, most of the medical journals I work with publish an enormous number of papers from NIH funded authors. If I decide not to follow the NIH’s requirements, then my journal shrinks in size by at least half and I lose many of the higher quality papers.
Yes, I can walk away, but that walk will likely take me to the unemployment line.
Agree entirely. The funding agencies have uncovered leverage in the marketplace. But they do not “govern” publishers. It’s that metaphor that I am taking exception to.
The problem is seen in the marketing campaign promoting the study, which glosses over even the authors’ (Academia.edu’s own employees!) more cautious conclusions.
To be fair, the person who analyzed and wrote the paper was not an employee of Academia.edu, but an outside consultant, Carl Vogel @slendrmeans , who, I strongly believe, did an excellent job, given the data he was sent. He treated the data cautiously, fairly, and objectively. It was an exemplary paper based on flawed data.
I don’t believe that the authors who built the dataset knew that they were creating a dissimilar control group. I imagine they were just working with poor metadata, entered manually by Academia.edu authors over time, and without DOI’s and reliable metadata, the best they could do was to match the journal and year of publication. I believe this was done in good intent.
I also believe the company’s marketing group was doing their job in pushing this study out in the way they did and it was not dissimilar in any way to NPG’s open access study (see: http://bit.ly/1kUHNBs ).
Lastly, Academia.edu made the dataset freely available. Without it, I could not track down the cause of the paper’s problem. Granted, making the dataset available was also a rhetorical tactic to strengthen their claim (i.e. we are so confident in our results, here is our dataset to prove it!). In the end, if I’m to wax philosophically about it, this is science working at its best: A bold truth-claim is made, it is publicly challenged and disputed based on data. The paper didn’t get published in a reputable journal, didn’t need to be retracted. No editor or assistant professor or PR director or the public were harmed in the process. Maybe we’re making too much of this?
I have no issues with the study itself, or the way it was performed and written up (other than the obvious flaw in the dataset that skewed their results). The biggest issue I have is that in the marketing of the study, the company violated the most sacred tenet of the research community–don’t make claims that the data doesn’t support. This is unacceptable from a company that claims it wants to become a full-fledged publisher.
Second, I have a problem with running a worldwide public relations campaign based on a paper that has not been peer reviewed. This is the major problem that a move to post-publication peer review creates–the world sees the incorrect results but only very few will ever see the correction. If a scientist put out an unreviewed paper that showed a correlation (but no causation) between two health factors and then did interviews claiming that activity X caused condition Y in major national magazines and ran a huge email and web campaign with those same claims, we’d have a massive health scandal on our hands.
How many researchers will join Academia.edu as a result of this campaign and how many will put themselves in legal jeopardy by uploading papers in a manner inconsistent with the legal licenses they’ve signed? How many investors will flock to put their money into a company based on this inaccurate reading of an inaccurate study?
Why shouldn’t the academy take the system that it bases career and funding decisions upon seriously? Why shouldn’t academics be careful in deciding where they will put their faith and upon which businesses they will rely?
David,
Great post. But can you provide some evidence to your statements:
“When we rely on Google or Google Scholar, we need to be aware that the main purpose of Google is to serve the needs of advertisers. Google shows us what its advertisers want us to see, not the best objective answer to our queries. What portion of the scholarly literature effectively disappears from view when Google shifts its algorithms to better serve the needs of those advertisers?”
Firstly, Google Scholar contains no advertising, nor does it report any profits.
Secondly, while Google certainly makes its revenue from advertisers, help me understand how you arrived at your conclusion that ” Google shows us what its advertisers want us to see.” I would argue that the complete opposite is true. If Google showed users irrelevant “sponsored” results, no one would use Google. Google has built it’s success by providing immense value to users. The more Google keeps users engaged, the more they can monetize off user traffic and data via targeted advertising. So Google is clearly incentivized to provide value to users.
In the concluding paragraphs of your post, you then state, “As the users, we must understand that each of these companies actively degrades the user experience for the benefit of its real customers.”
Again, there is a fine balance between “actively degrading the user experience for the benefit of its real customers.” and serving “fake customers” (i.e. users). If Facebook did not serve its users, users would stop using the platform, and Facebook would be unable to generate advertising revenue. So again, Facebook, like Google, is clearly incentivized to provide value to users…
I hate to be snarky, but it’s a little ironic that you’re calling out Academia.edu for pushing questionable data, yet in the same post, you make rather strong and sweeping judgements/conclusions without providing any evidence to support your statements.
Hi Paul,
Due to the nature of the blog format, one can only go so deeply down the rabbit hole on any particular statement, but that’s one of the reasons why we have comments, for those who wish to dig deeper. And for the record, the post above was about twice as long in draft form before several colleagues helped me cut it down to size.
In response, I’ll start with the well-known homily, “if you’re not paying for something, you’re not the customer; you’re the product being sold” (originally from here: http://www.metafilter.com/95152/Userdriven-discontent#3256046). This is one of the primary business models found on the internet. Failure to recognize this can get one into trouble, and it’s a subject we discuss frequently on this blog (here’s an example from 2013 http://scholarlykitchen.sspnet.org/2013/01/24/mendeley-connotea-and-the-perils-of-free-services/).
When one thinks about Google, one must be cognizant that greater than 90% of their revenue comes from advertising (http://www.zdnet.com/article/apple-google-microsoft-where-does-the-money-come-from/). That’s what pays the bills for everything at Google, including self-driving cars and Google Scholar. 82% of Facebook’s revenue comes from advertising (http://www.ritholtz.com/blog/2014/02/how-does-facebook-make-its-money/), Twitter 89% (http://moneymorning.com/2014/09/05/how-does-twitter-make-money/). If you consider these companies to be anything other than advertising companies, you are not accurately understanding their businesses.
The very nature of having an advertisement-based business model means you are actively trying to distract users from the content they came to see in order to get them to engage with your advertisers.
Does Google/Facebook/Twitter show us what the advertisers want us to see at the expense of the objective information we’re seeking? Of course. The same goes for promotion of their own products and services over those from other sources. Here’s a long list of examples:
http://www.seobook.com/excuse-me-where-did-googles-organic-search-results-go
http://trak.in/tags/business/2013/10/28/google-turning-evil-advertisements-push-actual-search-results-fold/
http://techcrunch.com/2008/10/24/do-no-evil-google-uses-shady-ad-tactics-to-edge-out-competitor/
http://www.edbott.com/weblog/2012/03/at-google-advertising-is-crowding-out-search-results/
http://marketingland.com/once-deemed-evil-google-now-embraces-paid-inclusion-13138
http://www.theguardian.com/technology/2015/apr/14/european-commission-antitrust-charges-google
http://money.cnn.com/2015/01/04/technology/google-censorship/index.html
http://www.marco.org/2014/03/15/worse
http://scholarlykitchen.sspnet.org/2014/01/24/the-problem-with-facebook/
https://medium.com/a-programmers-tale/the-facebook-experiment-has-failed-lets-go-back-f7b8c66109ea
http://www.cnet.com/news/why-a-hyper-personalized-web-is-bad-for-you-q-a/
https://www.linkedin.com/pulse/20140417160058-3973565-will-the-new-ad-formats-ruin-twitter
http://techcrunch.com/2014/11/26/twitter-app-graph/
http://techcrunch.com/2012/09/18/twitter-changes-are-now-all-about-advertisers-not-the-users/
In addition, there are other business practices that are in conflict with the standards espoused by the research community. Facebook, for example, seems to take the concept of informed consent rather lightly:
http://www.slate.com/articles/health_and_science/science/2014/06/facebook_unethical_experiment_it_made_news_feeds_happier_or_sadder_to_manipulate.html
http://readwrite.com/2014/10/03/facebook-research-ethics-informed-consent
Facebook also makes its users unwittingly serve as advertisers for products (can you imagine if a pharma company could use your name and likeness to promote its new drug if you published a research paper in that field?):
http://nbergus.com/2012/02/how-i-became-amazons-pitchman-for-a-55-gallon-drum-of-personal-lubricant-on-facebook/
Scholarly communication is based on a notion of the “permanent record”. Journals are required by subscribing institutions to offer perpetual access to content and to use robust archiving services like Portico, LOCKSS and CLOCKSS. Yet so many of these web-based services are ephemeral. Google drops services continually, with no archiving of content available:
http://googleblog.blogspot.com/2011/11/more-spring-cleaning-out-of-season.html
If they are to be part of the scholarly discourse, can we allow the scholarly record to disappear in this manner? There are already concerns that Scholar is becoming less of a priority and may not be long for this world:
http://www.roughtype.com/?p=1583
To be clear also–the Scholarly Kitchen is a blog based on opinions–it is not meant to be a formal scholarly publication, nor are we asking the research community to adapt their practices to include use of our blog in order to drive our shareholder value or profits (we have neither shareholders nor profits, nor revenue of any kind). We are deliberately outside of the academy as it allows us to objectively observe and critique its practices. As is clearly stated on our site, the opinions expressed here are solely the personal opinions of our bloggers and in no way represent our employers, some of whom are more directly connected with the academy. As an example, we have deliberately decided not to register and include the code for ResearchBlogging, a key source of information for altmetric providers. The Scholarly Kitchen, unlike the services described in the post above, is not asking for the business (or money or data) of the academy.
“Why shouldn’t the academy take the system that it bases career and funding decisions upon seriously? Why shouldn’t academics be careful in deciding where they will put their faith and upon which businesses they will rely?”
Not an invalid question, but one that could be (and has been repeatedly) pointed at the problem of upwardly spiraling journal costs, etc. for quite some time. Academic authors are irrational economic actors. Insulated from the real costs of publishing in top journals, they privilege social capital associated with brand.
I see an homology here. If the currency on offer and in demand is increased “impact” or citation, authors will go for it without much concern for deeper deleterious consequences. That being said, I see the criticism of Academia.edu’s practice (and the questions regarding the shoulds and shouldn’ts of academic decision-making) being just as applicable to current journal publisher practice. There is a difference in the way the former markets itself, as you rightly point out, and that criticism is valid. But, your call to action seems ironic since (in my view) an academy that took the system it bases career and funding decisions on seriously… an army of academics being careful in deciding where they put their faith would expect journal publishers, including Oxford, to lower the rent.
Hi Aaron,
I made much the same point in response to Rick Anderson last week when we were discussing the standards that the academy holds (and should hold) publishers to:
http://scholarlykitchen.sspnet.org/2015/05/11/should-we-retire-the-term-predatory-publishing/#comment-153392
As Rick responded (and as you note), the market is somewhat distorted because those setting the policies are different from those who pay for the journals and they are both different from those who actually use the journals.
And for the record, at Oxford we are very conscious of the pricing needs of libraries and strive to find a balance between sustainability for our society partners and affordability for libraries. As a recent study showed, we charge a small fraction of what our commercial counterparts do when considering cost per citation:
http://www.econ.ucsb.edu/~tedb/Journals/PNAS-2014-Bergstrom-1403006111.pdf
One thing I learned early in my career is that I am dealing with very smart people. In fact, they are the rocket scientists!
It is hard to dupe these folks because they are in the business of proving it.
I would bet that the niche players are on the fringe and will fall by the wayside when they don’t make any money just like the dot coms!
Are we talking here about a solution looking for a problem?
Also, who says there is a problem about IF aside from some disgruntled folks who just don’t seem to make the grade? I am not nor have I ever been employed by TR but have found that if they find someone playing the system that they quickly react to stop the play. In short, it seems a good measure. Can and should there be others? Of course, but those others should measure something that can be verified and not just eyeballs on a page!
One thing I learned early in my career is that I am dealing with very smart people. In fact, they are the rocket scientists! It is hard to dupe these folks because they are in the business of proving it.
Well, it’s probably hard to dupe them about rocket science, anyway. But publishing isn’t rocket science, and one thing I’ve learned in academia is that exceptional brilliance and a profound depth of knowledge in one’s chosen field do not necessarily translate into a profound knowledge of any other field. (Our assumption that they do is something I’ve come to think of as the Chomsky Effect.) So we need to be careful about assuming, just because a scholar or scientist is brilliant and knowledgeable, that he or she necessarily knows anything at all about how scholarly communication works. Sometimes they do, and sometimes they don’t.
Hi David, we just wrote the following reply to Phil Davis’s original post:
“Thanks, Phil, this is an important thing to clarify. We understand that people are going to have questions about any study we do that seems to validate our own product. That’s why we published our data and want to be as rigorous as possible. While a quick review suggests that nearly all of the sample consists of original research papers, we’re currently running an analysis to categorize all 44,689 papers and see if that has any effect on the models. Stay tuned for updates.”
Richard Price, CEO, Academia.edu